Credito:Università di Copenaghen
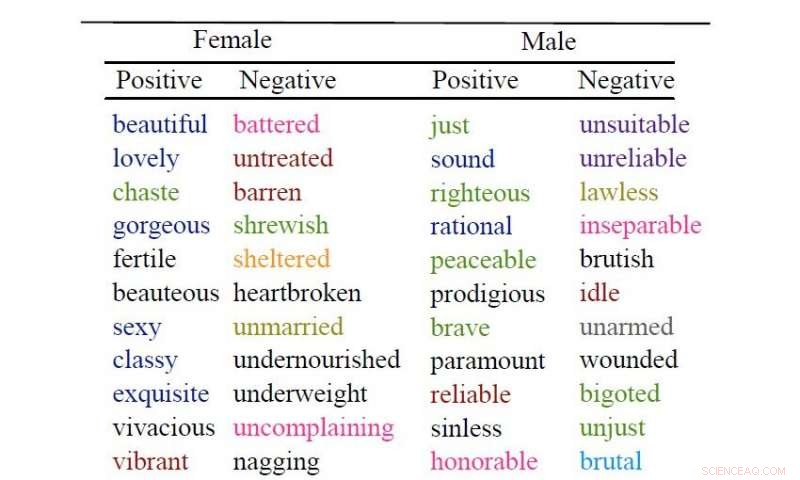
Gli uomini sono tipicamente descritti da parole che si riferiscono al comportamento, mentre gli aggettivi attribuiti alle donne tendono ad essere associati all'aspetto fisico. Questo, secondo un gruppo di scienziati informatici dell'Università di Copenaghen e di altre università che hanno utilizzato l'apprendimento automatico per analizzare 3,5 milioni di libri.
"Bello" e "sexy" sono due degli aggettivi più usati per descrivere le donne. I descrittori comunemente usati per gli uomini includono "giusto, "'razionale' e 'coraggioso".
Un informatico dell'Università di Copenaghen, insieme ad altri ricercatori degli Stati Uniti, ha spulciato un'enorme quantità di libri nel tentativo di scoprire se c'è una differenza tra i tipi di parole usate per descrivere uomini e donne in letteratura. Utilizzando un nuovo modello di computer, i ricercatori hanno analizzato un set di dati di 3,5 milioni di libri, tutti pubblicati in inglese tra il 1900 e il 2008. I libri includono un mix di narrativa e saggistica.
"Siamo chiaramente in grado di vedere che le parole usate per le donne si riferiscono molto di più alle loro apparenze rispetto alle parole usate per descrivere gli uomini. Quindi, abbiamo potuto confermare una percezione diffusa, solo ora a livello statistico, ", afferma la scienziata informatica e assistente professoressa Isabelle Augenstein del Dipartimento di informatica dell'Università di Copenaghen.
I ricercatori hanno estratto aggettivi e verbi associati a nomi di genere (ad esempio "figlia" e "hostess"). Per esempio, in combinazioni come "sexy hostess" o "girls gossiping". Hanno poi analizzato se le parole avevano un positivo, sentimento negativo o neutro, e successivamente in quali categorie le parole potrebbero essere suddivise.
Le loro analisi dimostrano che i verbi negativi associati al corpo e all'aspetto sono usati con una frequenza cinque volte superiore per le femmine rispetto ai maschi. Le analisi dimostrano anche che gli aggettivi positivi e neutri relativi al corpo e all'aspetto si verificano circa il doppio delle volte nelle descrizioni delle donne, mentre i maschi sono più frequentemente descritti utilizzando aggettivi che si riferiscono al loro comportamento e alle loro qualità personali.
Nel passato, i linguisti in genere hanno esaminato la prevalenza del linguaggio e dei pregiudizi di genere, ma utilizzando set di dati più piccoli. Ora, gli scienziati informatici sono in grado di implementare algoritmi di apprendimento automatico per analizzare vaste raccolte di dati, in questo caso, 11 miliardi di parole.
Nuova vita per vecchi stereotipi di genere
Sebbene molti dei libri siano stati pubblicati diversi decenni fa, svolgono ancora un ruolo attivo, sottolinea Isabelle Augenstein. Gli algoritmi utilizzati per creare macchine e applicazioni in grado di comprendere il linguaggio umano vengono alimentati con dati sotto forma di materiale testuale disponibile online. Questa è la tecnologia che consente agli smartphone di riconoscere le nostre voci e consente a Google di fornire suggerimenti di parole chiave.
"Gli algoritmi lavorano per identificare modelli, e ogni volta che si osserva, si percepisce che qualcosa è "vero". anche il risultato sarà distorto. I sistemi adottano, per così dire, il linguaggio che usiamo noi persone, e quindi, i nostri stereotipi e pregiudizi di genere, "dice Isabelle Augenstein, e fornisce un esempio di dove può essere importante:
"Se il linguaggio che usiamo per descrivere uomini e donne è diverso, nelle raccomandazioni dei dipendenti, ad esempio, influenzerà chi viene offerto un lavoro quando le aziende utilizzano i sistemi IT per smistare le domande di lavoro."
Man mano che l'intelligenza artificiale e la tecnologia del linguaggio diventano più importanti nella società, è importante essere consapevoli del linguaggio di genere.
Augenstein continua:"Possiamo provare a tenerne conto durante lo sviluppo di modelli di apprendimento automatico utilizzando un testo meno distorto o forzando i modelli a ignorare o contrastare i pregiudizi. Tutte e tre le cose sono possibili".
I ricercatori sottolineano che l'analisi ha i suoi limiti, in quanto non tiene conto di chi ha scritto i singoli passaggi e delle differenze nei gradi di distorsione a seconda che i libri siano stati pubblicati in un periodo precedente o successivo all'interno della linea temporale del set di dati. Per di più, non fa distinzione tra i generi, ad es. tra romanzi rosa e saggistica. I ricercatori stanno attualmente seguendo diversi di questi elementi.














