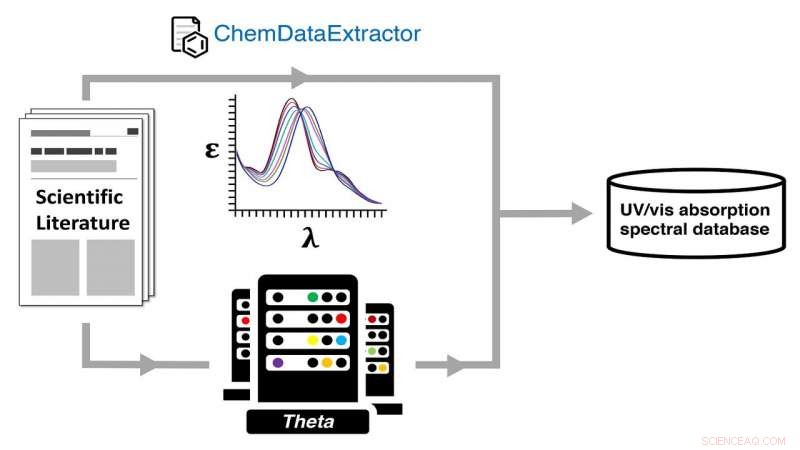
Generazione automatica di un database spettrale di assorbimento ultravioletto-visibile (UV-vis) tramite un doppio percorso di dati chimici sperimentali e computazionali utilizzando il supercomputer Theta dell'ALCF. Credito:Jacqueline Cole e Ulrich Mayer / Università di Cambridge
Una collaborazione tra l'Università di Cambridge e Argonne ha sviluppato una tecnica che genera database automatici per supportare campi scientifici specifici utilizzando l'intelligenza artificiale e il calcolo ad alte prestazioni.
La ricerca in risme di letteratura scientifica per bit e byte di informazioni per supportare un'idea o trovare la chiave per risolvere un problema specifico è stata a lungo una faccenda noiosa per i ricercatori, anche dopo gli albori della scoperta guidata dai dati.
Jacqueline Cole conosce il trapano, tutto troppo bene. Responsabile di Ingegneria Molecolare presso l'Università di Cambridge, Regno Unito, ha trascorso gran parte della sua carriera alla ricerca di materiali con proprietà ottiche che si prestassero a una raccolta della luce più efficiente, come molecole di colorante che un giorno potrebbero alimentare le finestre solari.
"Sapevo che molte delle informazioni erano contenute in una forma molto frammentata nella letteratura, " ricorda. "Ma se raccogliessi migliaia e migliaia di documenti, allora potresti creare il tuo database."
Quindi Cole e i colleghi di Cambridge e dell'Argonne National Laboratory del Dipartimento dell'Energia degli Stati Uniti (DOE) hanno fatto proprio questo, esponendo il processo nel giornale Dati scientifici .
La carta, dice Cole, è una descrizione di come costruire un database utilizzando l'elaborazione del linguaggio naturale (NLP) e il calcolo ad alte prestazioni, gran parte di questi ultimi eseguiti presso l'Argonne Leadership Computing Facility (ALCF), una struttura per gli utenti dell'Office of Science del DOE.
Tra i fattori che rendono unico il database vi sono la scala del progetto e il fatto che comprende sia dati sperimentali che calcolati su entrambe le strutture materiali, che descrive il fondamento atomico o chimico di una cosa, e proprietà dei materiali, la funzionalità fornita da queste diverse strutture.
"Probabilmente è la prima compilazione del genere di un database su così vasta scala, con 5, 380 coppie simili di dati sperimentali e calcolati, " dice Cole. "E poiché è una quantità così grande, funge da deposito a sé stante e apre davvero la porta alla previsione di nuovi materiali."
molti nuovi, grandi database sono costruiti esclusivamente su calcoli, uno svantaggio intrinseco è che non sono convalidati da dati sperimentali. Quest'ultimo, forse più significativo, fornisce un quadro accurato degli stati eccitati del materiale, che definiscono lo stato dinamico degli elettroni e sono utilizzati per calcolare le proprietà funzionali di un materiale:proprietà ottiche, in questo caso.
Questo catalogo in erba di stati eccitati può quindi aiutare a calcolare le proprietà dei materiali che devono ancora essere concepiti, ampliando ulteriormente il database.
"Immaginate di voler scoprire un nuovo tipo di materiale ottico adatto a un'applicazione funzionale su misura, e il nostro database non contiene quella particolare proprietà ottica, " spiega Cole. "Calcoliamo la proprietà ottica di interesse dagli stati eccitati che sono disponibili per ogni proprietà nel nostro database, e creare un materiale con funzioni su misura."
Il team ha eseguito calcoli di chimica quantistica su ciascuna struttura per la quale aveva estratto dati su materiali ottici, utilizzando il supercomputer Theta dell'ALCF, creando così il database delle strutture sperimentali e calcolate accoppiate e delle loro proprietà ottiche.
"Una delle maggiori sfide è stata l'estrazione di candidati chimici che potessero fungere da coloranti per le celle solari da 400, 000 articoli scientifici, " dice Álvaro Vázquez-Mayagoitia, uno scienziato computazionale nella divisione di Scienze computazionali di Argonne. "Abbiamo sviluppato un framework distribuito per applicare metodi di intelligenza artificiale, come quelli utilizzati nell'elaborazione del linguaggio naturale, sui supercomputer di classe mondiale dell'ALCF."
Per estrarre automaticamente tali informazioni e depositarle nel database, il team si è rivolto alla nuova applicazione di data mining chiamata ChemDataExtractor. Uno strumento di PNL, è stato progettato per estrarre il testo specificamente dall'interno della letteratura chimica e dei materiali, dove, Cole dice, "l'informazione è disseminata su molte migliaia di documenti ed è presente in forme altamente frammentate e non strutturate".
Non uno per le ricerche manuali di articoli, Cole descrive l'impulso a sviluppare l'applicazione come un'innovazione generata dalla frustrazione. Inizialmente, ha provato pacchetti di PNL più generici, ma ha osservato che "non solo falliscono, falliscono in modo spettacolare."
Il problema è nella traduzione, non tanto dal punto di vista del linguaggio umano, ma dal linguaggio della scienza, anche se ci sono alcune somiglianze.
Uno scrittore, Per esempio, potrebbe utilizzare un programma di riconoscimento vocale, una forma di PNL, per trascrivere appunti o interviste. Il programma si allena principalmente sulla voce dello scrittore, raccogliendo pattern e sfumature, e inizia a trascrivere in modo abbastanza accurato. Ora lancia un'intervista con un soggetto con un accento straniero e le cose iniziano a diventare traballanti.
Nel mondo di Cole, la lingua straniera è scienza, ogni dominio un paese diverso. Attualmente, devi addestrare il programma su una sola "lingua, "dico chimica, e anche allora, devi imparare i particolari dialetti di quella scienza.
I chimici inorganici potrebbero proporre una formula usando rappresentazioni non familiari dei ben noti simboli degli elementi chimici, mentre i chimici organici preferiscono schizzi chimici numerati all'interno di una scatola di illustrazione. Le informazioni provenienti da entrambi si rivelano in genere troppo difficili da estrarre per la maggior parte dei programmi di mining.
"E questo è solo un po' di chimica, " nota Cole. "Poiché il modo in cui le persone descrivono le cose è così vario, la diversità nella specificità del dominio è assolutamente critica".
A quello scopo, il database del team è uno degli attributi spettrali di assorbimento ultravioletto-visibile (UV/vis), che fornisce una risorsa apertamente disponibile per gli utenti che cercano di trovare materiali con colori spettrali preferiti.
Mentre il team sta utilizzando il nuovo database per scovare i coloranti organici che potrebbero sostituire i tradizionali coloranti metallo-organici nelle celle solari, hanno già preso di mira fronti più ampi per il suo utilizzo.
Utile come fonte di dati di addestramento per metodi di apprendimento automatico che prevedono nuovi materiali ottici, può anche rivelarsi una semplice opzione di recupero dati per gli utenti della spettroscopia di assorbimento UV/vis, uno strumento ampiamente utilizzato nei laboratori di ricerca di tutto il mondo come tecnica fondamentale per caratterizzare nuovi materiali.
"I protocolli utilizzati in questo progetto sono già in fase di implementazione per tipi simili di progetti, " aggiunge Vázquez-Mayagoitia. "Ad esempio, il team ha recentemente sfruttato le risorse informatiche di ChemDataExtractor e ALCF per produrre database estesi di potenziali prodotti chimici delle batterie, e composti magnetici e superconduttori."
La ricerca nel database dei materiali ottici appare nell'articolo "Set di dati comparativi degli attributi sperimentali e computazionali degli spettri di assorbimento UV/vis" in Dati scientifici. Altri autori includono Edward J. Beard dell'Università di Cambridge, e Ganesh Sivaraman e Venkatram Vishwanath dell'Argonne National Laboratory.
Un articolo che descrive in dettaglio il loro lavoro con materiali magnetici e superconduttori è stato pubblicato in npj Materiali di calcolo . Il database dei materiali delle batterie contenente oltre 290, 000 record di dati sono stati pubblicati in Dati scientifici .