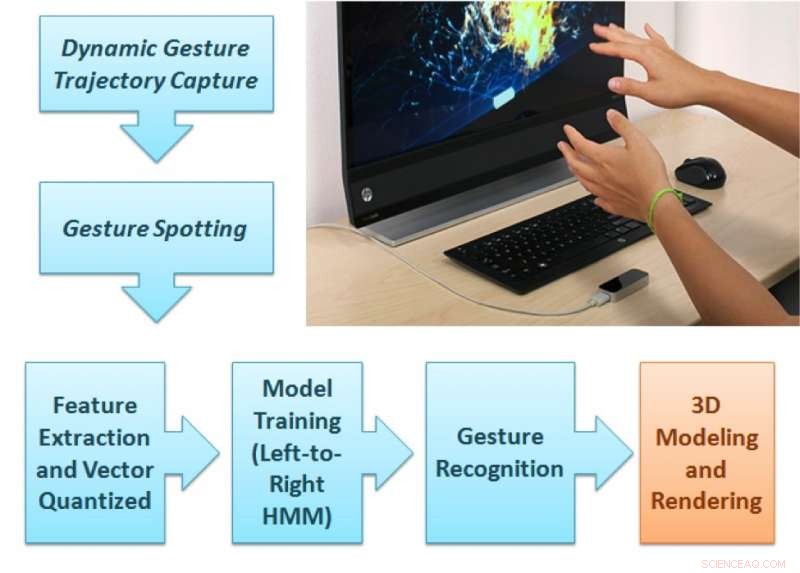
Il quadro di analisi del gesto proposto. Credito:Singla, Roy, e Dogra.
Ricercatori del NIT Kurukshetra, IIT Roorkee e IIT Bhubaneswar hanno sviluppato un nuovo metodo basato su controller Leap Motion che potrebbe migliorare il rendering di forme 2D e 3D sui dispositivi di visualizzazione. Questo nuovo metodo, delineato in un documento pre-pubblicato su arXiv, tiene traccia dei movimenti delle dita mentre gli utenti eseguono gesti naturali all'interno del campo visivo di un sensore.
Negli ultimi anni, ricercatori hanno cercato di progettare innovativi, interfacce utente touchless. Tali interfacce potrebbero consentire agli utenti di interagire con dispositivi elettronici anche quando le loro mani sono sporche o non conduttive, assistendo anche persone con disabilità fisiche parziali. Gli studi che esplorano queste possibilità sono stati migliorati dall'emergere di sensori a basso costo, come quelli usati da Leap Motion, Dispositivi Kinect e RealSense.
"Volevamo sviluppare una tecnologia in grado di fornire un'esperienza didattica coinvolgente agli studenti che imparano l'arte dell'argilla o anche ai bambini che stanno imparando gli alfabeti di base, "Dott.ssa Debi Prosad Dogra, uno dei ricercatori che hanno condotto lo studio ha detto a TechXplore. "Capire il fatto che i bambini imparano meglio dagli stimoli visivi, abbiamo utilizzato un noto dispositivo di acquisizione del movimento della mano per fornire questa esperienza. Volevamo progettare un framework in grado di identificare i gesti dell'insegnante e rendere le immagini sullo schermo. La configurazione può essere utilizzata per applicazioni che richiedono un rendering visivo guidato dai gesti delle mani."
Il quadro proposto dal Dr. Dogra e dai suoi colleghi ha due parti distinte. Nella prima parte, l'utente esegue un gesto naturale tra i 36 tipi di gesti disponibili nel campo visivo del dispositivo Leap Motion.
"Le due telecamere IR all'interno del sensore possono registrare la sequenza dei gesti, " Ha detto il dottor Dogra. "Il modulo di apprendimento automatico proposto può prevedere la classe del gesto e un'unità di rendering rende la forma corrispondente sullo schermo".
Le traiettorie della mano dell'utente vengono analizzate per estrarre le funzionalità estese di Npen++ in 3-D. Queste caratteristiche, che rappresentano i movimenti delle dita dell'utente durante i gesti, vengono alimentati a un modello Markov nascosto unidirezionale da sinistra a destra (HMM) per l'addestramento. Il sistema esegue quindi una mappatura uno a uno tra gesti e forme. Finalmente, le forme corrispondenti a questi gesti vengono visualizzate sul display utilizzando l'interfaccia di MuPad.
"Dal punto di vista di uno sviluppatore, il quadro proposto è un tipico quadro aperto, " ha spiegato il dottor Dogra. "Per aggiungere più gesti, uno sviluppatore deve solo raccogliere dati sulla sequenza dei gesti da un certo numero di volontari e riqualificare il modello di machine learning (ML) per nuove classi. Questo modello ML può apprendere una rappresentazione generalizzata."
Come parte del loro studio, i ricercatori hanno creato un set di dati di 5400 campioni registrati da 10 volontari. Il loro set di dati contiene 18 forme geometriche e 18 non geometriche, compreso il cerchio, rettangolo, fiore, cono, sfera, e molti altri.
"La selezione delle funzionalità è una delle parti essenziali per una tipica applicazione di machine learning, " ha detto il dottor Dogra. "Nel nostro lavoro, abbiamo esteso le funzionalità Npen++ 2-D esistenti in 3-D. È stato dimostrato che le funzionalità estese migliorano significativamente le prestazioni. Le funzionalità 3-D Npen++ possono essere utilizzate anche per altri tipi di segnali, come il rilevamento della postura del corpo, riconoscimento dell'attività, eccetera."
Il Dr. Dogra e i suoi colleghi hanno valutato il loro metodo con una convalida incrociata di cinque volte e hanno scoperto che ha raggiunto un'accuratezza del 92,87 percento. Le loro funzionalità 3D estese hanno superato le funzionalità 3D esistenti per la rappresentazione e la classificazione delle forme. In futuro, il metodo ideato dai ricercatori potrebbe aiutare lo sviluppo di utili applicazioni di interazione uomo-computer (HCI) per dispositivi di visualizzazione intelligenti.
"Il nostro approccio al riconoscimento dei gesti è abbastanza generale, " ha aggiunto il dottor Dogra. "Vediamo questa tecnologia come uno strumento per la comunicazione delle persone sorde e disabili. Ora vogliamo utilizzare il sistema per comprendere i gesti e convertirli in formato o forme scritte, per assistere le persone nelle conversazioni della vita quotidiana. Con l'avvento di modelli avanzati di apprendimento automatico come le reti neurali ricorrenti (RNN) e la memoria a lungo termine (LSTM), ci sono anche ampi ambiti nella classificazione temporale dei segnali."
© 2018 Science X Network