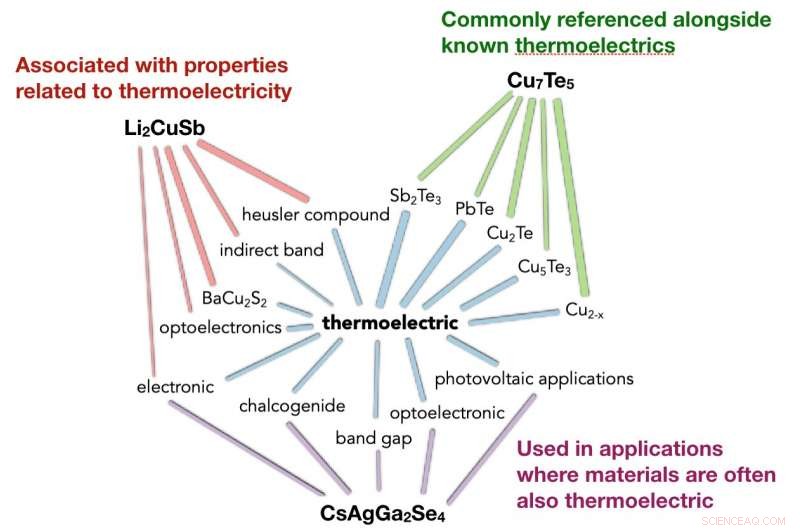
I ricercatori del Berkeley Lab hanno scoperto che il text mining di abstract di scienza dei materiali potrebbe far emergere nuovi materiali termoelettrici. Credito:Berkeley Lab
Sicuro, i computer possono essere utilizzati per giocare a scacchi di livello Grandmaster (chess_computer), ma possono fare scoperte scientifiche? I ricercatori del Lawrence Berkeley National Laboratory (Berkeley Lab) del Dipartimento dell'energia degli Stati Uniti hanno dimostrato che un algoritmo senza alcuna formazione nella scienza dei materiali può scansionare il testo di milioni di articoli e scoprire nuove conoscenze scientifiche.
Una squadra guidata da Anubhav Jain, uno scienziato della divisione Energy Storage &Distributed Resources di Berkeley Lab, ha raccolto 3,3 milioni di abstract di articoli pubblicati sulla scienza dei materiali e li ha inseriti in un algoritmo chiamato Word2vec. Analizzando le relazioni tra le parole, l'algoritmo è stato in grado di prevedere le scoperte di nuovi materiali termoelettrici con anni di anticipo e suggerire materiali ancora sconosciuti come candidati per i materiali termoelettrici.
"Senza dire nulla sulla scienza dei materiali, ha appreso concetti come la tavola periodica e la struttura cristallina dei metalli, " ha detto Jain. "Questo ha suggerito il potenziale della tecnica. Ma probabilmente la cosa più interessante che abbiamo capito è che puoi usare questo algoritmo per colmare le lacune nella ricerca sui materiali, cose che le persone dovrebbero studiare ma non hanno studiato finora."
I risultati sono stati pubblicati il 3 luglio sulla rivista Natura . L'autore principale dello studio, "Gli incorporamenti di parole non supervisionati acquisiscono la conoscenza latente dalla letteratura sulla scienza dei materiali, " è Vahe Tshitoyan, un borsista post-dottorato del Berkeley Lab che ora lavora presso Google. Insieme a Jain, Gli scienziati del Berkeley Lab Kristin Persson e Gerbrand Ceder hanno contribuito a condurre lo studio.
"Il documento stabilisce che il text mining della letteratura scientifica può scoprire conoscenze nascoste, e che la pura estrazione basata sul testo può stabilire conoscenze scientifiche di base, "disse Cedro, che ha anche un appuntamento presso il Dipartimento di Scienza e Ingegneria dei Materiali dell'UC Berkeley.
Tshitoyan ha affermato che il progetto è stato motivato dalla difficoltà di dare un senso alla schiacciante quantità di studi pubblicati. "In ogni campo di ricerca ci sono 100 anni di letteratura di ricerca passata, e ogni settimana escono dozzine di studi in più, " ha detto. "Un ricercatore può accedere solo a una frazione di quello. Abbiamo pensato, può l'apprendimento automatico fare qualcosa per utilizzare tutta questa conoscenza collettiva in modo non supervisionato, senza bisogno della guida di ricercatori umani?"
'Re-regina + uomo =?'
Il team ha raccolto i 3,3 milioni di abstract da articoli pubblicati in più di 1, 000 riviste tra il 1922 e il 2018. Word2vec ha preso ciascuna delle circa 500, 000 parole distinte in quegli abstract e trasformate ciascuna in un vettore a 200 dimensioni, o un array di 200 numeri.
"Ciò che è importante non è ogni numero, ma usando i numeri per vedere come le parole sono collegate tra loro, " ha detto Giain, che guida un gruppo che lavora alla scoperta e alla progettazione di nuovi materiali per applicazioni energetiche utilizzando un mix di teoria, calcolo, e data mining. "Ad esempio puoi sottrarre vettori usando la matematica vettoriale standard. Altri ricercatori hanno dimostrato che se alleni l'algoritmo su fonti di testo non scientifiche e prendi il vettore che risulta da "re meno regina, ' ottieni lo stesso risultato di 'uomo meno donna.' Capisce la relazione senza che tu gli dica nulla".
Allo stesso modo, quando addestrato sul testo di scienza dei materiali, l'algoritmo è stato in grado di apprendere il significato di termini e concetti scientifici come la struttura cristallina dei metalli basandosi semplicemente sulle posizioni delle parole negli abstract e sulla loro co-occorrenza con altre parole. Per esempio, proprio come potrebbe risolvere l'equazione "re-regina + uomo, " potrebbe capire che per l'equazione "ferromagnetico—NiFe + IrMn" la risposta sarebbe "antiferromagnetica".
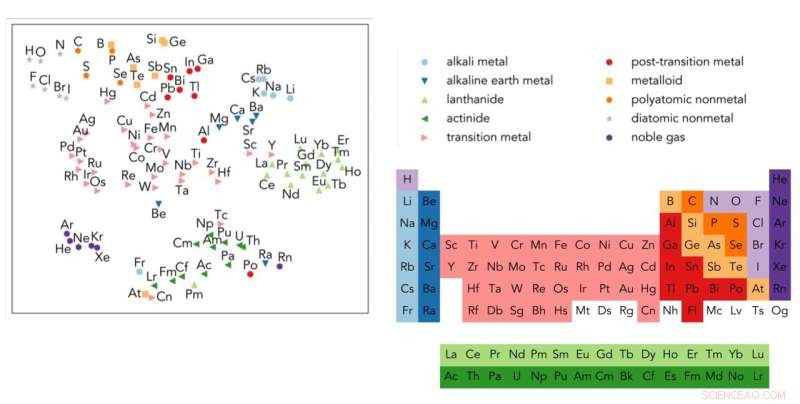
La tavola periodica di Mendeleev è sulla destra. La rappresentazione degli elementi di Word2vec, proiettato su due dimensioni, è a sinistra. Credito:Berkeley Lab
Word2vec è stato persino in grado di apprendere le relazioni tra gli elementi sulla tavola periodica quando il vettore per ciascun elemento chimico è stato proiettato su due dimensioni.
Prevedere le scoperte con anni di anticipo
Quindi, se Word2vec è così intelligente, potrebbe prevedere nuovi materiali termoelettrici? Un buon materiale termoelettrico può convertire efficacemente il calore in elettricità ed è realizzato con materiali sicuri, abbondante e di facile produzione.
Il team del Berkeley Lab ha preso i migliori candidati termoelettrici suggeriti dall'algoritmo, che classificava ciascun composto in base alla somiglianza del suo vettore di parole con quello della parola "termoelettrico". Quindi hanno eseguito calcoli per verificare le previsioni dell'algoritmo.
Dei primi 10 pronostici, hanno scoperto che tutti avevano calcolato fattori di potenza leggermente superiori alla media dei termoelettrici noti; i primi tre candidati avevano fattori di potenza superiori al 95esimo percentile dei termoelettrici conosciuti.
Successivamente hanno testato se l'algoritmo potesse eseguire esperimenti "nel passato" dandogli astratti solo fino a, dire, l'anno 2000. Ancora una volta, delle migliori previsioni, un numero significativo è emerso negli studi successivi, quattro volte di più che se i materiali fossero stati scelti a caso. Per esempio, tre delle prime cinque previsioni formate utilizzando i dati fino all'anno 2008 sono state scoperte da allora e le restanti due contengono elementi rari o tossici.
I risultati sono stati sorprendenti. "Sinceramente non mi aspettavo che l'algoritmo fosse così predittivo dei risultati futuri, " ha detto Jain. "Avevo pensato che forse l'algoritmo potrebbe essere descrittivo di ciò che la gente aveva fatto prima, ma non è venuto fuori con queste diverse connessioni. Sono rimasto piuttosto sorpreso quando ho visto non solo le previsioni ma anche il ragionamento dietro le previsioni, cose come la struttura di mezzo Heusler, che è una struttura cristallina davvero calda per i termoelettrici in questi giorni."
Ha aggiunto:"Questo studio mostra che se questo algoritmo fosse stato applicato prima, alcuni materiali potrebbero essere stati scoperti con anni di anticipo". Insieme allo studio, i ricercatori stanno rilasciando i primi 50 materiali termoelettrici previsti dall'algoritmo. Rilasceranno anche gli incorporamenti di parole necessari per consentire alle persone di realizzare le proprie applicazioni, se lo desiderano. su cui cercare, dire, un miglior materiale isolante topologico.
Avanti il prossimo, Jain ha detto che il team sta lavorando a una soluzione più intelligente, motore di ricerca più potente, consentendo ai ricercatori di cercare abstract in un modo più utile.
Lo studio è stato finanziato dal Toyota Research Institute. Altri coautori dello studio sono i ricercatori del Berkeley Lab John Dagdelen, Leigh Weston, Alexander Dunn, e Ziqin Rong, e la ricercatrice dell'UC Berkeley Olga Kononova.