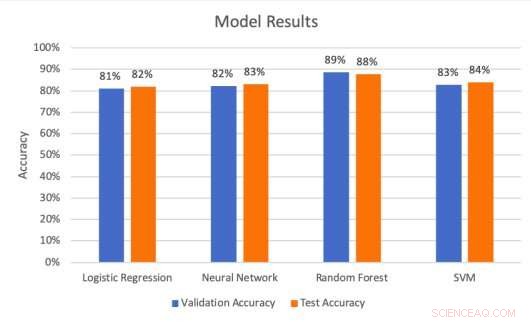
Risultati del modello sui set di validazione e test. Credito:Middlebrook &Sheik.
Due studenti e ricercatori dell'Università di San Francisco (USF) hanno recentemente cercato di prevedere i successi dei cartelloni pubblicitari utilizzando modelli di apprendimento automatico. Nel loro studio, pre-pubblicato su arXiv, hanno addestrato quattro modelli sui dati relativi alle canzoni estratti utilizzando l'API Web di Spotify, e poi ha valutato la loro performance nel prevedere quali canzoni sarebbero diventate dei successi.
"Sono un grande fan della musica, e ascolto musica tutto il giorno; durante il mio tragitto giornaliero, al lavoro, e con gli amici, "Kai Middlebrook, uno dei ricercatori che ha condotto lo studio, ha detto a TechXplore. "L'ultima primavera, Ho iniziato un progetto di ricerca sulla classificazione automatica dei generi musicali con il professor David Guy Brizan all'Università di San Francisco (USF). Il progetto ha richiesto una grande quantità di dati musicali, e i servizi di streaming musicale più diffusi hanno esattamente il tipo di dati di cui avevo bisogno."
Mentre lavorava a un progetto relativo alla classificazione automatica dei generi musicali, Middlebrook ha appreso che Spotify consente agli sviluppatori di accedere ai suoi dati musicali. Questo lo ha incoraggiato a iniziare a sperimentare con l'API Web di Spotify per raccogliere dati per i suoi studi. Una volta completata la ricerca relativa alla classificazione dei generi, però, ha messo da parte l'API per un po' di tempo.
"Pochi mesi dopo, il mio amico Kian, che è anche un data scientist e ama la musica, e ho avuto una discussione sulla musica, " ha detto Middlebrook. "A un certo punto durante la conversazione, l'idea generalmente diffusa che "tutte le canzoni di successo suonano allo stesso modo" è stata sollevata. Non credevamo necessariamente che fosse vero, ma l'idea ci ha fatto chiedere:e se le canzoni di successo condividessero alcune somiglianze? sembrava possibile, così Kian e io abbiamo deciso di indagare ulteriormente".
Middlebrook e Sheik, che in precedenza aveva collaborato al progetto di classificazione dei generi, ha deciso di effettuare un'ulteriore indagine utilizzando i dati estratti da Spotify. Questo nuovo progetto sarebbe anche l'incarico finale per il loro corso di data mining presso l'USF.
"Stavamo collaborando a diversi altri progetti per vari corsi, quindi aveva senso restare uniti, "Kian Sheik, un altro ricercatore coinvolto nello studio, ha detto a TechXplore. "La hit di Lil Nas X "Old Town Road" era appena uscita dal nulla, ed era in cima alla Billboard Hot 100. Kai e io ci chiedevamo se un computer avrebbe potuto prevedere la sua ascesa, o se fosse solo un singolo di successo che è uscito dal campo sinistro. Quello che è iniziato come un semplice progetto finale si è concluso con l'esaurimento di tutti i modelli di apprendimento supervisionato all'avanguardia su un ampio set di dati per rispondere a una semplice domanda:questa canzone sarà un successo?"
Nel loro studio, Middlebrook e Sheik hanno utilizzato l'API Web di Spotify per raccogliere dati per 1,8 milioni di brani, che includeva caratteristiche come il tempo di una canzone, chiave, valenza, ecc. Hanno anche raccolto circa 30 anni di dati dalla classifica Billboard Hot 100.
"Il nostro obiettivo era vedere se le canzoni di successo condividevano caratteristiche simili, e se così fosse, se queste funzionalità potrebbero essere utilizzate per prevedere quali canzoni sarebbero state hit in futuro, "Ha detto Middlebrook.
I ricercatori hanno addestrato e valutato quattro diversi modelli:una regressione logistica, una rete neurale, una macchina vettoriale di supporto (SVM) e un'architettura a foresta casuale (RF). Durante l'allenamento, questi modelli hanno analizzato una varietà di caratteristiche della canzone, compreso il tempo, chiave, valenza, energia, acustica, ballabilità e volume.
"Quando viene data una canzone, i nostri modelli lo etichetterebbero con uno o uno zero, " ha spiegato Middlebrook. "Una canzone etichettata con uno significa che il modello prevede che la canzone sia stata un successo. Una canzone etichettata con uno zero significa che il modello prevede che la canzone non sia stata un successo".
Il modello di regressione logistica addestrato dai ricercatori presuppone che i dati delle canzoni possano essere separati linearmente in due categorie:successi e non successi. Il modello assegna un peso a ciascuna caratteristica del brano, e quindi utilizza questi pesi per prevedere se una canzone rientra nella categoria "hit" o "non-hit".
I modelli di regressione logistica presentano due importanti vantaggi:interpretabilità e velocità. In altre parole, questo tipo di architettura rende più facile interpretare la relazione tra variabili esplicative (es. le caratteristiche della canzone) e la variabile di risposta (cioè, colpito o non colpito), e può anche essere addestrato in tempi relativamente brevi.
Il secondo modello addestrato dai ricercatori era un'architettura RF. Questo modello funziona combinando una grande quantità di elementi costitutivi noti come alberi decisionali.
"Essenzialmente, un albero decisionale può essere pensato come un modello che utilizza una serie di domande sì/no per separare i dati, " Middlebrook ha detto. "Sono interpretabili, ma incline all'overfitting dei dati. Overfitting significa che un modello memorizza i dati di addestramento adattandoli troppo da vicino. Il problema con l'overfitting è che il modello potrebbe non apprendere l'effettiva relazione tra le caratteristiche del brano e la popolarità del brano perché i dati spesso contengono rumore irrilevante".
Per evitare il problema del sovradattamento, il modello di foresta casuale utilizzato da Middlebrook e Sheik combina centinaia di migliaia di alberi decisionali, ognuno dei quali viene addestrato su un diverso sottoinsieme dei dati di allenamento e su un diverso sottoinsieme delle caratteristiche del brano. Il modello quindi fa una previsione (cioè, decide se una canzone è un successo o meno) facendo la media della previsione di ciascun albero e combinando questi risultati insieme.
"Nel nostro caso d'uso, il vantaggio del modello di foresta casuale è la sua flessibilità, " Middlebrook ha detto. "È più flessibile di un modello lineare (ad es. regressione logistica)."
Il terzo e il quarto modello addestrati dai ricercatori, vale a dire le architetture SVM e di rete neurale, sono entrambi non lineari e sono quindi più difficili da interpretare. Il modello SVM funziona cercando di trovare l'"iperpiano" che meglio separa i dati nelle due categorie (cioè, successi o non successi). L'architettura della rete neurale, d'altra parte, utilizza un livello nascosto con dieci filtri per apprendere dai dati del brano.
Tra i quattro modelli utilizzati da Middlebrook e Sheik, il modello di regressione logistica è il più facile da interpretare, mentre quello basato sulla rete neurale è il più difficile. Gli altri due modelli cadono da qualche parte nel mezzo.
"In genere, questi modelli prediranno in base ai vincoli che sviluppano attraverso la formazione, " Ha detto Sheik. "Ogni modello è stato addestrato sullo stesso set di classificatori sonori. L'output dei modelli viene testato rispetto alla verità storica dall'API Billboard, indipendentemente dal fatto che il brano sia mai apparso nella Billboard Hot 100 list. Abbiamo usato una flotta di computer all'USF per fare il calcolo dei numeri e dopo un paio di settimane di puro calcolo, avevamo calcolato i parametri ottimali per ogni modello."
I ricercatori hanno effettuato una serie di valutazioni per verificare quanto bene i quattro modelli potessero prevedere i successi dei cartelloni pubblicitari. Hanno scoperto che l'architettura SVM ha raggiunto il più alto tasso di precisione (99,53 percento), mentre il modello di foresta casuale ha ottenuto il miglior tasso di precisione (88%) e il tasso di richiamo (85,51%).
"Recall esprime la capacità di trovare tutte le istanze rilevanti in un set di dati, mentre la precisione esprime quale proporzione di dati che il nostro modello dice fosse rilevante era in realtà rilevante, "Spiegò Middlebrook. "In altre parole, richiamo ci dice quanto è probabile che il nostro modello preveda con precisione un successo effettivo come un successo. La precisione ci dice la proporzione di successi previsti che sono stati effettivamente successi".
Secondo i ricercatori, se le case discografiche dovessero utilizzare uno di questi modelli per prevedere quali canzoni avranno più successo, probabilmente sceglierebbero un modello con un alto tasso di precisione rispetto a uno con un alto tasso di precisione. Questo perché un modello che raggiunge un'elevata precisione assume meno rischi, poiché è meno probabile che una canzone di successo diventi un successo.
"Le etichette discografiche hanno risorse limitate, " ha detto Middlebrook. "Se riversano queste risorse in una canzone che il modello prevede sarà un successo e quella canzone non lo diventerà mai, allora l'etichetta potrebbe perdere molti soldi. Quindi, se un'etichetta discografica vuole correre un po' più di rischio con la possibilità di pubblicare più dischi di successo, potrebbero scegliere di utilizzare il nostro modello di foresta casuale. D'altra parte, se un'etichetta discografica vuole assumersi meno rischi pur continuando a pubblicare alcuni successi, dovrebbero usare il nostro modello SVM."
Middlebrook e Sheik hanno scoperto che prevedere un successo pubblicitario basato sulle caratteristiche dell'audio di una canzone è, infatti, possibile. Nelle loro ricerche future, i ricercatori hanno in programma di indagare su altri fattori che potrebbero contribuire al successo della canzone, come la presenza sui social, esperienza artistica, e l'influenza dell'etichetta.
"Possiamo immaginare un mondo in cui le etichette discografiche che sono costantemente alla ricerca di nuovi talenti sono inondate di mix-tape e demo dei "prossimi artisti in voga, "" ha detto lo sceicco. "Le persone hanno solo così tanto tempo per ascoltare la musica con orecchie umane, quindi "orecchie artificiali, " come i nostri algoritmi, possono consentire alle etichette discografiche di formare un modello per il tipo di suono che cercano e ridurre notevolmente il numero di canzoni che devono prendere in considerazione".
Classificatori come quelli sviluppati da Middlebrook e Sheik potrebbero in definitiva aiutare le etichette discografiche a decidere su quali canzoni investire. Sebbene l'idea di utilizzare l'apprendimento automatico per scorrere le demo potrebbe essere interessante per l'industria musicale, Sheik avverte che potrebbe anche avere conseguenze indesiderate.
"Anche se questo può essere un futuro opportuno, la prospettiva di un proverbiale "tagliere" con cui gli artisti devono misurarsi ha il potenziale per diventare una cassa di risonanza, o una situazione in cui la nuova musica deve suonare come la vecchia musica per essere rilasciata alla radio, " ha detto Sheik. "Creatori di contenuti su piattaforme come YouTube, che utilizza anche algoritmi per decidere quali video vengono mostrati alle masse, hanno denunciato le insidie di costringere gli artisti a lavorare per una macchina."
Secondo lo sceicco, se aziende e produttori iniziano a utilizzare algoritmi per prendere decisioni artistiche, questi modelli dovrebbero essere progettati in modo da non arrestare il progresso dell'arte. Le architetture sviluppate dai due ricercatori dell'USF, però, non sono ancora in grado di raggiungere questo obiettivo.
"Dovranno essere introdotti e inventati pregiudizi di novità e altre caratteristiche non ortodosse affinché la musica nel suo insieme non si avvicini a una singolarità culturale per mano dell'opportunità, " ha concluso lo sceicco.
© 2019 Science X Network