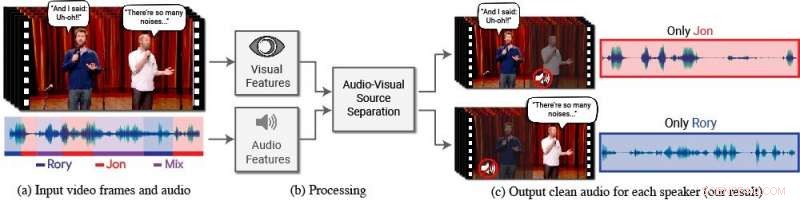
Un nuovo modello isola e migliora il discorso degli oratori desiderati in un video. (a) L'input è un video (frame + traccia audio) con una o più persone che parlano, dove il discorso di interesse è disturbato da altri oratori e/o da rumori di sottofondo. (b) Sia le caratteristiche audio che quelle visive vengono estratte e inserite in un modello congiunto di separazione del parlato audiovisivo. (c) L'output è una scomposizione della traccia audio in ingresso in tracce vocali pulite, uno per ogni persona rilevata nel video. Il discorso di persone specifiche è migliorato nei video mentre tutti gli altri suoni sono soppressi. Il nuovo modello è stato addestrato utilizzando migliaia di ore di segmenti video dal nuovo set di dati del team, AVSpeech, che sarà rilasciato pubblicamente. Credito:Autori/Google Video stills:Courtesy of Team Coco/CONAN
Le persone hanno un talento naturale per concentrarsi su ciò che una singola persona sta dicendo, anche quando ci sono conversazioni in competizione in sottofondo o altri suoni che distraggono. Ad esempio, le persone spesso riescono a capire cosa viene detto da qualcuno in un ristorante affollato, durante una festa rumorosa, o durante la visualizzazione di dibattiti televisivi in cui più esperti parlano l'uno sull'altro. Ad oggi, essere in grado di imitare computazionalmente e accuratamente questa capacità umana naturale di isolare il discorso è stato un compito difficile.
"I computer stanno diventando sempre più bravi a comprendere il parlato, ma hanno ancora notevoli difficoltà a comprendere il parlato quando più persone parlano insieme o quando c'è molto rumore, "dice Ariel Ephrat, un dottorato di ricerca candidato all'Università Ebraica di Gerusalemme-Israele e autore principale della ricerca. (Ephrat ha sviluppato il nuovo modello durante il tirocinio presso Google nell'estate del 2017.) "Noi umani sappiamo come comprendere il parlato in tali condizioni in modo naturale, ma vogliamo che i computer siano in grado di farlo bene quanto noi, forse anche meglio."
A tal fine, Ephrat e i suoi colleghi di Google hanno sviluppato un nuovo modello audiovisivo per isolare e migliorare il discorso degli oratori desiderati in un video. Il profondo modello basato sulla rete del team incorpora segnali sia visivi che uditivi al fine di isolare e migliorare qualsiasi oratore in qualsiasi video, anche in scenari difficili del mondo reale, come videoconferenze, dove più partecipanti spesso parlano contemporaneamente, e bar rumorosi, che potrebbe contenere una varietà di rumori di fondo, musica, e conversazioni in competizione.
Il gruppo, che include Inbar Mosseri di Google, Oran Lang, Tali Dekel, Kevin Wilson, Avinatan Hassidim, William T. Freeman, e Michael Rubinstein, presenteranno il loro lavoro al SIGGRAPH 2018, tenutosi dal 12 al 16 agosto a Vancouver, British Columbia. La conferenza e la mostra annuale mettono in mostra i principali professionisti del mondo, accademici, e menti creative all'avanguardia nella computer grafica e nelle tecniche interattive.
In questo lavoro, i ricercatori non si sono concentrati solo su segnali uditivi per separare il discorso, ma anche su segnali visivi nel video, ad es. i movimenti delle labbra del soggetto e potenzialmente altri movimenti facciali che possono prestare attenzione a ciò che sta dicendo. Le caratteristiche visive raccolte vengono utilizzate per "concentrare" l'audio su un singolo soggetto che sta parlando e per migliorare la qualità della separazione del parlato.
Per formare il loro modello audiovisivo congiunto, Ephrat e collaboratori hanno curato un nuovo set di dati, "AVDiscorso, " composto da migliaia di video di YouTube e altri segmenti di video online, come TED Talks, video di istruzioni, e lezioni di alta qualità. Da AVSpeech, i ricercatori hanno generato un set di formazione dei cosiddetti "cocktail sintetici":miscele di video di volti con un discorso pulito e altre tracce audio del parlato con rumore di fondo. Per isolare il parlato da questi video, all'utente è richiesto solo di specificare il volto della persona nel video di cui si vuole evidenziare l'audio.
In più esempi dettagliati nel documento, intitolato "Cercando di ascoltare il cocktail party:un modello audio-visivo indipendente dall'altoparlante per la separazione del parlato, " il nuovo metodo ha dato risultati superiori rispetto ai metodi esistenti solo audio su miscele vocali pure, e miglioramenti significativi nella fornitura di audio chiaro da miscele contenenti parlato sovrapposto e rumore di fondo in scenari del mondo reale. Mentre il focus del lavoro è la separazione e il miglioramento del discorso, il nuovo metodo del team potrebbe essere applicato anche al riconoscimento vocale automatico (ASR) e alla trascrizione video, ovvero funzionalità di sottotitoli su video in streaming e TV. In una manifestazione, il nuovo modello audiovisivo congiunto ha prodotto didascalie più accurate in scenari in cui erano coinvolti due o più relatori.
Sorpreso all'inizio da come funzionava bene il loro metodo, i ricercatori sono entusiasti del suo potenziale futuro.
"Non abbiamo mai visto la separazione vocale eseguita 'in the wild' con una tale qualità prima d'ora. Ecco perché vediamo un futuro entusiasmante per questa tecnologia, " fa notare Ephrat. "C'è bisogno di più lavoro prima che questa tecnologia arrivi nelle mani dei consumatori, ma con i promettenti risultati preliminari che abbiamo mostrato, possiamo certamente vederlo supportare una gamma di applicazioni in futuro, come i sottotitoli dei video, videoconferenze, e persino migliori apparecchi acustici se tali dispositivi potessero essere combinati con le fotocamere".
I ricercatori stanno attualmente esplorando opportunità per incorporarlo in vari prodotti Google.