Partendo da un gioco casuale e senza alcuna conoscenza del dominio tranne le regole del gioco, AlphaZero ha sconfitto in modo convincente un programma campione del mondo nei giochi di scacchi e shogi (scacchi giapponesi) e Go. Credito:DeepMind Technologies Ltd
Un team di ricercatori con il gruppo DeepMind e University College, sia nel Regno Unito, ha sviluppato un sistema di intelligenza artificiale in grado di insegnare a se stesso come giocare e padroneggiare tre difficili giochi da tavolo. Nel loro articolo pubblicato sulla rivista Scienza , il gruppo descrive il loro nuovo sistema e spiega perché credono che rappresenti un altro grande passo avanti nello sviluppo dei sistemi di intelligenza artificiale. Murray Campbell con il T.J Watson Research Center negli Stati Uniti offre un pezzo di prospettiva sul lavoro svolto dal team nello stesso numero della rivista.
Sono passati più di 20 anni da quando un supercomputer noto come Deep Blue ha battuto il campione mondiale di scacchi Gary Kasparov, mostrando al mondo fino a che punto era arrivata l'intelligenza artificiale. Negli anni successivi, i computer sono diventati sempre più intelligenti e ora battono gli umani in giochi come gli scacchi, Shogi e Go. Ma tali sistemi sono stati tutti ottimizzati per renderli davvero bravi in un solo gioco. In questo nuovo sforzo, i ricercatori hanno creato un sistema di intelligenza artificiale che non solo è bravo a più di un gioco, ma acquisisce tale esperienza da solo.
Il nuovo sistema, chiamato AlphaZero, è un sistema di apprendimento per rinforzo, quale, come suggerisce il nome, significa che impara giocando ripetutamente e imparando dalle sue esperienze. Questo è, Certo, molto simile a come apprendono gli umani. Viene stabilito un insieme di regole di base e poi il computer gioca con se stesso. Non ha nemmeno bisogno di giocare con altri partner. Si riproduce ripetutamente, notando quali giocate costituiscono buone mosse e quindi vincenti, e che costituiscono mosse sbagliate e sconfitte. Col tempo, migliora. Infine, diventa così buono che può battere non solo gli umani, ma altri sistemi di intelligenza artificiale dedicati ai giochi da tavolo. Il sistema utilizzava anche un metodo di ricerca noto come ricerca albero Monte Carlo. La combinazione delle due tecnologie consente al sistema di apprendere come migliorare nel gioco. I ricercatori hanno dato al loro sistema di test molta potenza, anche, impiegando 5000 unità di elaborazione del tensore, che lo mette alla pari con i grandi supercomputer.
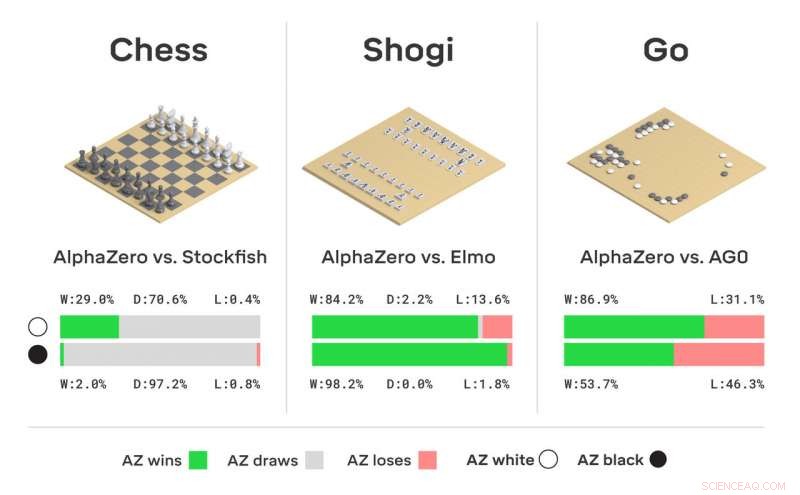
Valutazione del torneo di AlphaZero negli scacchi, Shogi, e vai, come partite vinte, disegnato o perso dal punto di vista di AlphaZero, nelle partite contro lo Stoccafisso, Elmo, e AlphaGo Zero (AG0) che è stato addestrato per tre giorni. Credito:DeepMind Technologies Ltd
Finora, AlphaZero ha imparato a giocare a scacchi, shogi e Go:giochi particolarmente adatti alle applicazioni di intelligenza artificiale. Campbell suggerisce che il prossimo passo per tali sistemi potrebbe essere quello di espandersi in giochi come il poker, o anche videogiochi popolari.
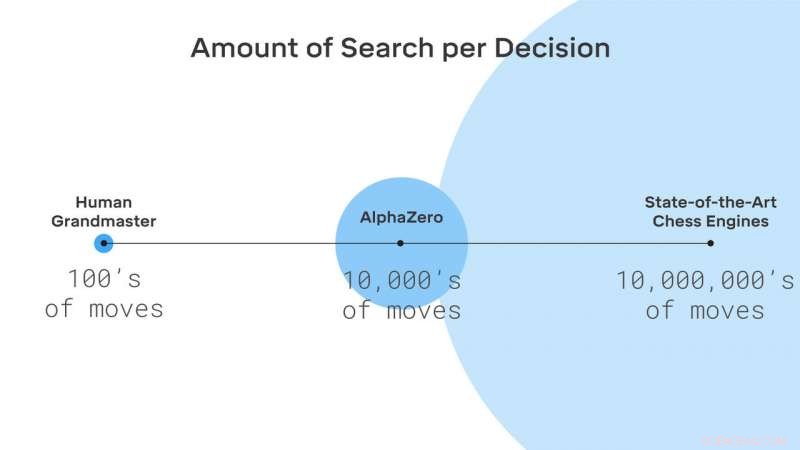
AlphaZero ricerca solo una piccola frazione delle posizioni considerate dai tradizionali motori scacchistici. Credito:DeepMind Technologies Ltd
© 2018 Science X Network