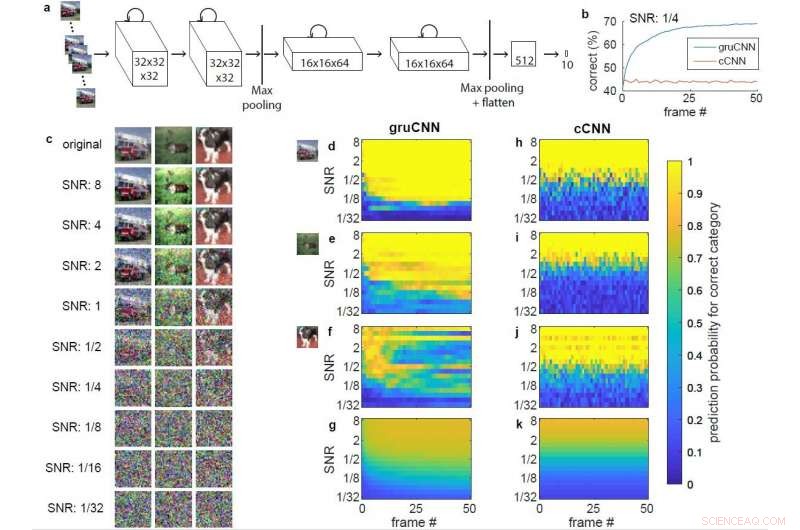
Architettura e dati di esempio. a) Architettura di gruCNN. L'attività di ogni canale dipende sia dall'ingresso corrente che dallo stato precedente. b) Prestazioni di classificazione dell'esempio gruCNN e cCNN quando tutte le sequenze di test avevano un SNR di 1/4. c) Immagine originale e immagine con SNR diversi per un camion dei pompieri (categoria camion) una renna (categoria cervi), e un cane, mostrato senza jitter. d–k) Probabilità previste codificate a colori (output di softmax) della categoria di immagine corretta (positiva) per gruCNN (d–g) e cCNN (h–k). Gli assi orizzontali mostrano le probabilità previste su 51 fotogrammi, assi verticali su un intervallo di SNR. d) &h) ed e) &i) corrispondono alle prestazioni negli esempi di camion dei pompieri e renne, rispettivamente. La probabilità predittiva a bassi SNR continua a migliorare su frame per le previsioni gruCNN, ma sono relativamente costanti per la cCNN. f) &j) Dati per il terzo esempio (il cane), in cui il gruCNN fallisce (che è raro) mentre il cCNN prevede correttamente la categoria alla maggior parte degli SNR. La probabilità media prevista per la categoria di immagine corretta (positiva) per tutti i 10, 000 immagini di prova vengono visualizzate in g) &k). Credito:Till S. Hartmann/arXiv:1811.08537 [cs.CV].
Negli ultimi anni, le reti neurali convoluzionali classiche (cCNN) hanno portato a notevoli progressi nella visione artificiale. Molti di questi algoritmi possono ora classificare gli oggetti in immagini di buona qualità con elevata precisione.
Però, nelle applicazioni del mondo reale, come la guida autonoma o la robotica, i dati di imaging raramente includono immagini scattate in condizioni di illuminazione ideali. Spesso, le immagini di cui le CNN avrebbero bisogno per elaborare presentano oggetti occlusi, distorsione del movimento, o bassi rapporti segnale/rumore (SNR), a causa della scarsa qualità dell'immagine o dei bassi livelli di luce.
Sebbene le cCNN siano state utilizzate con successo anche per ridurre il rumore delle immagini e migliorarne la qualità, queste reti non possono combinare informazioni da più fotogrammi o sequenze video e sono quindi facilmente superate dagli esseri umani su immagini di bassa qualità. Fino a S. Hartmann, un ricercatore di neuroscienze presso la Harvard Medical School, ha recentemente condotto uno studio che affronta questi limiti, introducendo un nuovo approccio della CNN per l'analisi delle immagini rumorose.
Hartmann, che ha un background in neuroscienze, ha trascorso oltre un decennio a studiare come gli esseri umani percepiscono ed elaborano le informazioni visive. Negli ultimi anni, divenne sempre più affascinato dalle somiglianze tra le CNN profonde utilizzate nella visione artificiale e il sistema visivo del cervello.
Nella corteccia visiva, area del cervello specializzata nell'elaborazione degli input visivi, la maggior parte delle connessioni neurali avviene in direzione laterale e di feedback. Ciò suggerisce che c'è molto di più nell'elaborazione visiva rispetto alle tecniche impiegate dalle cCNN. Ciò ha motivato Hartmann a testare i livelli convoluzionali che incorporano l'elaborazione ricorrente, che è vitale per l'elaborazione delle informazioni visive da parte del cervello umano.
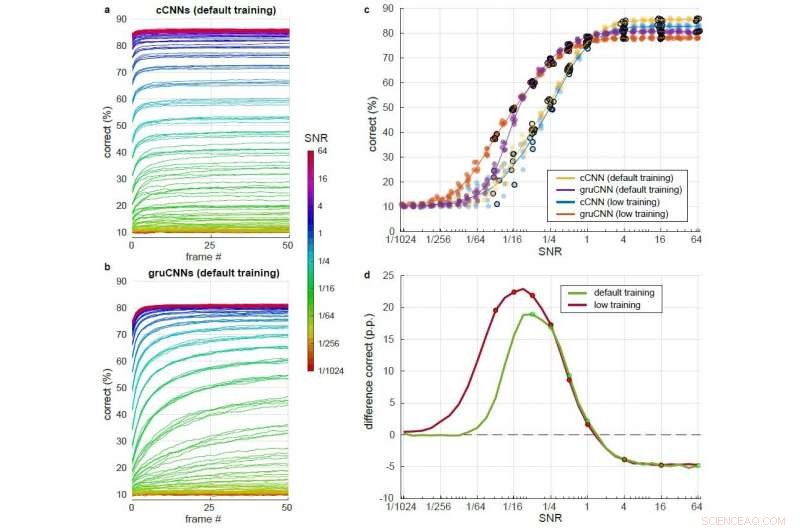
Confronto dettagliato di cCNN con l'inferenza bayesiana e le prestazioni di gruCNN su un'ampia gamma di livelli SNR. Ogni architettura del modello è stata testata dopo l'addestramento con SNR leggermente più alti (addestramento predefinito) e dopo l'allenamento con SNR leggermente più bassi (addestramento basso). a) &b) Percentuale corretta nel corso di 51 frame per diversi SNR (codificati a colori) utilizzando l'addestramento predefinito per a) cCNN (con inferenza bayesiana) eb) gruCNN. c) Dots:corretta classificazione delle architetture del modello all'ultimo frame. Jitter nei valori SNR è stato aggiunto per aumentare la leggibilità dei grafici, ma non era nei dati. Linee:prestazioni medie dei cinque modelli per architettura. d) Prestazioni medie delle gruCNN meno le prestazioni medie delle cCNN per i modelli addestrati con SNR predefiniti e inferiori (verde e rosso, rispettivamente). I livelli di SNR utilizzati durante l'allenamento sono indicati da punti. Credito:Till S. Hartmann/arXiv:1811.08537 [cs.CV].
Utilizzando connessioni ricorrenti all'interno dei livelli convoluzionali della CNN, L'approccio di Hartmann garantisce che le reti siano meglio attrezzate per elaborare il rumore dei pixel, come quello presente nelle immagini scattate in condizioni di scarsa illuminazione. Quando testato su sequenze video rumorose simulate, le CNN ricorrenti (gruCNN) si sono comportate molto meglio degli approcci classici, classificare con successo oggetti in video simulati di bassa qualità, come quelli presi di notte.
L'aggiunta di connessioni ricorrenti a un livello convoluzionale alla fine aggiunge memoria con vincoli spaziali, consentendo alla rete di apprendere come integrare le informazioni nel tempo prima che il segnale sia troppo astratto. Questa funzione può essere particolarmente utile quando la qualità del segnale è bassa, come nelle immagini rumorose o scattate in condizioni di scarsa illuminazione.
Nel suo studio, Hartmann ha scoperto che le cCNN si sono comportate bene su immagini con SNR elevati, gruCNN, li ha superati su immagini a basso SNR. Anche aggiungendo integrazioni temporali ottimali di Bayes, che consentono alle cCNN di integrare più frame di immagini, non corrispondeva alle prestazioni di gruCNN. Hartmann ha anche osservato che a bassi SNR, Le previsioni di gruCNN avevano livelli di confidenza più elevati rispetto a quelli prodotti dalle cCNN.
Mentre il cervello umano si è evoluto per vedere nell'oscurità, la maggior parte della CNN esistente non è ancora attrezzata per elaborare immagini sfocate o rumorose. Fornendo alle reti la capacità di integrare le immagini nel tempo, l'approccio ideato da Hartmann potrebbe eventualmente migliorare la visione artificiale al punto che corrisponde, o addirittura supera, prestazione umana. Questo potrebbe essere enorme per applicazioni come auto a guida autonoma e droni, così come in altre situazioni in cui una macchina ha bisogno di "vedere" in condizioni di illuminazione non ideali.
Lo studio condotto da Hartmann potrebbe aprire la strada allo sviluppo di CNN più avanzate in grado di analizzare le immagini scattate in condizioni di scarsa illuminazione. L'utilizzo di connessioni ricorrenti nelle prime fasi dell'elaborazione della rete neurale potrebbe migliorare notevolmente gli strumenti di visione artificiale, superare i limiti degli approcci classici della CNN nell'elaborazione di immagini rumorose o flussi video.
Come passo successivo, Hartmann potrebbe ampliare l'ambito della sua ricerca esplorando le applicazioni nella vita reale delle gruCNN, testandoli in una vasta gamma di scenari del mondo reale. potenzialmente, il suo approccio potrebbe essere utilizzato anche per migliorare la qualità di home video amatoriali o traballanti.
© 2018 Science X Network