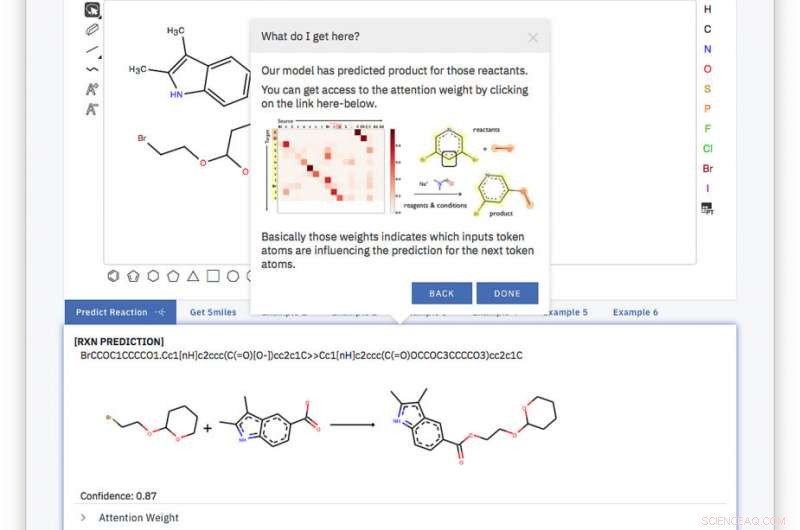
Lo strumento basato sul web è semplice, e il modello è addestrato end-to-end, completamente guidato dai dati e senza l'ausilio di query su un database o qualsiasi altra informazione esterna aggiuntiva. Credito:IBM
Da più di 200 anni, la sintesi di molecole organiche rimane uno dei compiti più importanti della chimica organica. Il lavoro dei chimici ha implicazioni scientifiche e commerciali che vanno dalla produzione dell'Aspirina a quella del Nylon. Ancora, poco è stato fatto per cambiare drasticamente le vecchie pratiche e consentire una nuova era di produttività basata sulla scienza e sulle tecnologie pionieristiche dell'intelligenza artificiale (AI).
La sfida per i chimici organici in campi come la chimica, scienza dei materiali, olio e gas, e le scienze della vita è che ci sono centinaia di migliaia di reazioni e, mentre è gestibile ricordarne qualche decina in un ristretto campo specialistico, è impossibile essere un esperto generalista.
Per affrontare questo ci siamo chiesti, possiamo usare il deep learning e l'intelligenza artificiale per prevedere le reazioni dei composti organici?
Primo, poiché abbiamo studiato ingegneria e scienze dei materiali, ma non chimica organica, abbiamo dovuto colpire i libri. Non passò molto tempo prima che iniziassimo a vedere la chimica organica ovunque:mattina, mezzogiorno e notte. Gli atomi apparvero al posto delle lettere, molecole materializzate da parole e, poi, è successo qualcosa di incredibile:è nata un'idea.
Ci siamo resi conto che i dataset di chimica organica e i dataset linguistici hanno molto in comune:entrambi dipendono dalla grammatica, su dipendenze a lungo raggio, e una piccola particella o una parola come "non" può cambiare l'intero significato di una frase proprio come la stereochimica può trasformare il talidomide in un farmaco o in un veleno mortale.
In quanto non madrelingua inglese, conosciamo entrambi gli strumenti di traduzione online, che facevano miracoli nel trasformare l'inglese in francese, e dal tedesco all'inglese, quindi perché non provare a usarli per trasformare sostanze chimiche casuali in composti funzionali?
Alla conferenza NIPS 2017 presentiamo i nostri risultati:un'app basata sul web che porta l'idea di mettere in relazione la chimica organica con un linguaggio e applica metodi di traduzione automatica neurale all'avanguardia per passare dalla progettazione di materiali alla generazione di prodotti utilizzando sequenze- modelli a sequenza (seq2seq).
Chimica 101
Tornato al liceo, abbiamo dovuto disegnare a mano gli esagoni ei pentagoni e tutte le varie linee che rappresentano i legami delle molecole organiche. Ora abbiamo creato un sistema che prende la stessa identica rappresentazione e può prevedere come reagiranno le molecole con un clic.
Lo strumento generale è semplice, e il modello è addestrato end-to-end, completamente guidato dai dati e senza l'ausilio di query su un database o qualsiasi altra informazione esterna aggiuntiva. Con questo approccio, superiamo le attuali soluzioni utilizzando i loro set di formazione e test raggiungendo un'accuratezza top-1 dell'80,3 percento e stabiliamo un primo punteggio del 65,4 percento su un set di dati sulle reazioni di un singolo prodotto rumoroso estratto da brevetti statunitensi.
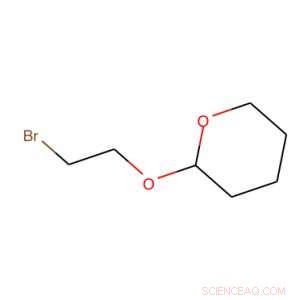
Usando SORRISI, questa molecola viene tradotta in BrCCOC1OCCCC1. Credito:IBM
Il segreto del nostro strumento è quello che viene chiamato un sistema di ingresso di linea a input molecolare semplificato o SMILES. SMILES rappresenta una molecola come una sequenza di caratteri. Ad esempio, l'immagine a destra, diventa BrCCOC1OCCCC1.
Abbiamo addestrato il nostro modello utilizzando un set di dati di reazione chimica apertamente disponibile, che corrispondono a 1 milione di reazioni brevettuali.
Nel futuro, miriamo a migliorare il modello e migliorare la nostra precisione espandendo il nostro set di dati. Attualmente i nostri dati sono presi da informazioni pubblicamente disponibili nei brevetti statunitensi pubblicati online, ma non c'è motivo per cui lo strumento non possa essere addestrato su dati provenienti da altre fonti, come libri di testo di chimica e pubblicazioni scientifiche.
Abbiamo inoltre in programma di rendere questo strumento pubblicamente disponibile gratuitamente sul cloud all'inizio del 2018.
Registrati su www.zurich.ibm.com/foundintranslation per ricevere un avviso quando lo strumento web è pronto.