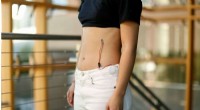
Immagini mascherate e corrispondenti risultati non dipinti utilizzando la nostra rete basata su parziali convoluzioni. Attestazione:arXiv:1804.07723 [cs.CV]
Per chi non ha ancora familiarità con gli strumenti di ricostruzione fotografica, il titolo di questo articolo su arXiv potrebbe essere totalmente sconcertante:"Image Inpainting per fori irregolari usando convoluzioni parziali". La ricerca, anche se, da un team NVIDIA, indica la strada per entusiasmanti miglioramenti in serbo per coloro che devono eseguire l'editing delle immagini e che desiderano buoni risultati.
Il ripristino dell'immagine consiste nel riempire i buchi in un'immagine. Può essere utilizzato per eliminare il contenuto dell'immagine che non è desiderato, riempiendo lo spazio con immagini plausibili. Tornando al titolo del loro articolo, il team ha esplorato la propria opinione su un processo migliorato, che potrebbe essere implementato nel software di fotoritocco.
Al NVIDIA Developer News Center c'è una panoramica sulla loro ricerca. Hanno escogitato un metodo che serve per (1) modificare le immagini o (2) ricostruire un'immagine corrotta, uno che ha buchi o manca di pixel. E quando hanno detto "modifica, " che include la rimozione del contenuto e il riempimento dei buchi.
Il video mostra chiaramente quanto interessante possa diventare, presentando set di foto prima e dopo l'inizio del processo di sbiancamento. Le scene per una sono una roccia all'aperto e un'altra è una biblioteca all'interno. Ancora un altro set mostra i volti degli umani, compresa una donna, giovani maschi e un uomo anziano.
Qual è il loro lavoro?
"Ricercatori di NVIDIA, guidato da Guilin Liu, ha introdotto un metodo di apprendimento profondo all'avanguardia in grado di modificare le immagini o ricostruire un'immagine corrotta, uno che ha buchi o manca di pixel. Il metodo può essere utilizzato anche per modificare le immagini rimuovendo il contenuto e riempiendo i buchi risultanti." Questo secondo le note video.
In gioco c'erano due fasi, la fase di formazione e la fase di test.
Per prepararsi ad addestrare la loro rete neurale, il team ha prima generato maschere di striature e fori casuali di forme e dimensioni arbitrarie per l'allenamento, ha detto il rapporto del centro di notizie. Le categorie sono state ideate in base alle dimensioni relative all'immagine in ingresso, per migliorare la precisione della ricostruzione. L'addestramento della rete neurale ha coinvolto le maschere generate in immagini da ImageNet, Set di dati Places2 e CelebA-HQ.
"Durante la fase di formazione, i fori o le parti mancanti vengono introdotti in immagini di addestramento complete dai set di dati di cui sopra, per consentire alla rete di imparare a ricostruire i pixel mancanti. Durante la fase di test, fori diversi o parti mancanti, non applicato durante la formazione, vengono introdotti nelle immagini di prova nel set di dati, per eseguire una validazione imparziale dell'accuratezza della ricostruzione."
Perché il loro lavoro si distingue:"Per quanto a nostra conoscenza, siamo i primi a dimostrare l'efficacia dell'apprendimento profondo dell'immagine nella pittura di modelli su fori di forma irregolare."
I ricercatori erano a conoscenza dei metodi esistenti di reinterpretazione delle immagini basati sull'apprendimento profondo. Questi stavano usando "una rete convoluzionale standard sull'immagine corrotta, utilizzando le risposte del filtro convoluzionale condizionate sia ai pixel validi che ai valori sostitutivi nei fori mascherati (in genere il valore medio). "Hanno detto che questo "spesso porta ad artefatti come discrepanza di colore e sfocatura. La post-elaborazione viene solitamente utilizzata per ridurre tali artefatti, ma sono costosi e possono fallire."
Hanno detto che stavano proponendo convoluzioni parziali, in quanto "la convoluzione è mascherata e rinormalizzata per essere condizionata solo da pixel validi".
Hanno mostrato confronti qualitativi e quantitativi con altri metodi per convalidare il loro approccio, e hanno affermato che il loro modello "supera altri metodi per maschere irregolari".
Gli autori del documento sono Guilin Liu, Fitsum Reda, Kevin Shih, Ting Chun Wang, Andrew Tao e Bryan Catanzaro.
© 2018 Tech Xplore