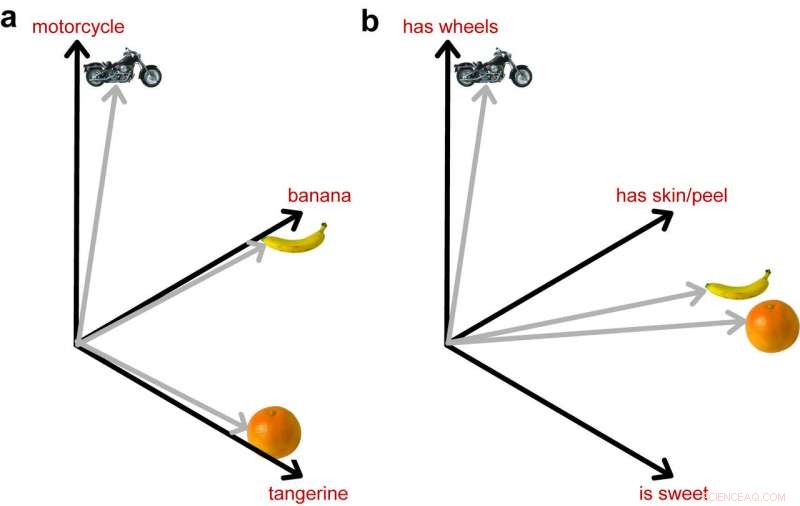
L'immagine a sinistra mostra come i DNN addestrati a identificare gli oggetti rappresentino queste 3 immagini come ugualmente diverse. L'immagine a destra mostra l'importante ruolo svolto dall'informazione semantica avvicinando i due frutti nello spazio, poiché sono più vicini nel loro significato. Credito:Lorraine Tyler et al.
I ricercatori di neuroscienze dell'Università di Cambridge hanno combinato la visione artificiale con la semantica, sviluppando un nuovo modello che potrebbe aiutare a capire meglio come gli oggetti vengono elaborati nel cervello.
La capacità umana di riconoscere gli oggetti coinvolge due processi principali, una rapida analisi visiva dell'oggetto e l'attivazione della conoscenza semantica acquisita nel corso della vita. La maggior parte degli studi precedenti ha studiato questi due processi separatamente; perciò, la loro interazione rimane in gran parte poco chiara.
Il team di ricercatori di Cambridge ha studiato i processi di riconoscimento degli oggetti utilizzando un nuovo metodo che combina reti neurali profonde con un modello semantico di rete di attrattori. In contrasto con la maggior parte degli studi precedenti, la loro tecnica tiene conto sia delle informazioni visive che della conoscenza concettuale sugli oggetti.
"In precedenza avevamo svolto molte ricerche con persone sane e pazienti con danni cerebrali per capire meglio come gli oggetti vengono elaborati nel cervello, " hanno detto i ricercatori di Cambridge Tech Xplore . "Uno dei maggiori contributi di questo lavoro è dimostrare che la comprensione di cosa sia un oggetto implica che l'input visivo si trasformi rapidamente nel tempo in una rappresentazione significativa, e questo processo di trasformazione si compie lungo la lunghezza del lobo temporale ventrale."
I ricercatori credono fermamente che l'accesso alla memoria semantica sia una parte fondamentale per capire cos'è un oggetto, quindi le teorie che si concentrano solo sulle proprietà relative alla visione non catturano completamente questo processo complesso.
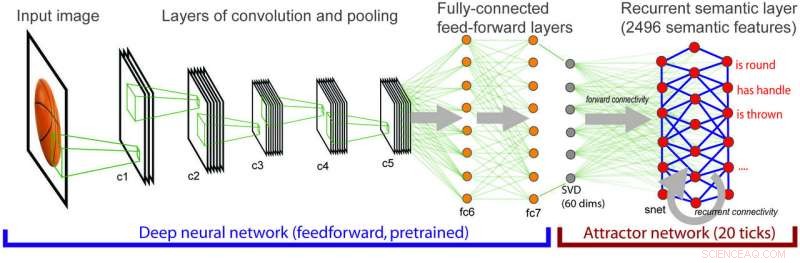
Architettura del modello integrato dove informazioni visive sempre più complesse si mappano su informazioni semantiche. Credito:Lorraine Tyler et al.
"Questo è stato l'innesco iniziale per la ricerca attuale, dove volevamo comprendere appieno come gli input visivi di basso livello sono mappati su una rappresentazione semantica del significato dell'oggetto, " hanno spiegato i ricercatori. Per fare questo, hanno usato una rete neurale profonda standard specializzata nella visione artificiale, chiamato AlexNet.
"Questo modello, e ad altri piace, può identificare gli oggetti nelle immagini con una precisione molto elevata, ma non includono alcuna conoscenza esplicita sulle proprietà semantiche degli oggetti, " hanno spiegato. "Per esempio, banane e kiwi hanno un aspetto molto diverso (colore diverso, forma, struttura, ecc) ma comunque, capiamo bene che sono entrambi frutto. I modelli di computer vision possono distinguere tra banane e kiwi, ma non codificano la conoscenza più astratta che entrambi sono frutto."
Riconoscendo i limiti delle reti neurali per la visione artificiale, i ricercatori hanno combinato l'algoritmo di visione AlexNet con una rete neurale che analizza il significato concettuale, includendo la conoscenza semantica nell'equazione.
"Nel modello combinato, l'elaborazione visiva si associa all'elaborazione semantica e attiva la nostra conoscenza semantica sui concetti, " hanno detto i ricercatori.
La loro nuova tecnica è stata testata sui dati di neuroimaging di 16 volontari, a cui era stato chiesto di nominare le immagini degli oggetti mentre stavano facendo una scansione fMRI. Rispetto ai tradizionali modelli di visione della rete neurale profonda (DNN), il nuovo metodo è stato in grado di identificare le aree del cervello associate all'elaborazione sia visiva che semantica.
In che modo i diversi strati della DNN visiva (viola) e della rete di attrattori semantici (rosso-giallo) vengono mappati su diverse regioni del cervello. Credito:Lorraine Tyler et al. 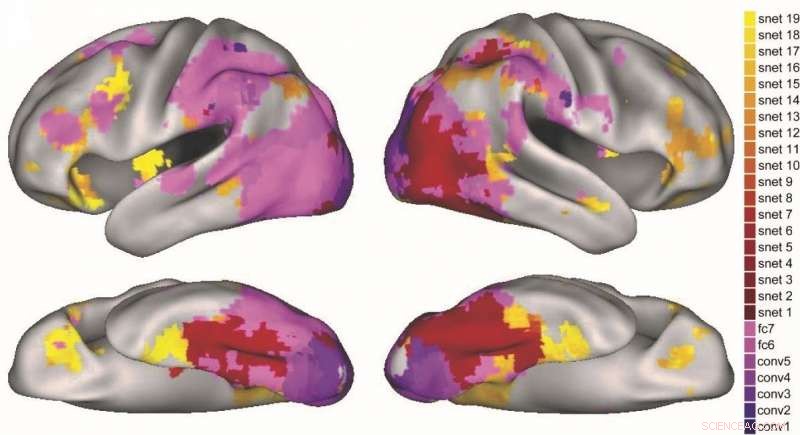
Il metodo che hanno ideato ha fatto previsioni sugli stadi di attivazione semantica nel cervello che sono coerenti con i precedenti resoconti dell'elaborazione degli oggetti, dove l'elaborazione semantica più grossolana lascia il posto a un'elaborazione più fine. I ricercatori hanno anche scoperto che diverse fasi del modello prevedevano l'attivazione in diverse regioni del percorso di elaborazione degli oggetti del cervello.
"In definitiva, modelli migliori di come le persone elaborano in modo significativo gli oggetti visivi possono avere implicazioni cliniche pratiche; Per esempio, nella comprensione di condizioni come la demenza semantica, dove le persone perdono la conoscenza del significato dei concetti oggettuali, " hanno detto i ricercatori.
Lo studio svolto a Cambridge è un importante contributo nel campo delle neuroscienze, poiché ha mostrato come diverse regioni del cervello contribuiscono all'elaborazione visiva e semantica degli oggetti.
"Ora è fondamentale studiare come le informazioni in una regione possono essere trasformate in uno stato diverso che vediamo in diverse regioni del cervello, " hanno aggiunto i ricercatori. "Per questo, dobbiamo capire come la connettività, e le dinamiche temporali supportano questi processi neurali trasformativi".
La ricerca è stata pubblicata su Rapporti scientifici recentemente.
© 2018 Tech Xplore