Un milione di processi sono mappati ai pixel di uno schizzo in bianco e nero di 1000 × 1000 pixel di Alan Turing. I pixel si accendono e si spengono in base ai valori binari istantanei dei processi. Credito:Nature Communications
"In-memory computing" o "memoria computazionale" è un concetto emergente che utilizza le proprietà fisiche dei dispositivi di memoria sia per l'archiviazione che per l'elaborazione delle informazioni. Questo è in contrasto con gli attuali sistemi e dispositivi von Neumann, come computer desktop standard, laptop e persino cellulari, che trasportano i dati avanti e indietro tra la memoria e l'unità di calcolo, rendendoli così più lenti e meno efficienti dal punto di vista energetico.
Oggi, IBM Research annuncia che i suoi scienziati hanno dimostrato che un algoritmo di apprendimento automatico non supervisionato, in esecuzione su un milione di dispositivi di memoria a cambiamento di fase (PCM), ha trovato con successo correlazioni temporali in flussi di dati sconosciuti. Rispetto ai computer classici all'avanguardia, si prevede che questa tecnologia prototipo produrrà miglioramenti di 200 volte sia in termini di velocità che di efficienza energetica, rendendolo altamente adatto per consentire ultra-denso, a bassa potenza, e sistemi di calcolo massivamente paralleli per applicazioni nell'intelligenza artificiale.
I ricercatori hanno utilizzato dispositivi PCM realizzati con una lega di tellururo di antimonio germanio, che è impilato e inserito tra due elettrodi. Quando gli scienziati applicano una piccola corrente elettrica al materiale, lo scaldano, che altera il suo stato da amorfo (con disposizione atomica disordinata) a cristallino (con configurazione atomica ordinata). I ricercatori IBM hanno utilizzato le dinamiche di cristallizzazione per eseguire calcoli sul posto.
"Questo è un importante passo avanti nella nostra ricerca sulla fisica dell'IA, che esplora nuovi materiali hardware, dispositivi e architetture, " dice il dottor Evangelos Eleftheriou, un IBM Fellow e coautore del documento. "Poiché le leggi di scala del CMOS vengono meno a causa dei limiti tecnologici, è necessario un radicale allontanamento dalla dicotomia processore-memoria per aggirare i limiti dei computer di oggi. Data la semplicità, alta velocità e bassa energia del nostro approccio di elaborazione in memoria, è notevole che i nostri risultati siano così simili al nostro approccio classico di riferimento eseguito su un computer von Neumann".
I dettagli sono spiegati nel loro articolo apparso oggi sulla rivista peer-review Comunicazioni sulla natura . Per dimostrare la tecnologia, gli autori hanno scelto due esempi basati sul tempo e hanno confrontato i loro risultati con i tradizionali metodi di apprendimento automatico come il clustering k-means:
"Finora la memoria è stata vista come un luogo in cui memorizziamo semplicemente informazioni. Ma in questo lavoro, mostriamo in modo conclusivo come possiamo sfruttare la fisica di questi dispositivi di memoria per eseguire anche una primitiva computazionale di livello piuttosto elevato. Il risultato del calcolo è anche memorizzato nei dispositivi di memoria, e in questo senso il concetto è vagamente ispirato dal modo in cui il cervello calcola", ha affermato il dott. Abu Sebastian, scienziato della memoria esplorativa e delle tecnologie cognitive, IBM Research e autore principale del documento.
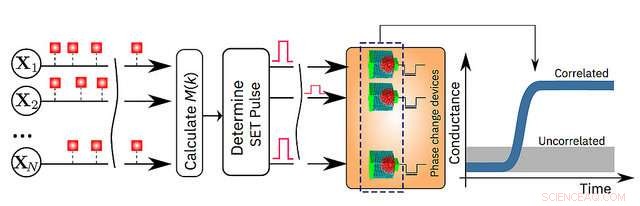
Un'illustrazione schematica dell'algoritmo di calcolo in memoria. Credito:IBM Research