Credito:Ji Lin
Smartphone, telecamere di sicurezza, e gli altoparlanti sono solo alcuni dei dispositivi che presto eseguiranno più software di intelligenza artificiale per accelerare le attività di elaborazione delle immagini e del parlato. Una tecnica di compressione nota come quantizzazione sta spianando la strada riducendo i modelli di deep learning per ridurre i costi di calcolo e di energia. Ma modelli più piccoli, si scopre, rendere più facile per gli aggressori malintenzionati indurre un sistema di intelligenza artificiale a comportarsi in modo anomalo, una preoccupazione poiché il processo decisionale più complesso viene trasferito alle macchine.
In un nuovo studio, I ricercatori del MIT e di IBM mostrano quanto siano vulnerabili i modelli di intelligenza artificiale compressi agli attacchi avversari, e offrono una soluzione:aggiungere un vincolo matematico durante il processo di quantizzazione per ridurre le probabilità che un'intelligenza artificiale cada preda di un'immagine leggermente modificata e classifichi erroneamente ciò che vede.
Quando un modello di deep learning viene ridotto dai 32 bit standard a una lunghezza di bit inferiore, è più probabile che le immagini alterate vengano classificate erroneamente a causa di un effetto di amplificazione dell'errore:l'immagine manipolata diventa più distorta con ogni ulteriore livello di elaborazione. Alla fine, il modello ha maggiori probabilità di scambiare un uccello per un gatto, Per esempio, o una rana per un cervo.
I modelli quantizzati a 8 bit o meno sono più suscettibili agli attacchi contraddittori, i ricercatori mostrano, con una precisione che scende da un già basso 30-40 percento a meno del 10 percento man mano che la larghezza di bit diminuisce. Ma controllare il vincolo di Lipschitz durante la quantizzazione ripristina una certa resilienza. Quando i ricercatori hanno aggiunto il vincolo, hanno visto piccoli miglioramenti delle prestazioni in un attacco, con i modelli più piccoli in alcuni casi superando il modello a 32 bit.

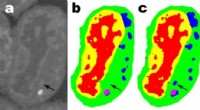
Quando alcuni pixel sono stati manipolati nelle immagini sopra per simulare un attacco contraddittorio, un modello standard compresso classificava erroneamente il pollo come "gatto" e la rana come "cervo". Ma quando i ricercatori hanno aggiunto un vincolo durante la compressione, il modello ha classificato correttamente gli animali, persino prestazioni migliori di un modello a 32 bit a piena precisione. Credito:Massachusetts Institute of Technology
"La nostra tecnica limita l'amplificazione degli errori e può persino rendere i modelli di deep learning compressi più robusti rispetto ai modelli a precisione completa, "dice Song Han, un assistente professore presso il Dipartimento di Ingegneria Elettrica e Informatica del MIT e membro dei Laboratori di tecnologia dei microsistemi del MIT. "Con la giusta quantizzazione, possiamo limitare l'errore".
Il team prevede di migliorare ulteriormente la tecnica addestrandola su set di dati più grandi e applicandola a una gamma più ampia di modelli. "I modelli di deep learning devono essere veloci e sicuri mentre si spostano in un mondo di dispositivi connessi a Internet, ", afferma il coautore dello studio Chuang Gan, un ricercatore presso il MIT-IBM Watson AI Lab. "La nostra tecnica di quantizzazione difensiva aiuta su entrambi i fronti."
I ricercatori, che includono lo studente laureato del MIT Ji Lin, presentare i loro risultati alla Conferenza internazionale sulle rappresentazioni dell'apprendimento a maggio.
Nel rendere i modelli di intelligenza artificiale più piccoli in modo che funzionino più velocemente e utilizzino meno energia, Han sta usando l'IA stessa per spingere i limiti della tecnologia di compressione dei modelli. In un recente lavoro correlato, Han e i suoi colleghi mostrano come l'apprendimento per rinforzo può essere utilizzato per trovare automaticamente la lunghezza di bit più piccola per ogni livello in un modello quantizzato in base alla velocità con cui il dispositivo che esegue il modello può elaborare le immagini. Questo approccio flessibile a larghezza di bit riduce la latenza e il consumo di energia fino al 200 percento rispetto a un fisso, modello a 8 bit, dice Han. I ricercatori presenteranno i loro risultati alla conferenza Computer Vision and Pattern Recognition di giugno.
Questa storia è stata ripubblicata per gentile concessione di MIT News (web.mit.edu/newsoffice/), un popolare sito che copre notizie sulla ricerca del MIT, innovazione e didattica.