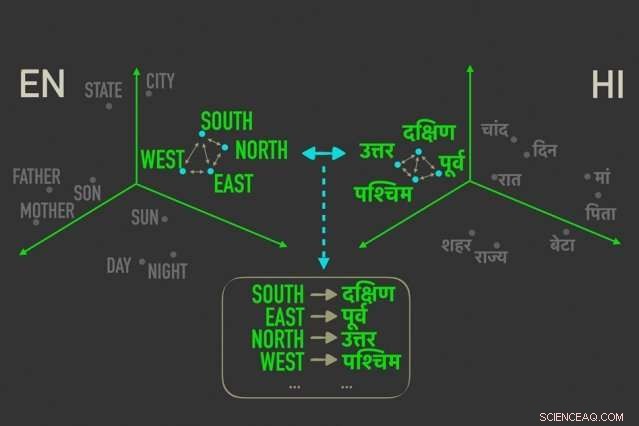
Il nuovo modello misura le distanze tra parole con significati simili in "word embedding, ” e quindi allinea le parole in entrambi gli incastri che sono più strettamente correlate da distanze relative, il che significa che è più probabile che siano traduzioni dirette l'una dell'altra. Credito:Massachusetts Institute of Technology
I ricercatori del MIT hanno sviluppato un nuovo modello di traduzione linguistica "non supervisionato", il che significa che funziona senza la necessità di annotazioni e guida umane, che potrebbe portare a traduzioni computerizzate più efficienti di molte più lingue.
Sistemi di traduzione di Google, Facebook, e Amazon richiedono modelli di formazione per cercare modelli in milioni di documenti, come documenti legali e politici, o articoli di notizie, che sono stati tradotti in varie lingue da esseri umani. Date nuove parole in una lingua, possono quindi trovare le parole e le frasi corrispondenti nell'altra lingua.
Ma questi dati traslazionali richiedono tempo e sono difficili da raccogliere, e semplicemente potrebbe non esistere per molti dei 7, 000 lingue parlate in tutto il mondo. Recentemente, i ricercatori hanno sviluppato modelli "monolingui" che effettuano traduzioni tra testi in due lingue, ma senza informazioni traduttive dirette tra i due.
In un articolo presentato questa settimana alla Conferenza sui metodi empirici nell'elaborazione del linguaggio naturale, i ricercatori del Computer Science and Artificial Intelligence Laboratory (CSAIL) del MIT descrivono un modello che funziona più velocemente e in modo più efficiente rispetto a questi modelli monolingue.
Il modello sfrutta una metrica nelle statistiche, chiamata distanza Gromov-Wasserstein, che essenzialmente misura le distanze tra i punti in uno spazio computazionale e le abbina a punti similmente distanziati in un altro spazio. Applicano quella tecnica ai "word embedding" di due lingue, che sono parole rappresentate come vettori, fondamentalmente, matrici di numeri, con parole di significato simile raggruppate più vicine tra loro. Così facendo, il modello allinea rapidamente le parole, o vettori, in entrambi gli incastri che sono più strettamente correlati da distanze relative, il che significa che è probabile che siano traduzioni dirette.
Negli esperimenti, il modello dei ricercatori ha funzionato con la stessa precisione dei modelli monolingue all'avanguardia, e talvolta in modo più accurato, ma molto più rapidamente e utilizzando solo una frazione della potenza di calcolo.
"Il modello vede le parole nelle due lingue come insiemi di vettori, e mappa [quei vettori] da un insieme all'altro essenzialmente preservando le relazioni, ", afferma il coautore del giornale Tommi Jaakkola, un ricercatore CSAIL e il Thomas Siebel Professor presso il Dipartimento di Ingegneria Elettrica e Informatica e l'Institute for Data, Sistemi, e Società. "L'approccio potrebbe aiutare a tradurre lingue o dialetti con poche risorse, purché abbiano abbastanza contenuti monolingue."
Il modello rappresenta un passo verso uno dei principali obiettivi della traduzione automatica, che è un allineamento di parole completamente non supervisionato, dice il primo autore David Alvarez-Melis, un dottorato CSAIL studente:"Se non hai dati che corrispondano a due lingue... puoi mappare due lingue e, usando queste misure di distanza, allinearli."
Le relazioni contano di più
Allineare gli incorporamenti di parole per la traduzione automatica non supervisionata non è un concetto nuovo. Lavori recenti addestrano le reti neurali per abbinare i vettori direttamente negli incorporamenti di parole, o matrici, da due lingue insieme. Ma questi metodi richiedono molte modifiche durante l'allenamento per ottenere gli allineamenti esattamente corretti, che è inefficiente e richiede tempo.
Misurare e abbinare i vettori in base alle distanze relazionali, d'altra parte, è un metodo molto più efficiente che non richiede molta messa a punto. Non importa dove cadono i vettori di parole in una data matrice, il rapporto tra le parole, intendendo le loro distanze, rimarrà lo stesso. Ad esempio, il vettore per "padre" può ricadere in aree completamente diverse in due matrici. Ma i vettori per "padre" e "madre" molto probabilmente saranno sempre vicini tra loro.
"Quelle distanze sono invarianti, " dice Alvarez-Melis. "Guardando a distanza, e non le posizioni assolute dei vettori, quindi puoi saltare l'allineamento e andare direttamente alla corrispondenza delle corrispondenze tra i vettori."
È qui che torna utile Gromov-Wasserstein. La tecnica è stata utilizzata in informatica per, dire, aiutando ad allineare i pixel dell'immagine nella progettazione grafica. Ma la metrica sembrava "su misura" per l'allineamento delle parole, Alvarez-Melis dice:"Se ci sono punti, o parole, che sono vicini in uno spazio, Gromov-Wasserstein cercherà automaticamente di trovare il corrispondente gruppo di punti nell'altro spazio".
Per la formazione e il test, i ricercatori hanno utilizzato un set di dati di incorporamenti di parole disponibili pubblicamente, chiamato FASTTEXT, con 110 combinazioni linguistiche. In questi incastri, e altri, le parole che appaiono sempre più frequentemente in contesti simili hanno vettori strettamente corrispondenti. "Madre" e "padre" di solito sono vicini ma entrambi più lontani, dire, "Casa."
Fornire una "traduzione soft"
Il modello rileva vettori strettamente correlati ma diversi dagli altri, e assegna una probabilità che corrispondano vettori a distanza simile nell'altra immersione. È un po' come una "traduzione soft, " Alvarez-Melis dice, "perché invece di restituire una sola parola di traduzione, ti dice 'questo vettore, o parola, ha una forte corrispondenza con questa parola, o parole, nell'altra lingua.'"
Un esempio potrebbe essere nei mesi dell'anno, che appaiono strettamente insieme in molte lingue. Il modello vedrà un cluster di 12 vettori raggruppati in un'incorporazione e un cluster notevolmente simile nell'altra. "La modella non sa che questi sono mesi, " Dice Alvarez-Melis. "Sa solo che c'è un gruppo di 12 punti che si allinea con un gruppo di 12 punti nell'altra lingua, ma sono diverse dal resto delle parole, quindi probabilmente stanno bene insieme. Trovando queste corrispondenze per ogni parola, quindi allinea l'intero spazio simultaneamente."
I ricercatori sperano che il lavoro serva da "verifica di fattibilità, "Jaakkola dice, applicare il metodo Gromov-Wasserstein ai sistemi di traduzione automatica per funzionare più velocemente, Più efficiente, e ottenere l'accesso a molte più lingue.
Inoltre, un possibile vantaggio del modello è che produce automaticamente un valore che può essere interpretato come quantificativo, su scala numerica, la somiglianza tra le lingue. Può essere utile per studi di linguistica, dicono i ricercatori. Il modello calcola la distanza tra tutti i vettori in due immersioni, che dipende dalla struttura della frase e da altri fattori. Se i vettori sono tutti molto vicini, segneranno più vicino a 0, e più sono distanti, più alto è il punteggio. Lingue romanze simili come francese e italiano, ad esempio, punteggio vicino a 1, mentre il cinese classico ottiene un punteggio compreso tra 6 e 9 con le altre lingue principali.
"Questo ti dà un bel semplice numero per capire come sono le lingue simili... e può essere usato per trarre spunti sulle relazioni tra le lingue, " dice Alvarez-Melis.
Questa storia è stata ripubblicata per gentile concessione di MIT News (web.mit.edu/newsoffice/), un popolare sito che copre notizie sulla ricerca del MIT, innovazione e didattica.