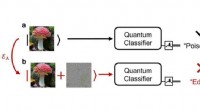
I ricercatori dell'UCLA hanno creato un sistema di visione artificiale a pixel singolo in grado di codificare le informazioni spaziali degli oggetti nello spettro della luce per classificare otticamente gli oggetti in ingresso e ricostruire le loro immagini utilizzando un rilevatore a pixel singolo. Credito:Ozcan Lab @ UCLA.
I sistemi di visione artificiale hanno molte applicazioni, comprese le auto a guida autonoma, produzione intelligente, chirurgia robotica e imaging biomedico, tra molti altri. La maggior parte di questi sistemi di visione artificiale utilizza telecamere basate su obiettivi, e dopo l'acquisizione di un'immagine o di un video, tipicamente con pochi megapixel per fotogramma, un processore digitale viene utilizzato per eseguire attività di apprendimento automatico, come la classificazione degli oggetti e la segmentazione della scena. Una tale architettura tradizionale di visione artificiale presenta diversi inconvenienti. Primo, la grande quantità di informazioni digitali rende difficile ottenere analisi di immagini/video ad alta velocità, soprattutto utilizzando dispositivi mobili e alimentati a batteria. Inoltre, le immagini catturate di solito contengono informazioni ridondanti, che sovraccarica il processore digitale con un elevato carico computazionale, creando inefficienze in termini di potenza e requisiti di memoria. Inoltre, oltre le lunghezze d'onda visibili della luce, fabbricazione di sensori di immagine ad alto numero di pixel, come quello che abbiamo nelle fotocamere dei nostri telefoni cellulari, è impegnativo e costoso, che limita le applicazioni dei metodi standard di visione artificiale a lunghezze d'onda maggiori, come terahertz parte dello spettro.
I ricercatori dell'UCLA hanno riportato un nuovo, framework di visione artificiale a pixel singolo che fornisce una soluzione per mitigare le carenze e le inefficienze dei tradizionali sistemi di visione artificiale. Hanno sfruttato l'apprendimento profondo per progettare reti ottiche create da successive superfici diffrattive per eseguire calcoli e inferenze statistiche mentre la luce in ingresso passa attraverso questi strati appositamente progettati e fabbricati in 3D. A differenza delle normali fotocamere con obiettivo, queste reti ottiche diffrattive sono progettate per elaborare la luce in ingresso a lunghezze d'onda selezionate con l'obiettivo di estrarre e codificare le caratteristiche spaziali di un oggetto in ingresso nello spettro della luce diffratta, che viene raccolto da un rilevatore a pixel singolo. Diversi tipi di oggetti o classi di dati sono assegnati a diverse lunghezze d'onda della luce. Gli oggetti in ingresso vengono classificati automaticamente otticamente, semplicemente utilizzando lo spettro di uscita rilevato da un singolo pixel, bypassando la necessità di un array di sensori di immagine o di un processore digitale. Questa capacità di inferenza completamente ottica e visione artificiale attraverso un rilevatore a pixel singolo accoppiato a una rete diffrattiva offre vantaggi trasformativi in termini di frame rate, fabbisogno di memoria ed efficienza energetica, che sono particolarmente importanti per le applicazioni di mobile computing.
In uno studio pubblicato su Progressi scientifici , I ricercatori dell'UCLA hanno dimostrato sperimentalmente il successo della loro struttura a lunghezze d'onda terahertz classificando le immagini delle cifre scritte a mano utilizzando un singolo rilevatore di pixel e strati diffrattivi stampati in 3D. La classificazione ottica degli oggetti in ingresso (cifre scritte a mano) è stata eseguita in base al segnale massimo tra le dieci lunghezze d'onda che erano, uno per uno, assegnato a diverse cifre scritte a mano (da 0 a 9). Nonostante l'utilizzo di un rilevatore a pixel singolo, è stata ottenuta una precisione di classificazione ottica superiore al 96%. Uno studio sperimentale di prova del concetto con strati diffrattivi stampati in 3D ha mostrato uno stretto accordo con le simulazioni numeriche, dimostrando l'efficacia del framework di visione artificiale a pixel singolo per la creazione di sistemi di apprendimento automatico a bassa latenza ed efficienti in termini di risorse. Oltre alla classificazione degli oggetti, i ricercatori hanno anche collegato la stessa rete ottica diffrattiva a pixel singolo con un semplice, rete neurale elettronica superficiale, ricostruire rapidamente le immagini degli oggetti in ingresso in base alla sola potenza rilevata a dieci distinte lunghezze d'onda, dimostrando la decompressione dell'immagine specifica per attività.
Questa struttura di classificazione di oggetti a pixel singolo e ricostruzione delle immagini potrebbe aprire la strada allo sviluppo di nuovi sistemi di visione artificiale che utilizzano la codifica spettrale delle informazioni sugli oggetti per ottenere uno specifico compito di inferenza in modo efficiente in termini di risorse, con bassa latenza, bassa potenza e basso numero di pixel. Questo nuovo quadro può essere esteso anche a vari sistemi di misurazione del dominio spettrale, come la tomografia a coerenza ottica, Spettroscopia a infrarossi e altri, per creare fondamentalmente nuove modalità di imaging e rilevamento 3D integrate con la codifica diffrattiva basata sulla rete di informazioni spettrali e spaziali.