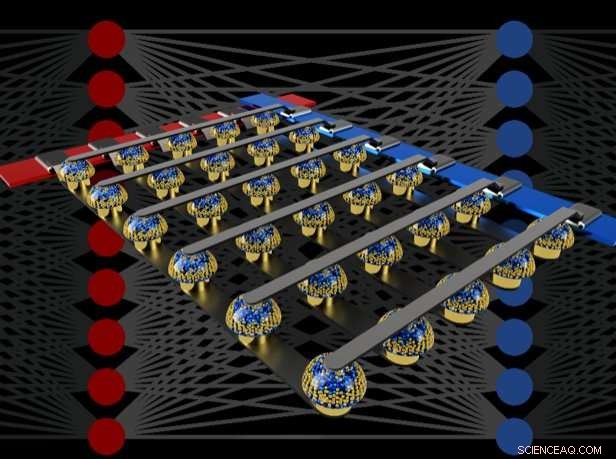
Gli array trasversali di memorie non volatili possono accelerare l'addestramento di reti neurali completamente connesse eseguendo calcoli nella posizione dei dati. Credito:IBM
Immagina l'intelligenza artificiale personalizzata (AI), dove il tuo smartphone diventa più come un assistente intelligente - riconoscendo la tua voce anche in una stanza rumorosa, comprendere il contesto di diverse situazioni sociali o presentare solo le informazioni che sono veramente rilevanti per te, strappato dalla marea di dati che arriva ogni giorno. Tali capacità potrebbero presto essere alla nostra portata, ma per arrivarci sarà necessario un rapido, potente, acceleratori hardware IA ad alta efficienza energetica.
In un recente articolo pubblicato su Natura , il nostro team IBM Research AI ha dimostrato l'addestramento alla rete neurale profonda (DNN) con grandi array di dispositivi di memoria analogici con la stessa precisione di un sistema basato su GPU (Graphical Processing Unit). Riteniamo che questo sia un passo importante nel percorso verso il tipo di acceleratori hardware necessari per le prossime scoperte dell'IA. Come mai? Perché per realizzare il futuro dell'IA sarà necessario espandere notevolmente la scala dei calcoli dell'IA.
I DNN devono diventare più grandi e più veloci, sia nel cloud che all'edge – e questo significa che l'efficienza energetica deve migliorare notevolmente. Mentre GPU migliori o altri acceleratori digitali possono aiutare in una certa misura, tali sistemi inevitabilmente impiegano molto tempo ed energia per spostare i dati dalla memoria all'elaborazione e viceversa. Possiamo migliorare sia la velocità che l'efficienza energetica eseguendo calcoli di intelligenza artificiale nel dominio analogico direttamente nella posizione dei dati, ma questo ha senso farlo solo se le reti neurali risultanti sono intelligenti quanto quelle implementate con l'hardware digitale convenzionale.
Tecniche analogiche, coinvolgendo segnali continuamente variabili piuttosto che 0 e 1 binari, hanno limiti intrinseci alla loro precisione, motivo per cui i computer moderni sono generalmente computer digitali. Però, I ricercatori di intelligenza artificiale hanno iniziato a rendersi conto che i loro modelli DNN funzionano ancora bene anche quando la precisione digitale è ridotta a livelli che sarebbero troppo bassi per quasi tutte le altre applicazioni informatiche. Così, per i DNN, è possibile che anche il calcolo analogico possa funzionare.
Però, fino ad ora, nessuno aveva dimostrato in modo conclusivo che tali approcci analogici potessero svolgere lo stesso lavoro del software odierno eseguito su hardware digitale convenzionale. Questo è, i DNN possono davvero essere addestrati a un'accuratezza equivalentemente elevata con queste tecniche? Non ha molto senso essere più veloci o più efficienti dal punto di vista energetico nell'addestramento di un DNN se l'accuratezza della classificazione risultante sarà sempre inaccettabilmente bassa.
Nel nostro giornale, descriviamo come le memorie analogiche non volatili (NVM) possono accelerare in modo efficiente l'algoritmo di "backpropagation" al centro di molti recenti progressi dell'IA. Queste memorie consentono di parallelizzare le operazioni di "moltiplicazione-accumulazione" utilizzate in questi algoritmi nel dominio analogico, nella posizione dei dati di peso, usando la fisica sottostante. Invece di grandi circuiti per moltiplicare e sommare numeri digitali, passiamo semplicemente una piccola corrente attraverso un resistore in un filo, e quindi collegare molti di questi fili insieme per consentire alle correnti di accumularsi. Questo ci permette di eseguire molti calcoli contemporaneamente, piuttosto che uno dopo l'altro. E invece di spedire dati digitali in lunghi viaggi tra chip di memoria digitali e chip di elaborazione, possiamo eseguire tutti i calcoli all'interno del chip di memoria analogico.
Però, a causa di varie imperfezioni inerenti ai dispositivi di memoria analogici odierni, le precedenti dimostrazioni di formazione DNN eseguite direttamente su grandi array di dispositivi NVM reali non sono riuscite a raggiungere una precisione di classificazione che corrispondesse a quella delle reti addestrate tramite software.
Combinando l'archiviazione a lungo termine in dispositivi di memoria a cambiamento di fase (PCM), aggiornamento quasi lineare dei convenzionali condensatori CMOS (Complementary Metal-Oxide Semiconductor) e nuove tecniche per annullare la variabilità da dispositivo a dispositivo, abbiamo perfezionato queste imperfezioni e ottenuto precisioni DNN equivalenti al software su una varietà di reti diverse. Questi esperimenti hanno utilizzato un approccio misto hardware-software, combinando simulazioni software di elementi di sistema facili da modellare accuratamente (come i dispositivi CMOS) insieme all'implementazione hardware completa dei dispositivi PCM. Era essenziale utilizzare dispositivi di memoria analogici reali per ogni peso nelle nostre reti neurali, perché gli approcci di modellazione per tali nuovi dispositivi spesso non riescono a catturare l'intera gamma di variabilità da dispositivo a dispositivo che possono esibire.
Utilizzando questo approccio, abbiamo verificato che i chip completi dovrebbero effettivamente offrire una precisione equivalente, e quindi svolgere lo stesso lavoro di un acceleratore digitale, ma più veloce e con una potenza inferiore. Alla luce di questi incoraggianti risultati, abbiamo già iniziato a esplorare la progettazione di prototipi di chip acceleratori hardware, come parte di un progetto dell'IBM Research Frontiers Institute.
Da questi primi sforzi di progettazione siamo stati in grado di fornire, come parte della nostra carta Natura, stime iniziali per il potenziale di tali chip basati su NVM per l'addestramento di livelli completamente connessi, in termini di efficienza energetica computazionale (28, 065 GOP/sec/W) e resa per area (3,6 TOP/sec/mm2). Questi valori superano di due ordini di grandezza le specifiche delle GPU odierne. Per di più, i livelli completamente connessi sono un tipo di livello di rete neurale per il quale le prestazioni effettive della GPU spesso scendono ben al di sotto delle specifiche nominali.
Questo documento indica che il nostro approccio basato su NVM può fornire precisioni di addestramento equivalenti al software, nonché miglioramenti di ordini di grandezza nell'accelerazione e nell'efficienza energetica nonostante le imperfezioni dei dispositivi di memoria analogici esistenti. I prossimi passi saranno dimostrare questa stessa equivalenza software su reti più grandi che richiedono grandi, livelli completamente connessi, come le reti LSTM (Long Short Term Memory) e GRU (Gated Recurrent Unit) connesse in modo ricorrente dietro i recenti progressi nella traduzione automatica, sottotitoli e analisi del testo – e per progettare, implementare e perfezionare queste tecniche analogiche su prototipi di acceleratori hardware basati su NVM. Nuove e migliori forme di memoria analogica, ottimizzato per questa applicazione, potrebbe contribuire a migliorare ulteriormente sia la densità dell'area che l'efficienza energetica.