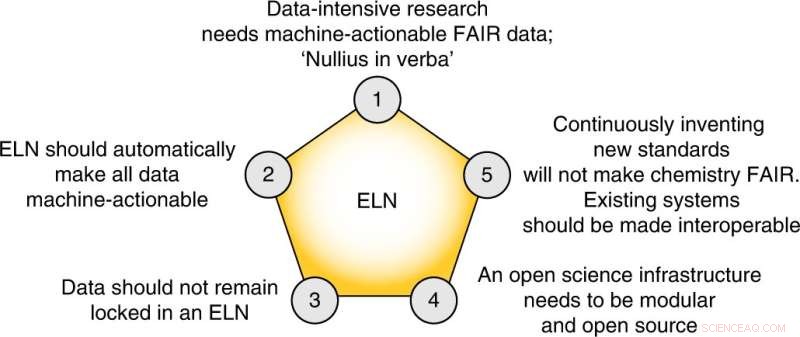
Le cinque tesi centrali di questa prospettiva. Credito:Chimica della natura (2022). DOI:10.1038/s41557-022-00910-7
Uno degli aspetti più impegnativi della chimica moderna è la gestione dei dati. Ad esempio, durante la sintesi di un nuovo composto, gli scienziati eseguiranno molteplici tentativi di tentativi ed errori per trovare le condizioni giuste per la reazione, generando nel processo enormi quantità di dati grezzi. Tali dati hanno un valore incredibile, poiché, come gli esseri umani, gli algoritmi di apprendimento automatico possono imparare molto da esperimenti falliti e parzialmente riusciti.
La pratica corrente, tuttavia, è quella di pubblicare solo gli esperimenti di maggior successo, poiché nessun essere umano può elaborare in modo significativo l'enorme numero di esperimenti falliti. Ma l'IA ha cambiato questo; è esattamente ciò che possono fare questi metodi di apprendimento automatico, a condizione che i dati siano archiviati in un formato utilizzabile dalla macchina per l'uso da parte di chiunque.
"Per molto tempo abbiamo dovuto comprimere le informazioni a causa del numero limitato di pagine negli articoli di riviste stampate", afferma il professor Berend Smit, che dirige il Laboratorio di simulazione molecolare presso l'EPFL Valais Wallis. "Al giorno d'oggi, molte riviste non hanno nemmeno più edizioni stampate; tuttavia, i chimici continuano a lottare con problemi di riproducibilità perché gli articoli delle riviste mancano di dettagli cruciali. I ricercatori 'perdono' tempo e risorse replicando esperimenti 'falliti' degli autori e lottano per costruire sopra risultati pubblicati poiché i dati grezzi vengono pubblicati raramente."
Ma il volume non è l'unico problema qui; un'altra è la diversità dei dati:i gruppi di ricerca utilizzano strumenti diversi come il software Electronic Lab Notebook, che memorizza i dati in formati proprietari a volte incompatibili tra loro. Questa mancanza di standardizzazione rende quasi impossibile per i gruppi condividere i dati.
Ora, Smit, con Luc Patiny e Kevin Jablonka all'EPFL, hanno pubblicato una prospettiva in Nature Chemistry presentare una piattaforma aperta per l'intero flusso di lavoro della chimica:dall'inizio di un progetto alla sua pubblicazione.
Gli scienziati immaginano che la piattaforma integri "perfettamente" tre fasi cruciali:raccolta dei dati, elaborazione dei dati e pubblicazione dei dati, il tutto con un costo minimo per i ricercatori. Il principio guida è che i dati dovrebbero essere FAIR:facilmente reperibili, accessibili, interoperabili e riutilizzabili. "Al momento della raccolta dei dati, i dati verranno automaticamente convertiti in un formato FAIR standard, consentendo di pubblicare automaticamente tutti gli esperimenti "falliti" e parzialmente riusciti insieme all'esperimento di maggior successo", afferma Smit.
Ma gli autori fanno un ulteriore passo avanti, proponendo che anche i dati dovrebbero essere utilizzabili dalle macchine. "Stiamo assistendo a un numero sempre maggiore di studi sulla scienza dei dati in chimica", afferma Jablonka. "In effetti, i recenti risultati dell'apprendimento automatico tentano di affrontare alcuni dei problemi che i chimici ritengono irrisolvibili. Ad esempio, il nostro gruppo ha compiuto enormi progressi nella previsione delle condizioni di reazione ottimali utilizzando modelli di apprendimento automatico. Ma quei modelli sarebbero molto più preziosi se potrebbero anche apprendere condizioni di reazione che falliscono, ma per il resto rimangono distorte perché vengono pubblicate solo le condizioni di successo."
Infine, gli autori propongono cinque passi concreti che il settore deve intraprendere per creare un piano di gestione dei dati FAIR:
"Pensiamo che non sia necessario inventare nuovi formati di file o tecnologie", afferma Patiny. "In linea di principio, tutta la tecnologia è disponibile e dobbiamo abbracciare le tecnologie esistenti e renderle interoperabili."
Gli autori sottolineano inoltre che la semplice memorizzazione dei dati in qualsiasi quaderno di laboratorio elettronico, la tendenza attuale, non significa necessariamente che gli esseri umani e le macchine possano riutilizzare i dati. Piuttosto, i dati devono essere strutturati e pubblicati in un formato standardizzato e devono anche contenere un contesto sufficiente per consentire azioni basate sui dati.
"La nostra prospettiva offre una visione di quelli che riteniamo siano i componenti chiave per colmare il divario tra dati e apprendimento automatico per i problemi fondamentali della chimica", afferma Smit. "Forniamo anche una soluzione scientifica aperta in cui l'EPFL può assumere un ruolo guida". + Esplora ulteriormente