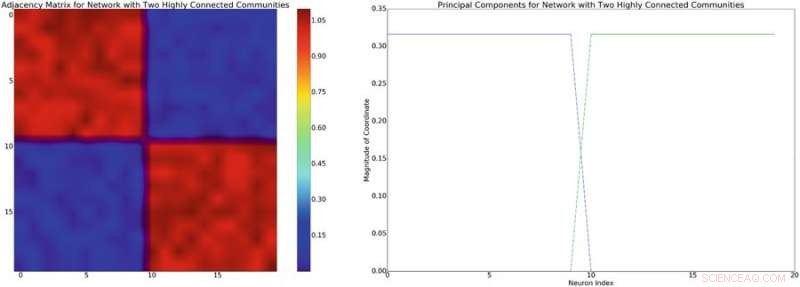
A sinistra:esempio di matrice di adiacenza con struttura approssimata a blocchi diagonali. Assumendo un modello di miscela lineare delle interazioni neuronali, questa struttura di rete indurrà una covarianza diagonale approssimativamente a blocchi di struttura simile. A destra:a sinistra le componenti principali associate alla matrice di adiacenza. Credito:Mitchell &Petzold
Brian Mitchell e Linda Petzold, due ricercatori dell'Università della California, hanno recentemente applicato l'apprendimento per rinforzo profondo privo di modelli a modelli di dinamica neurale, ottenendo risultati molto promettenti.
L'apprendimento per rinforzo è un'area di apprendimento automatico ispirata alla psicologia comportamentista che allena gli algoritmi per completare efficacemente compiti particolari, utilizzando un sistema basato su ricompensa e punizione. Una pietra miliare importante in questo settore è stato lo sviluppo del Deep-Q-Network (DQN), che è stato inizialmente utilizzato per addestrare un computer a giocare ai giochi Atari.
L'apprendimento per rinforzo senza modelli è stato applicato a una varietà di problemi, ma DQN generalmente non viene utilizzato. La ragione principale di ciò è che DQN può proporre un numero limitato di azioni, mentre i problemi fisici richiedono generalmente un metodo in grado di proporre un continuum di azioni.
Durante la lettura della letteratura esistente sul controllo neurale, Mitchell e Petzold hanno notato l'uso diffuso di un paradigma classico per risolvere problemi di controllo neurale con strategie di apprendimento automatico. Primo, l'ingegnere e lo sperimentatore concordano sull'obiettivo e sul disegno del loro studio. Quindi, quest'ultimo esegue l'esperimento e raccoglie i dati, che verrà poi analizzato dall'ingegnere e utilizzato per costruire un modello del sistema di interesse. Finalmente, l'ingegnere sviluppa un controller per il modello e il dispositivo implementa questo controller.
Risultati dell'esperimento che controlla l'oscillazione nello spazio delle fasi definito da un singolo componente principale. Il primo grafico dall'alto è un grafico dell'input nella cella attivata nel tempo; il secondo grafico dall'alto è un grafico dei picchi dell'intera rete, dove colori diversi corrispondono a celle diverse; il terzo grafico dall'alto corrisponde al potenziale di membrana di ciascuna cellula nel tempo; il quarto grafico dall'alto mostra l'oscillazione target; il grafico in basso mostra l'oscillazione osservata. La politica, nonostante fornisca input a una sola cella, è in grado di indurre approssimativamente l'oscillazione del bersaglio nello spazio delle fasi osservato. Credito:Mitchell &Petzold 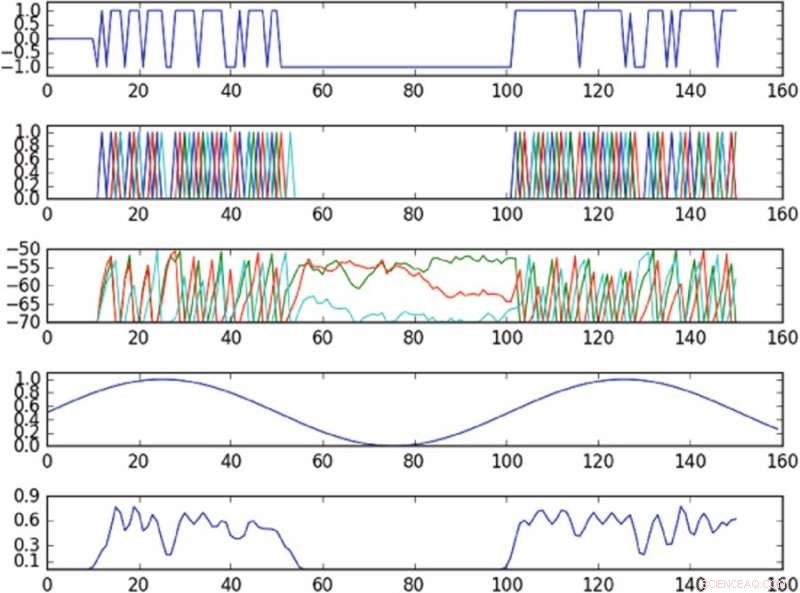
I ricercatori hanno adattato un metodo di apprendimento per rinforzo privo di modelli chiamato "gradienti politici deterministici profondi" (DDPG) e lo hanno applicato a modelli di dinamica neurale di basso e alto livello. Hanno scelto specificamente DDPG perché offre un framework molto flessibile, che non richiede all'utente di modellare la dinamica del sistema.
Ricerche recenti hanno scoperto che i metodi privi di modelli generalmente richiedono troppa sperimentazione con l'ambiente, rendendo più difficile applicarli a problemi più pratici. Ciò nonostante, i ricercatori hanno scoperto che il loro approccio senza modelli ha funzionato meglio degli attuali metodi basati su modelli ed è stato in grado di risolvere problemi di dinamica neurale più difficili, come il controllo delle traiettorie attraverso uno spazio delle fasi latenti di una rete di neuroni sottoattivata.
"Per i problemi che abbiamo considerato in questo documento, gli approcci privi di modello erano abbastanza efficienti e non richiedevano affatto molta sperimentazione, suggerendo che per problemi neurali, i controller allo stato dell'arte sono più pratici di quanto si possa pensare, " disse Mitchell.
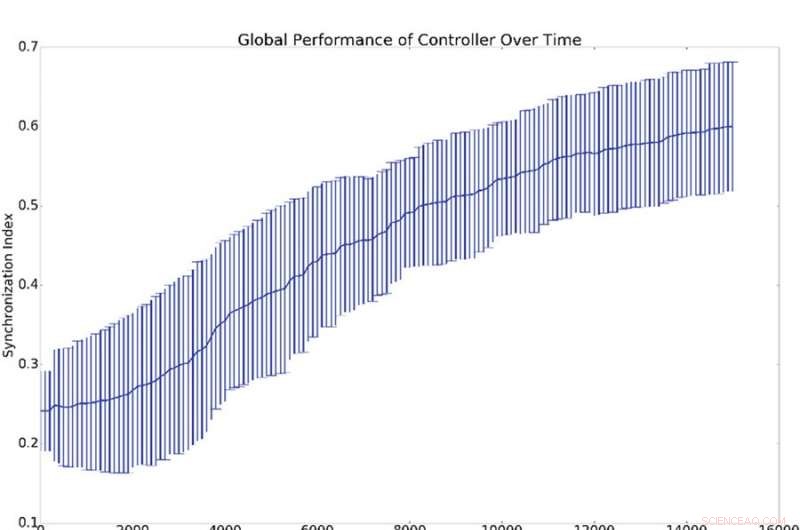
Risultati riepilogativi di 10 esperimenti di sincronizzazione. (a) Rappresenta la media e la deviazione standard della sincronizzazione globale, (cioè q dall'equazione 16), rispetto al numero di periodi di formazione del titolare. (b) Mostra gli istogrammi che dimostrano il livello di sincronizzazione di tutti gli oscillatori di rete con l'oscillatore di riferimento (cioè qi dall'equazione 16). Questo è, un punto sulla curva blu o verde dimostra la probabilità di avere un dato valore per qi. L'istogramma blu mostra i conteggi prima dell'allenamento mentre l'istogramma verde mostra i conteggi dopo l'allenamento. La sincronizzazione media con il riferimento, qi, è molto più alto della sincronizzazione globale, Q, il che è spiegato dal fatto che la sincronizzazione con il riferimento è più facile da indurre rispetto alla sincronizzazione globale. Credito:Mitchell &Petzold
Mitchell e Petzold hanno svolto il loro studio come una simulazione, quindi importanti aspetti pratici e di sicurezza devono essere considerati prima che il loro metodo possa essere introdotto in contesti clinici. Ulteriori ricerche che incorporano modelli in approcci privi di modelli, o che pone limiti ai controllori model-free, potrebbe aiutare a migliorare la sicurezza prima che questi metodi entrino in contesti clinici.
In futuro, i ricercatori hanno anche in programma di studiare come i sistemi neurali si adattano al controllo. I cervelli umani sono organi altamente dinamici che si adattano all'ambiente circostante e cambiano in risposta alla stimolazione esterna. Ciò potrebbe causare una competizione tra il cervello e il controller, soprattutto quando i loro obiettivi non sono allineati.
"In molti casi, vogliamo che vinca il controller e la progettazione di controller che vincono sempre è un problema importante e interessante, " disse Mitchell. "Per esempio, nel caso in cui il tessuto da controllare sia una regione malata del cervello, questa regione potrebbe avere una certa progressione che il controller sta cercando di correggere. In molte malattie, questa progressione può resistere al trattamento (ad esempio un tumore che si adatta all'espulsione della chemioterapia è un esempio canonico), ma gli attuali approcci privi di modelli non si adattano bene a questo tipo di cambiamenti. Migliorare i controller senza modelli per gestire meglio l'adattamento da parte del cervello è una direzione interessante che stiamo esaminando".
La ricerca è pubblicata su Rapporti scientifici .
© 2018 Tech Xplore