Credito:CC0 Dominio Pubblico
Il 3 novembre Nel 2020, e per molti giorni dopo, milioni di persone hanno tenuto d'occhio i modelli di previsione delle elezioni presidenziali gestiti da varie agenzie di stampa. Con una posta in gioco così alta, ogni tick di un conteggio e ogni contrazione di un grafico potrebbe inviare onde d'urto di sovrainterpretazione.
Un problema con i risultati grezzi delle elezioni presidenziali è che creano una falsa narrativa secondo cui i risultati finali si stanno ancora sviluppando in modi drastici. In realtà, nella notte delle elezioni non c'è "recupero da dietro" o "perdere la testa" perché i voti sono già espressi; il vincitore ha già vinto, ma non lo sappiamo ancora. Più che essere semplicemente impreciso, queste avvincenti descrizioni del processo di voto possono far sembrare i risultati eccessivamente sospetti o sorprendenti.
"I modelli predittivi vengono utilizzati per prendere decisioni che possono avere enormi conseguenze sulla vita delle persone, " disse Emmanuel Candès, la cattedra Barnum-Simons in matematica e statistica presso la School of Humanities and Sciences della Stanford University. "È estremamente importante comprendere l'incertezza su queste previsioni, quindi le persone non prendono decisioni basate su false credenze".
Tale incertezza era esattamente ciò che Il Washington Post lo scienziato dei dati Lenny Bronner mirava a evidenziare in un nuovo modello di previsione che ha iniziato a sviluppare per le elezioni locali della Virginia nel 2019 e ulteriormente perfezionato per le elezioni presidenziali, con l'aiuto di John Cherian, un dottorato di ricerca in corso studente in statistica a Stanford che Bronner conosceva dai loro studi universitari.
"Il modello riguardava davvero l'aggiunta di contesto ai risultati che venivano mostrati, " ha detto Bronner. "Non si trattava di prevedere le elezioni. Si trattava di dire ai lettori che i risultati che stavano vedendo non riflettevano dove pensavamo che sarebbero andate a finire le elezioni".
Questo modello è la prima applicazione nel mondo reale di una tecnica statistica esistente sviluppata a Stanford da Candès, l'ex borsista postdottorato Yaniv Romano e l'ex studente laureato Evan Patterson. La tecnica è applicabile a una varietà di problemi e, come nel modello di predicazione del Post, potrebbe contribuire ad elevare l'importanza dell'onesta incertezza nelle previsioni. Mentre il Post continua a mettere a punto il proprio modello per le future elezioni, Candès sta applicando la tecnica sottostante altrove, compresi i dati sul COVID-19.
Evitare le supposizioni
Per creare questa tecnica statistica, Candes, Romano ed Evan Patterson hanno combinato due aree di ricerca - regressione quantile e previsione conforme - per creare quello che Candès ha definito "il più informativo, gamma ben calibrata di valori previsti che so come costruire."
Sebbene la maggior parte dei modelli di previsione cerchi di prevedere un singolo valore, spesso la media (media) di un set di dati, la regressione quantile stima una gamma di risultati plausibili. Per esempio, una persona potrebbe voler trovare il 90esimo quantile, che è la soglia al di sotto della quale si prevede che il valore osservato scenda il 90% delle volte. Quando aggiunto alla regressione quantile, la previsione conforme, sviluppata dall'informatico Vladimir Vovk, calibra i quantili stimati in modo che siano validi al di fuori di un campione, come per i dati finora invisibili. Per il modello elettorale del Post, ciò significava utilizzare i risultati delle votazioni di aree demograficamente simili per aiutare a calibrare le previsioni sui voti eccezionali.
La particolarità di questa tecnica è che inizia con ipotesi minime incorporate nelle equazioni. Per lavorare, però, deve iniziare con un campione rappresentativo di dati. Questo è un problema per la notte delle elezioni perché il voto iniziale conta, di solito da piccole comunità con più voti di persona, raramente riflette il risultato finale.
Senza accesso a un campione rappresentativo dei voti attuali, Bronner e Cherian hanno dovuto aggiungere un'ipotesi. Hanno calibrato il loro modello utilizzando i conteggi dei voti delle elezioni presidenziali del 2016 in modo che quando un'area riportasse il 100 percento dei propri voti, il modello del Post presumerebbe che qualsiasi cambiamento tra i voti del 2020 di quell'area e i suoi voti del 2016 si rifletterebbe ugualmente in contee simili. (Il modello si adatterebbe quindi ulteriormente, riducendo l'influenza dell'ipotesi, poiché più aree hanno riportato il 100 percento dei loro voti.) Per verificare la validità di questo metodo, hanno testato il modello ad ogni elezione presidenziale, a partire dal 1992, e ha scoperto che le sue previsioni corrispondevano da vicino ai risultati del mondo reale.
"La cosa bella dell'utilizzo dell'approccio di Emmanuel a questo è che le barre di errore attorno alle nostre previsioni sono molto più realistiche e possiamo mantenere ipotesi minime, " disse Cherian.
Visualizzazione dell'incertezza
In azione, la visualizzazione del modello dal vivo del Post è stata accuratamente progettata per mostrare in modo visibile quelle barre di errore e l'incertezza che rappresentavano. Il Post ha eseguito il modello per prevedere la gamma di probabili risultati elettorali in diversi stati e tipi di contea; le contee sono state classificate in base alla loro demografia. In ogni caso, ogni candidato aveva la propria barra orizzontale che si riempiva di blu solido per Joe Biden, rosso per Donald Trump, per mostrare i voti noti. Quindi, il resto della barra conteneva un gradiente che rappresentava i risultati più probabili per i voti in sospeso, secondo il modello. L'area più scura del gradiente era il risultato più probabile.
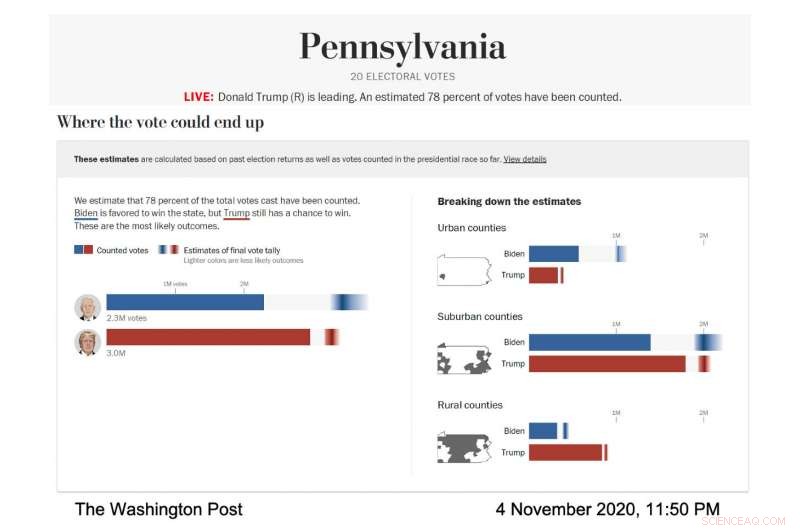
Screenshot del modello elettorale del Washington Post, che mostra la previsione di voto per la Pennsylvania il 4 novembre, 2020. (Credito immagine:per gentile concessione del Washington Post)
"Abbiamo parlato con i ricercatori della visualizzazione dell'incertezza e abbiamo appreso che se dai a qualcuno una previsione media e poi gli dici quanta incertezza è coinvolta, tendono a ignorare l'incertezza, " ha detto Bronner. "Così abbiamo fatto una visualizzazione che è molto 'incertezza in avanti." Volevamo mostrare, questa è l'incertezza e non ti diremo nemmeno qual è la nostra previsione media".
Mentre la notte delle elezioni passava, la parte più scura del gradiente di Biden nella visualizzazione del voto totale era più a destra della barra, il che significava che il modello prevedeva che avrebbe ottenuto più voti. Il suo gradiente era anche più ampio e si estendeva asimmetricamente verso il lato più alto della barra, il che significava che il modello prevedeva molti scenari, con discrete probabilità, dove avrebbe vinto più voti del numero più probabile.
"La notte delle elezioni, abbiamo notato che le barre di errore erano molto corte sul lato sinistro della barra di Biden e molto lunghe sul lato destro, ", ha detto Cherian. "Questo perché Biden aveva molti vantaggi per superare potenzialmente la nostra proiezione in modo sostanziale e non aveva molti svantaggi". Questa previsione asimmetrica era una conseguenza del particolare approccio di modellazione utilizzato da Cherian e Bronner. Poiché le previsioni del modello sono state calibrate utilizzando i risultati di contee demograficamente simili che hanno terminato di riportare i propri voti, è diventato chiaro che Biden aveva buone possibilità di superare in modo significativo il voto democratico del 2016 nelle contee suburbane, mentre era estremamente improbabile che facesse di peggio.
Certo, mentre il conteggio dei voti si dirigeva verso il traguardo, i gradienti si sono ridotti e le previsioni incerte del Post sembravano sempre più certe:una situazione snervante per gli scienziati dei dati preoccupati di sopravvalutare conclusioni così importanti.
"Ero particolarmente preoccupato che la gara si riducesse a uno stato, e avremmo una previsione sulla nostra pagina per giorni che alla fine non si sono avverati, " disse Broner.
E quella preoccupazione era ben fondata perché il modello ha predetto con forza e ostinazione una vittoria di Biden per diversi giorni mentre i conteggi finali dei voti sono arrivati da nessuno stato, ma tre:Wisconsin, Michigan e Pennsylvania.
"Ha finito per vincere quegli stati, quindi ha finito per funzionare bene per il modello, " added Bronner. "But at the time it was very, very stressful."
Following their commitment to transparency, Bronner and Cherian also made the code to their election model public, so people can run it themselves. They've also published technical reports on their methods (available for download here). The model will run again during Virginia state elections this year and the midterm elections in 2022.
"We wanted to make everything public. We want this to be a conversation with people who care about elections and people who care about data, " said Bronner.
Forcing honesty
The bigger picture for Candès is how honest and transparent statistical work can contribute to more reasonable and ethical outcomes in the real world. Statistics, Dopotutto, are foundational to artificial intelligence and algorithms, which are pervasive in our everyday lives. They orchestrate our search results, social media experience and streaming suggestions while also being used in decision-making tools in medical care, university admissions, the justice system and banking. The power—and perceived omnipotence—of algorithms troubles Candès.
Models like the one the Post used can address some of these concerns. By starting with fewer assumptions, the model provides a more honest—and harder to overlook—assessment of the uncertainty surrounding its predictions. And similar models could be developed for a wide variety of prediction problems. Infatti, Candès is currently working on a model, built on the same statistical technique as the Post's election model, to infer survival times after contracting COVID-19 on the basis of relevant factors such as age, sex and comorbidities.
The catch to an honest, assumption-free statistical model, però, is that the conclusions suffer if there isn't enough data. Per esempio, predictions about the consequences of different medical care decisions for women would have much wider error bars than predictions regarding men because we know far less about women, medically, than men.
This catch is a feature, anche se, not a bug. The uncertainty is glaringly obvious and so is the fix:We need more and better data before we start using it to inform important decisions.
"As statisticians, we want to inform decisions, but we're not decision makers, " Candès said. "So I like the way this model communicates the results of data analysis to decision makers because it's extremely honest reporting and avoids positioning the algorithm as the decision maker."