I rack di computer nel centro di calcolo del CERN sono solo una frazione dell'hardware necessario per archiviare ed elaborare i dati dall'LHC. Credito:Anthony Grossir/CERN
Alla fine del 2018, il Large Hadron Collider (LHC) ha completato la sua seconda corsa pluriennale ("Run 2") che ha visto la macchina raggiungere un'energia di collisione protone-protone di 13 TeV, il più alto mai raggiunto da un acceleratore di particelle. Durante questa corsa, dal 2015 al 2018, Gli esperimenti di LHC hanno prodotto volumi di dati senza precedenti con prestazioni della macchina superiori a tutte le aspettative.
Ciò significava un uso eccezionale dell'informatica, con molti record battuti in termini di acquisizione dati, velocità e volumi di dati. Il sistema di archiviazione avanzato del CERN (CASTOR), che si basa su un backend basato su nastro per l'archiviazione permanente dei dati, raggiunto 330 PB di dati (equivalenti a 330 milioni di gigabyte) archiviati su nastro, un equivalente di oltre 2000 anni di registrazione video HD 24/7. Solo nel novembre 2018 un record di 15,8 PB di dati sono stati registrati su nastro, un risultato notevole dato che corrisponde a più di quanto registrato durante il primo anno della Run 1 di LHC.
Il sistema di storage distribuito per gli esperimenti LHC ha superato i 200 PB di storage raw con circa 600 milioni di file. Questo sistema (EOS) è basato su disco e open-source, ed è stato sviluppato al CERN per i requisiti di calcolo estremi dell'LHC. Oltre a questo, 830 PB di dati e 1,1 miliardi di file sono stati trasferiti in tutto il mondo tramite il servizio di trasferimento file. Per affrontare queste sfide informatiche e supportare al meglio gli esperimenti del CERN durante il Run 2, l'intera infrastruttura informatica, e in particolare i sistemi di stoccaggio, ha subito importanti aggiornamenti e consolidamenti negli ultimi anni.
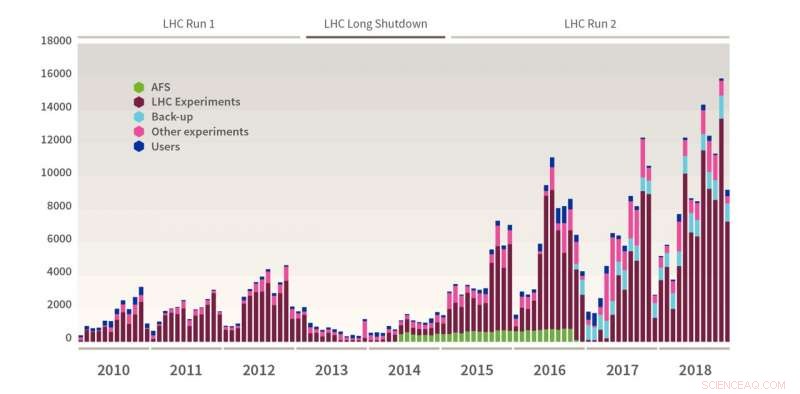
Dati (in terabyte) registrati su nastro al CERN mese per mese. Questo grafico mostra la quantità di dati registrati su nastro generati dagli esperimenti di LHC, altri esperimenti, vari backup e utenti. Nel 2018, oltre 115 PB di dati in totale (inclusi circa 88 PB di dati LHC) sono stati registrati su nastro, con un picco record di 15,8 PB a novembre. Credito:Esma Mobs/CERN
Sono già iniziate nuove attività di ricerca e sviluppo IT in preparazione della Run 3 di LHC (prevista per il 2021-2023). "Il nostro nuovo software, denominato CERN Tape Archive (CTA), è il nuovo sistema di archiviazione su nastro per la copia di custodia dei dati fisici e un sostituto per il suo predecessore, CASTORE. L'obiettivo principale di CTA è fare un uso più efficiente delle unità a nastro, per gestire la maggiore velocità di trasmissione dei dati prevista durante la corsa 3 e la 4 dell'LHC, " spiega German Cancio, chi guida il nastro, Sezione di archiviazione Archivi e backup nel dipartimento IT del CERN. CTA sarà schierato durante il secondo lungo arresto in corso dell'LHC (LS2), in sostituzione di CASTORE. Rispetto all'ultimo anno di Run 2, l'archiviazione dei dati dovrebbe essere due volte superiore durante la corsa 3 e cinque volte superiore o superiore durante la corsa 4 (prevista per il 2026-2029).
L'informatica di LHC continuerà ad evolversi. La maggior parte dei dati raccolti nel data center del CERN è di grande valore e deve essere preservata e archiviata per le future generazioni di fisici. Il dipartimento IT del CERN trarrà quindi vantaggio da LS2, l'attuale manutenzione e aggiornamento del complesso dell'acceleratore, per eseguire il necessario consolidamento dell'infrastruttura informatica. Aggiorneranno l'infrastruttura di storage e il software per affrontare le probabili sfide di scalabilità e prestazioni quando LHC si riavvierà nel 2021 per la Run 3.