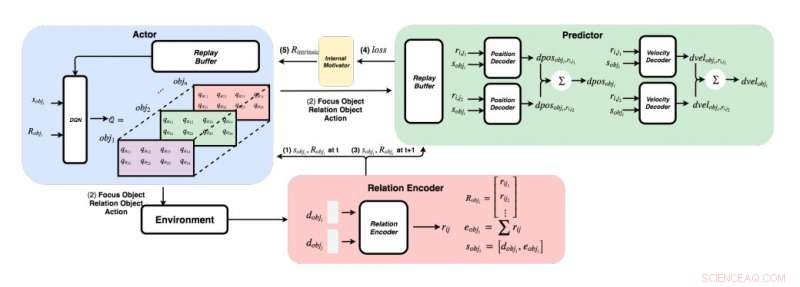
Un diagramma dettagliato dell'approccio sviluppato dai ricercatori. (In basso a destra) Per ogni coppia di oggetti, i ricercatori inseriscono le loro caratteristiche in un codificatore di relazioni per ottenere la relazione rij e lo stato dell'oggetto i sobji. (In alto a sinistra) Utilizzando il metodo greedy, per ogni oggetto, trovano il valore Q massimo per ottenere il nostro oggetto focus, oggetto di relazione, e azione. (In alto a destra) Una volta che hanno raccolto l'oggetto focus e l'oggetto relazione, alimentano i loro stati e tutte le loro relazioni ai loro decodificatori per prevedere il cambiamento di posizione e il cambiamento di velocità. Credito:Choi &Yoon.
Fin dai primi anni di vita, gli esseri umani hanno la capacità innata di apprendere continuamente e costruire modelli mentali del mondo, semplicemente osservando e interagendo con cose o persone nell'ambiente circostante. Gli studi di psicologia cognitiva suggeriscono che gli esseri umani fanno ampio uso di questa conoscenza precedentemente acquisita, in particolare quando incontrano nuove situazioni o quando prendono decisioni.
Nonostante i recenti progressi significativi nel campo dell'intelligenza artificiale (AI), la maggior parte degli agenti virtuali richiede ancora centinaia di ore di formazione per ottenere prestazioni a livello umano in diverse attività, mentre gli umani possono imparare a completare queste attività in poche ore o meno. Recenti studi hanno evidenziato due fattori chiave per la capacità degli esseri umani di acquisire conoscenze così rapidamente, vale a dire, fisica intuitiva e psicologia intuitiva.
Questi modelli di intuizione, che sono stati osservati negli esseri umani fin dalle prime fasi dello sviluppo, potrebbero essere i principali facilitatori dell'apprendimento futuro. Sulla base di questa idea, i ricercatori del Korea Advanced Institute of Science and Technology (KAIST) hanno recentemente sviluppato un metodo di normalizzazione della ricompensa intrinseca che consente agli agenti di intelligenza artificiale di selezionare le azioni che migliorano maggiormente i loro modelli di intuizione. Nella loro carta, pre-pubblicato su arXiv, i ricercatori hanno proposto specificamente una rete di fisica grafica integrata con l'apprendimento per rinforzo profondo ispirato al comportamento di apprendimento osservato nei neonati umani.
"Immagina i bambini umani in una stanza con i giocattoli in giro a una distanza raggiungibile, " spiegano i ricercatori nel loro articolo. "Afferrano costantemente, lanciare ed eseguire azioni su oggetti; A volte, osservano le conseguenze delle loro azioni, ma a volte, perdono interesse e passano a un oggetto diverso. La visione del "bambino come scienziato" suggerisce che i bambini umani sono intrinsecamente motivati a condurre i propri esperimenti, scopri maggiori informazioni, e alla fine impara a distinguere oggetti diversi e a crearne rappresentazioni interne più ricche."
Gli studi di psicologia suggeriscono che nei primi anni di vita, gli esseri umani sperimentano continuamente con l'ambiente circostante, e questo permette loro di formare una comprensione chiave del mondo. Inoltre, quando i bambini osservano risultati che non soddisfano le loro aspettative precedenti, che è nota come violazione dell'aspettativa, sono spesso incoraggiati a sperimentare ulteriormente per ottenere una migliore comprensione della situazione in cui si trovano.
Il team di ricercatori di KAIST ha cercato di riprodurre questi comportamenti negli agenti di intelligenza artificiale utilizzando un approccio di apprendimento per rinforzo. Nel loro studio, hanno introdotto per la prima volta una rete fisica grafica in grado di estrarre le relazioni fisiche tra gli oggetti e prevedere i loro comportamenti successivi in un ambiente 3D. Successivamente, hanno integrato questa rete con un modello di apprendimento di rinforzo profondo, introducendo una tecnica di normalizzazione della ricompensa intrinseca che incoraggia un agente di intelligenza artificiale a esplorare e identificare azioni che miglioreranno continuamente il suo modello di intuizione.
Utilizzando un motore fisico 3D, i ricercatori hanno dimostrato che la loro rete fisica grafica può dedurre in modo efficiente le posizioni e le velocità di diversi oggetti. Hanno anche scoperto che il loro approccio ha permesso alla rete di apprendimento per rinforzo profondo di migliorare continuamente il suo modello di intuizione, incoraggiandolo ad interagire con gli oggetti unicamente sulla base di motivazioni intrinseche.
In una serie di valutazioni, la nuova tecnica ideata da questo team di ricercatori ha raggiunto una notevole precisione, con l'agente AI che esegue un numero maggiore di diverse azioni esplorative. Nel futuro, potrebbe informare lo sviluppo di strumenti di apprendimento automatico in grado di apprendere dalle esperienze passate in modo più rapido ed efficace.
"Abbiamo testato la nostra rete su problemi sia stazionari che non stazionari in varie scene con oggetti sferici con masse e raggi variabili, " spiegano i ricercatori nel loro articolo. "La nostra speranza è che questi modelli di intuizione pre-addestrati vengano successivamente utilizzati come conoscenza preliminare per altre attività orientate agli obiettivi come i giochi ATARI o la previsione video".
© 2019 Scienza X Rete