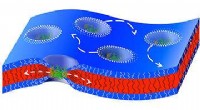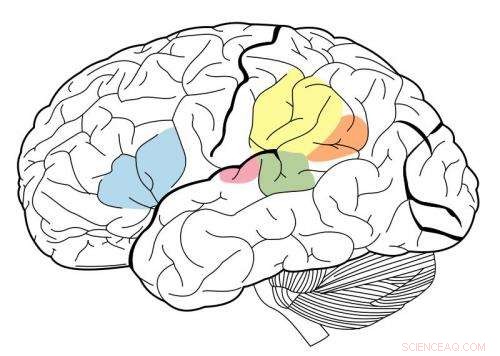
La corteccia uditiva primaria è evidenziata in magenta, ed è noto per interagire con tutte le aree evidenziate su questa mappa neurale. Credito:Wikipedia.
Utilizzando un sistema di apprendimento automatico noto come rete neurale profonda, I ricercatori del MIT hanno creato il primo modello in grado di replicare le prestazioni umane su compiti uditivi come l'identificazione di un genere musicale.
Questo modello, che consiste in molti livelli di unità di elaborazione delle informazioni che possono essere addestrate su enormi volumi di dati per eseguire compiti specifici, è stato utilizzato dai ricercatori per far luce su come il cervello umano potrebbe svolgere gli stessi compiti.
"Quello che questi modelli ci danno, per la prima volta, sono sistemi di macchine in grado di svolgere compiti sensoriali importanti per gli esseri umani e che lo fanno a livelli umani, "dice Josh McDermott, il Frederick A. e Carole J. Middleton Assistant Professor of Neuroscience presso il Dipartimento di Brain and Cognitive Sciences del MIT e l'autore senior dello studio. "Storicamente, questo tipo di elaborazione sensoriale è stato difficile da capire, in parte perché non abbiamo avuto una base teorica molto chiara e un buon modo per sviluppare modelli di ciò che potrebbe accadere".
Lo studio, che appare nel numero del 19 aprile di Neurone , offre anche la prova che la corteccia uditiva umana è organizzata in un'organizzazione gerarchica, molto simile alla corteccia visiva. In questo tipo di disposizione, l'informazione sensoriale passa attraverso fasi successive di elaborazione, con informazioni di base elaborate in precedenza e funzionalità più avanzate come il significato delle parole estratte in fasi successive.
Lo studente laureato del MIT Alexander Kell e l'assistente professore della Stanford University Daniel Yamins sono gli autori principali dell'articolo. Altri autori sono l'ex studentessa in visita al MIT Erica Shook e l'ex postdoc del MIT Sam Norman-Haignere.
Modellare il cervello
Quando le reti neurali profonde furono sviluppate per la prima volta negli anni '80, i neuroscienziati speravano che tali sistemi potessero essere usati per modellare il cervello umano. Però, i computer di quell'epoca non erano abbastanza potenti per costruire modelli sufficientemente grandi per eseguire attività del mondo reale come il riconoscimento di oggetti o il riconoscimento vocale.
Negli ultimi cinque anni, i progressi nella potenza di calcolo e nella tecnologia delle reti neurali hanno reso possibile utilizzare le reti neurali per eseguire difficili compiti del mondo reale, e sono diventati l'approccio standard in molte applicazioni ingegneristiche. In parallelo, alcuni neuroscienziati hanno rivisitato la possibilità che questi sistemi possano essere usati per modellare il cervello umano.
"È stata un'opportunità entusiasmante per le neuroscienze, in quanto possiamo effettivamente creare sistemi che possono fare alcune delle cose che le persone possono fare, e possiamo quindi interrogare i modelli e confrontarli con il cervello, " dice Kell.
I ricercatori del MIT hanno addestrato la loro rete neurale per eseguire due compiti uditivi, uno che coinvolge il discorso e l'altro che coinvolge la musica. Per il compito del discorso, i ricercatori hanno fornito al modello migliaia di registrazioni di due secondi di una persona che parla. Il compito era identificare la parola nel mezzo della clip. Per il compito di musica, al modello è stato chiesto di identificare il genere di un clip musicale di due secondi. Ogni clip includeva anche un rumore di fondo per rendere il compito più realistico (e più difficile).
Dopo molte migliaia di esempi, il modello ha imparato a svolgere il compito con la stessa precisione di un ascoltatore umano.
"L'idea è che nel tempo il modello migliori sempre di più nel compito, " dice Kell. "La speranza è che stia imparando qualcosa di generale, quindi se presenti un nuovo suono che il modello non ha mai sentito prima, andrà bene, e in pratica spesso è così."
Il modello tendeva anche a commettere errori sulle stesse clip su cui gli umani commettevano la maggior parte degli errori.
Le unità di elaborazione che compongono una rete neurale possono essere combinate in vari modi, formando diverse architetture che influenzano le prestazioni del modello.
Il team del MIT ha scoperto che il miglior modello per questi due compiti era quello che divideva l'elaborazione in due serie di fasi. La prima serie di fasi è stata condivisa tra compiti, ma dopo, si è diviso in due rami per ulteriori analisi:un ramo per il compito vocale, e uno per il compito del genere musicale.
Prove per la gerarchia
I ricercatori hanno quindi utilizzato il loro modello per esplorare una domanda di vecchia data sulla struttura della corteccia uditiva:se è organizzata gerarchicamente.
In un sistema gerarchico, una serie di regioni del cervello esegue diversi tipi di calcolo sulle informazioni sensoriali mentre fluiscono attraverso il sistema. È stato ben documentato che la corteccia visiva ha questo tipo di organizzazione. Regioni precedenti, nota come corteccia visiva primaria, rispondono a funzioni semplici come il colore o l'orientamento. Le fasi successive consentono attività più complesse come il riconoscimento di oggetti.
Però, è stato difficile verificare se questo tipo di organizzazione esiste anche nella corteccia uditiva, in parte perché non ci sono stati buoni modelli in grado di replicare il comportamento uditivo umano.
"Abbiamo pensato che se potessimo costruire un modello in grado di fare alcune delle stesse cose che fanno le persone, potremmo quindi essere in grado di confrontare diverse fasi del modello con diverse parti del cervello e ottenere alcune prove per dimostrare se quelle parti del cervello potrebbero essere organizzate gerarchicamente, "dice McDermott.
I ricercatori hanno scoperto che nel loro modello, le caratteristiche di base del suono come la frequenza sono più facili da estrarre nelle prime fasi. Man mano che le informazioni vengono elaborate e si spostano più lontano lungo la rete, diventa più difficile estrarre la frequenza ma più facile estrarre informazioni di livello superiore come le parole.
Per vedere se le fasi del modello potrebbero replicare il modo in cui la corteccia uditiva umana elabora le informazioni sonore, i ricercatori hanno utilizzato la risonanza magnetica funzionale (fMRI) per misurare diverse regioni della corteccia uditiva mentre il cervello elabora i suoni del mondo reale. Hanno quindi confrontato le risposte del cervello con le risposte nel modello quando ha elaborato gli stessi suoni.
Hanno scoperto che le fasi intermedie del modello corrispondevano meglio all'attività nella corteccia uditiva primaria, e gli stadi successivi corrispondevano meglio all'attività al di fuori della corteccia primaria. Ciò fornisce la prova che la corteccia uditiva potrebbe essere organizzata in modo gerarchico, simile alla corteccia visiva, dicono i ricercatori.
"Ciò che vediamo molto chiaramente è una distinzione tra la corteccia uditiva primaria e tutto il resto, "dice McDermott.
Gli autori hanno ora in programma di sviluppare modelli in grado di eseguire altri tipi di attività uditive, come determinare la posizione da cui proviene un particolare suono, per esplorare se questi compiti possono essere svolti dai percorsi identificati in questo modello o se richiedono percorsi separati, che potrebbe poi essere indagato nel cervello.