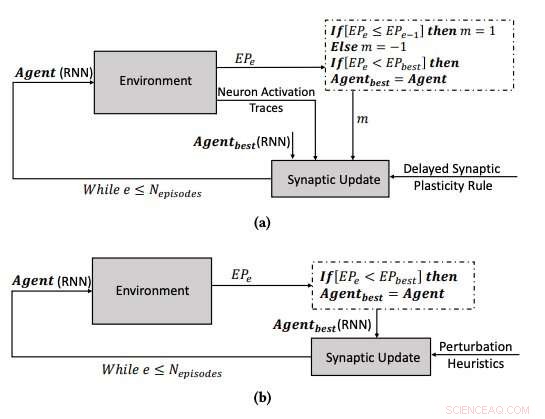
(a) Il processo di apprendimento che utilizza la plasticità sinaptica ritardata, e (b) il processo di apprendimento ottimizzando i parametri degli RNN utilizzando l'algoritmo di salita in salita. Credito:Yaman et al.
Il cervello umano cambia continuamente nel tempo, formare nuove connessioni sinaptiche basate su esperienze e informazioni apprese nel corso della vita. Negli ultimi anni, I ricercatori di intelligenza artificiale (AI) hanno cercato di riprodurre questa affascinante capacità, noto come 'plasticità, ' nelle reti neurali artificiali (ANN).
I ricercatori della Eindhoven University of Technology (Tu/e) e dell'Università di Trento hanno recentemente proposto un nuovo approccio ispirato ai meccanismi biologici che potrebbe migliorare l'apprendimento nelle RNA. Il loro studio, delineato in un documento pre-pubblicato su arXiv, è stato finanziato dal programma di ricerca e innovazione Horizon 2020 dell'Unione europea.
"Una delle proprietà affascinanti delle reti neurali biologiche (BNN) è la loro plasticità, che consente loro di apprendere modificando la propria configurazione in base all'esperienza, "Anil Yaman, uno dei ricercatori che ha condotto lo studio, ha detto a TechXplore. "Secondo l'attuale comprensione fisiologica, questi cambiamenti vengono eseguiti su singole sinapsi in base alle interazioni locali dei neuroni. Però, l'emergere di un comportamento di apprendimento globale coerente da queste interazioni individuali non è molto ben compreso."
Ispirato dalla plasticità dei BNN e dal suo processo evolutivo, Yaman e i suoi colleghi volevano imitare i meccanismi di apprendimento biologicamente plausibili nei sistemi artificiali. Per modellare la plasticità nelle RNA, i ricercatori di solito usano qualcosa chiamato regole di apprendimento hebbiane, che sono regole che aggiornano le sinapsi in base alle attivazioni neurali e ai segnali di rinforzo ricevuti dall'ambiente.

Diverse esecuzioni indipendenti dei processi di apprendimento utilizzando varie regole di plasticità sinaptica ritardata evolute (la migliore regola DSP è mostrata in verde). Credito:Yaman et al.
Quando i segnali di rinforzo non sono disponibili immediatamente dopo ogni uscita di rete, però, possono sorgere alcuni problemi, rendendo più difficile per la rete associare le attivazioni dei neuroni rilevanti con il segnale di rinforzo. Per superare questo problema, noto come "problema della ricompensa distale", ' i ricercatori hanno esteso le regole di plasticità hebbiane in modo da consentire l'apprendimento nei casi di ricompensa distale. Il loro approccio, chiamata plasticità sinaptica ritardata (DSP), usa qualcosa chiamato tracce di attivazione neuronale (NAT) per fornire spazio di archiviazione aggiuntivo in ogni sinapsi, oltre a tenere traccia delle attivazioni dei neuroni mentre la rete sta eseguendo un determinato compito.
"Le regole di plasticità sinaptica si basano sulle attivazioni locali dei neuroni e su un segnale di rinforzo, " Yaman ha spiegato. "Tuttavia, nella maggior parte dei problemi di apprendimento, i segnali di rinforzo vengono ricevuti dopo un certo periodo di tempo anziché immediatamente dopo ogni azione della rete. In questo caso, diventa problematico associare i segnali di rinforzo alle attivazioni dei neuroni. In questo lavoro, abbiamo proposto di utilizzare quelle che abbiamo chiamato "tracce di attivazione dei neuroni, ' per memorizzare le statistiche delle attivazioni dei neuroni in ogni sinapsi e informare le regole di plasticità sinaptica su come eseguire cambiamenti sinaptici ritardati."
Uno degli aspetti più significativi dell'approccio ideato da Yaman e dai suoi colleghi è che non presuppone informazioni globali sul problema che la rete neurale risolverà. Per di più, non dipende dalla specifica architettura ANN ed è quindi altamente generalizzabile.
"In termini pratici, il nostro studio può gettare le basi per nuovi schemi di apprendimento che possono essere utilizzati in una serie di applicazioni di reti neurali, come la robotica e i veicoli autonomi, e in generale in tutti i casi in cui un agente deve mettere in atto un comportamento adattivo in assenza di una ricompensa immediata ottenuta dalle sue azioni, "Giovanni Iacca, un altro ricercatore coinvolto nello studio, ha detto a TechXplore. "Per esempio, nell'intelligenza artificiale per i videogiochi, un'azione nell'attuale fase temporale potrebbe non portare necessariamente a una ricompensa in questo momento, ma solo dopo un po' di tempo; un agente che mostra annunci pubblicitari personalizzati potrebbe ottenere un "premio" dal comportamento dell'utente solo dopo un po' di tempo, eccetera.)."
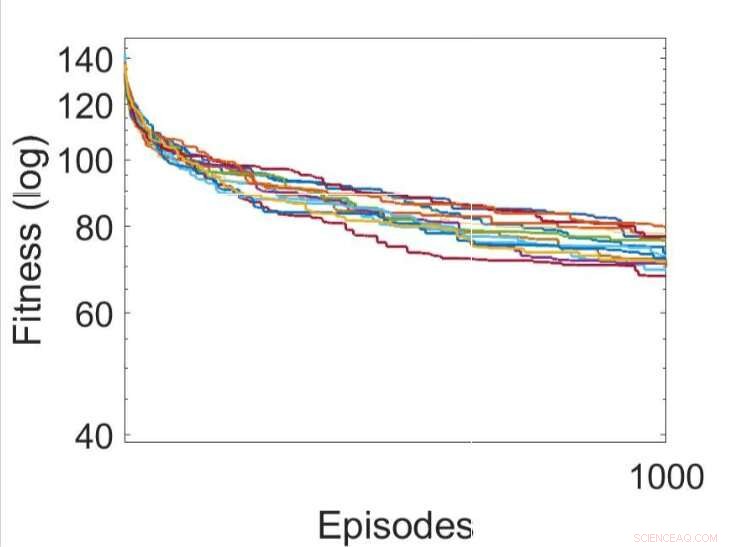
Diverse esecuzioni indipendenti dei processi di apprendimento ottimizzando i parametri degli RNN utilizzando l'algoritmo di arrampicata in collina. Credito:Yaman et al.
I ricercatori hanno testato le loro regole di plasticità hebbiane appena adattate in una simulazione di un ambiente a tripla T-labirinto. In questo ambiente, un agente controllato da una semplice rete neurale ricorrente (RNN) deve imparare a trovare una tra otto possibili posizioni obiettivo, partendo da una configurazione di rete casuale.
Yaman, Iacca e i loro colleghi hanno confrontato le prestazioni ottenute utilizzando il loro approccio con quelle ottenute quando un agente è stato addestrato utilizzando un analogo algoritmo di ricerca locale iterativo, chiamato alpinismo (HC). La differenza chiave tra l'algoritmo di arrampicata HC e il loro approccio è che il primo non utilizza alcuna conoscenza del dominio (cioè attivazioni locali di neuroni), mentre quest'ultimo lo fa.
I risultati raccolti dai ricercatori suggeriscono che gli aggiornamenti sinaptici eseguiti dalle loro regole DSP portano a un addestramento più efficace e, in definitiva, a prestazioni migliori rispetto all'algoritmo HC. Nel futuro, il loro approccio potrebbe aiutare a migliorare l'apprendimento a lungo termine nelle RNA, permettendo ai sistemi artificiali di costruire efficacemente nuove connessioni basate sulle loro esperienze.
"Siamo principalmente interessati a comprendere il comportamento emergente e le dinamiche di apprendimento delle reti neurali artificiali, e sviluppare un modello coerente per spiegare come si verifica la plasticità sinaptica in diversi scenari di apprendimento, " ha detto Yaman. "Penso che ci siano vaste possibilità per la ricerca futura in questo settore, per esempio sarà interessante ridimensionare l'approccio proposto a problemi complessi su larga scala (oltre a reti profonde) e ottenere meccanismi di apprendimento ispirati alla biologia che richiedono la minima quantità di supervisione (o nessuna)."
© 2019 Scienza X Rete