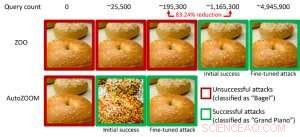
Figura 1:Confronto delle prestazioni nel trasformare un'immagine bagel in un'immagine bagel contraddittoria classificata come "pianoforte a coda" utilizzando gli attacchi ZOO e AutoZOOM. Credito:IBM
Studi recenti hanno identificato la mancanza di robustezza negli attuali modelli di intelligenza artificiale rispetto a esempi contraddittori:input di dati evasivi della previsione manipolati intenzionalmente che sono simili ai dati normali ma causeranno il comportamento anomalo di modelli di intelligenza artificiale ben addestrati. Ad esempio, perturbazioni visivamente impercettibili a un segnale di stop possono essere facilmente realizzate e condurre un modello di intelligenza artificiale ad alta precisione verso una classificazione errata. Nel nostro precedente articolo pubblicato alla European Conference on Computer Vision (ECCV) nel 2018, abbiamo convalidato che 18 diversi modelli di classificazione addestrati su ImageNet, un grande set di dati di riconoscimento di oggetti pubblici, sono tutti vulnerabili alle perturbazioni contraddittorie.
In particolare, esempi contraddittori sono spesso generati nell'impostazione "white-box", dove il modello di intelligenza artificiale è completamente trasparente per un avversario. Nello scenario pratico, quando si implementa un modello di intelligenza artificiale come servizio, come un'API di classificazione delle immagini online, si può erroneamente credere che sia robusto per gli esempi contraddittori a causa dell'accesso e della conoscenza limitati del modello di intelligenza artificiale sottostante (ovvero l'impostazione della "scatola nera"). Però, il nostro recente lavoro pubblicato all'AAAI 2019 mostra che la robustezza dovuta all'accesso limitato al modello non è fondata. Forniamo un quadro generale per la generazione di esempi contraddittori dal modello AI mirato utilizzando solo le risposte input-output del modello e poche query del modello. Rispetto al lavoro precedente (attacco ZOO), il nostro quadro proposto, chiamato ZOOM automatico, riduce in media almeno il 93% delle query del modello ottenendo prestazioni di attacco simili, fornire una metodologia efficiente in termini di query per valutare la solidità del contraddittorio dei sistemi di intelligenza artificiale con accesso limitato. Un esempio illustrativo è mostrato in Figura 1, dove un'immagine contraddittoria bagel generata da un classificatore di immagini black-box sarà classificata come bersaglio dell'attacco "pianoforte a coda". Questo articolo è selezionato per la presentazione orale (29 gennaio, 11:30-12:30 @ coral 1) e presentazione poster (29 gennaio, 18:30-20:30) presso AAAI 2019.
Nell'impostazione della scatola bianca, esempi contraddittori sono spesso realizzati sfruttando il gradiente di un obiettivo di attacco progettato rispetto all'input dei dati per la guida della perturbazione contraddittoria, che richiede la conoscenza dell'architettura del modello e dei pesi del modello per l'inferenza. Però, nell'impostazione della scatola nera l'acquisizione del gradiente non è fattibile a causa dell'accesso limitato a questi dettagli del modello. Anziché, un avversario può accedere solo alle risposte input-output del modello AI distribuito, proprio come gli utenti normali (ad es. caricare un'immagine e ricevere la previsione da un'API di classificazione delle immagini online). È stato mostrato per la prima volta nell'attacco ZOO che è possibile generare esempi contraddittori da modelli con accesso limitato utilizzando tecniche di stima del gradiente. Però, potrebbe essere necessaria un'enorme quantità di query di modello per creare un esempio contraddittorio. Per esempio, nella figura 1, L'attacco ZOO richiede più di 1 milione di query del modello per trovare l'immagine contraddittoria del bagel. Per accelerare l'efficienza della query nella ricerca di esempi contraddittori nell'impostazione della scatola nera, il nostro framework AutoZOOM proposto ha due nuovi elementi costitutivi:(i) una strategia di stima adattiva del gradiente casuale per bilanciare i conteggi delle query e la distorsione, e (ii) un codificatore automatico addestrato offline con dati non etichettati o un'operazione di ridimensionamento bilineare per l'accelerazione. Per (io), AutoZOOM dispone di uno stimatore di gradiente ottimizzato ed efficiente per le query, che ha uno schema adattivo che utilizza poche query per trovare la prima perturbazione contraddittoria riuscita e quindi utilizza più query per mettere a punto la distorsione e rendere l'esempio contraddittorio più realistico. Per (ii), come mostrato in Figura 2, AutoZOOM implementa una tecnica chiamata "riduzione delle dimensioni" per ridurre la complessità di trovare esempi contraddittori. La riduzione delle dimensioni può essere realizzata da un codificatore automatico offline per acquisire le caratteristiche dei dati o da un semplice ridimensionatore di immagini bilineare che non richiede alcun addestramento.
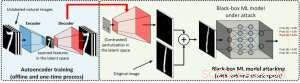
Figura 2:Illustrazione della tecnica di riduzione delle dimensioni utilizzata in AutoZOOM per il riscatto delle query. Il decodificatore può essere un codificatore automatico addestrato offline o un'operazione di ridimensionamento bilineare che non richiede alcun addestramento. Credito:IBM
Con queste due tecniche fondamentali, i nostri esperimenti su classificatori di immagini basati su reti neurali profonde black-box addestrati su MNIST, CIFAR-10 e ImageNet mostrano che AutoZOOM ottiene prestazioni di attacco simili ottenendo una riduzione significativa (almeno il 93%) del numero medio di query rispetto all'attacco ZOO. Su ImageNet, questa drastica riduzione significa milioni di query di modello in meno, rendendo AutoZOOM uno strumento efficiente e pratico per valutare la robustezza contraddittoria dei modelli di intelligenza artificiale con accesso limitato. Inoltre, AutoZOOM è un acceleratore di recupero query generale che può essere facilmente applicato a diversi metodi per generare esempi contraddittori nella pratica impostazione della scatola nera.
Il codice AutoZOOM è open source e può essere trovato qui. Consulta anche l'Adversarial Robustness Toolbox di IBM per ulteriori implementazioni sugli attacchi e le difese avversarie.
Questa storia è stata ripubblicata per gentile concessione di IBM Research. Leggi la storia originale qui.