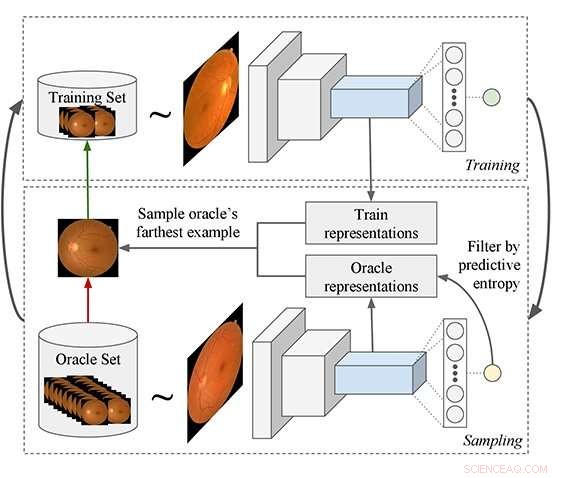
Pipeline di apprendimento attivo proposta:il processo inizia addestrando un modello e usandolo per eseguire query su esempi da un set di dati senza etichetta che vengono quindi aggiunti al set di addestramento. Viene proposta una nuova funzione di query che è più adatta per i modelli di Deep Learning (DL). Il modello DL viene utilizzato per estrarre funzionalità sia dall'oracolo che dagli esempi di training set, e quindi l'algoritmo filtra gli esempi di oracoli che hanno una bassa entropia predittiva. Finalmente, viene selezionato l'esempio oracolo che è in media il più distante nello spazio delle caratteristiche da tutti gli esempi di addestramento. Credito:Asim Smailagic
Man mano che i sistemi di intelligenza artificiale imparano a riconoscere e classificare meglio le immagini, stanno diventando altamente affidabili nella diagnosi delle malattie, come il cancro della pelle, da immagini mediche. Ma per quanto siano bravi a rilevare schemi, L'intelligenza artificiale non sostituirà il tuo medico a breve. Anche se usato come strumento, i sistemi di riconoscimento delle immagini richiedono ancora un esperto per etichettare i dati, e un sacco di dati a questo:ha bisogno di immagini sia di pazienti sani che di pazienti malati. L'algoritmo trova modelli nei dati di addestramento e quando riceve nuovi dati, utilizza ciò che ha appreso per identificare la nuova immagine.
Una sfida è che è lungo e costoso per un esperto ottenere ed etichettare ogni immagine. Per affrontare questo problema, un gruppo di ricercatori del College of Engineering della Carnegie Mellon University, tra cui i professori Hae Young Noh e Asim Smailagic, hanno collaborato per sviluppare una tecnica di apprendimento attivo che utilizza un set di dati limitato per ottenere un alto grado di accuratezza nella diagnosi di malattie come la retinopatia diabetica o il cancro della pelle.
Il modello dei ricercatori inizia a lavorare con una serie di immagini senza etichetta. Il modello decide quante immagini etichettare per avere un insieme solido e accurato di dati di addestramento. Sceglie un insieme iniziale di dati casuali da etichettare. Una volta etichettati i dati, traccia quei dati su una distribuzione perché le immagini variano in base all'età, Genere, proprietà fisica, ecc. Per prendere una buona decisione sulla base di questi dati, i campioni devono coprire un ampio spazio di distribuzione. Il sistema decide quindi quali nuovi dati devono essere aggiunti al set di dati, considerando l'attuale distribuzione dei dati.
"Il sistema misura quanto sia ottimale questa distribuzione, " ha detto No, un professore associato di ingegneria civile e ambientale, "e quindi calcola le metriche quando viene aggiunto un certo insieme di nuovi dati, e seleziona il nuovo set di dati che massimizza la sua ottimalità."
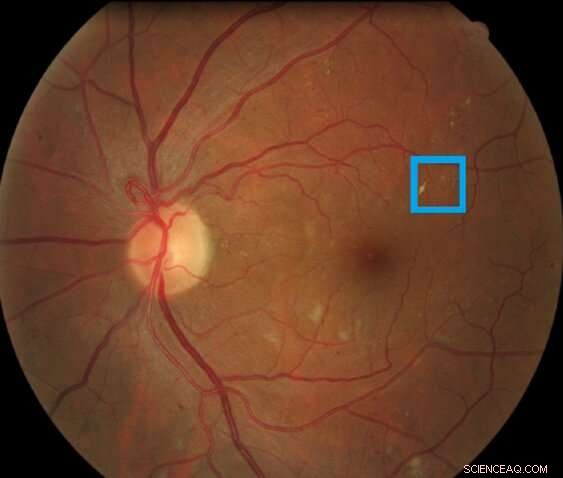
Immagine di una retina contenente una lesione retinica associata a retinopatia diabetica evidenziata nel riquadro. Questo tipo di lesione è chiamato microaneurisma. Credito:Asim Smailagic
Il processo viene ripetuto fino a quando l'insieme di dati ha una distribuzione sufficientemente buona da essere utilizzato come insieme di addestramento. Il loro metodo, chiamato MedAL (per l'apprendimento medico attivo), raggiunto l'80% di precisione nel rilevare la retinopatia diabetica, utilizzando solo 425 immagini etichettate, che è una riduzione del 32% del numero di esempi etichettati richiesti rispetto alla tecnica di campionamento dell'incertezza standard, e una riduzione del 40% rispetto al campionamento casuale.
Hanno anche testato il modello su altre malattie, comprese le immagini del cancro della pelle e del cancro al seno, per dimostrare che potrebbe applicarsi a una varietà di immagini mediche diverse. Il metodo è generalizzabile, poiché il suo obiettivo è come utilizzare i dati in modo strategico piuttosto che cercare di trovare un modello o una caratteristica specifica per una malattia. Potrebbe essere applicato anche ad altri problemi che utilizzano il deep learning ma hanno vincoli di dati.
"Il nostro approccio di apprendimento attivo combina il campionamento dell'incertezza basato sull'entropia predittivo e una funzione di distanza su uno spazio di funzionalità apprese per ottimizzare la selezione di campioni non etichettati, " disse Smailagic, un professore di ricerca presso l'Engineering Research Accelerator di Carnegie Mellon. "Il metodo supera i limiti degli approcci tradizionali selezionando in modo efficiente solo le immagini che forniscono la maggior parte delle informazioni sulla distribuzione complessiva dei dati, riducendo i costi di calcolo e aumentando sia la velocità che la precisione."
Il team includeva il dottorato di ricerca in ingegneria civile e ambientale. studenti Mostafa Mirshekari, Jonathan Fagert, e Susu Xu, e gli studenti di master in ingegneria elettrica e informatica Devesh Walawalkar e Kartik Khandelwal. Hanno presentato i loro risultati alla conferenza internazionale IEEE 2018 sull'apprendimento automatico e le applicazioni a dicembre, dove hanno ricevuto un Best Paper Award per il loro romanzo.