Credito:Università di York
Le reti neurali convoluzionali profonde (DCNN) non vedono gli oggetti come fanno gli esseri umani, utilizzando la percezione della forma configurale, e ciò potrebbe essere pericoloso nelle applicazioni di intelligenza artificiale del mondo reale, afferma il professor James Elder, coautore di uno studio della York University pubblicato oggi.
Pubblicato sulla rivista Cell Press iScience , I modelli di deep learning non riescono a catturare la natura configurale della percezione della forma umana è uno studio collaborativo di Elder, che detiene la York Research Chair in Human and Computer Vision ed è co-direttore del Center for AI &Society di York, e assistente professore di psicologia Nicholas Baker al Loyola College di Chicago, ex borsista post-dottorato VISTA a York.
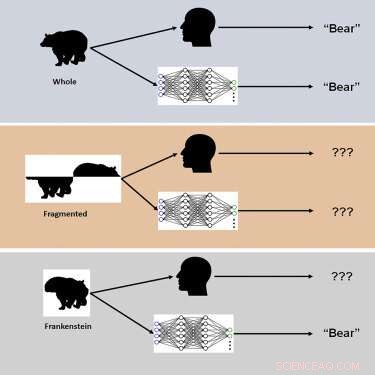
Lo studio ha utilizzato nuovi stimoli visivi chiamati "Frankenstein" per esplorare il modo in cui il cervello umano e i DCNN elaborano proprietà olistiche e configurali degli oggetti.
"I Frankenstein sono semplicemente oggetti che sono stati smontati e rimontati nel modo sbagliato", afferma Elder. "Di conseguenza, hanno tutte le caratteristiche locali giuste, ma nei posti sbagliati".
I ricercatori hanno scoperto che mentre il sistema visivo umano è confuso dai Frankenstein, i DCNN non lo stanno rivelando, rivelando un'insensibilità alle proprietà degli oggetti configurabili.
"I nostri risultati spiegano perché i modelli di intelligenza artificiale profonda falliscono in determinate condizioni e indicano la necessità di considerare compiti oltre il riconoscimento degli oggetti per comprendere l'elaborazione visiva nel cervello", afferma Elder. "Questi modelli profondi tendono a prendere 'scorciatoie' quando risolvono complesse attività di riconoscimento. Sebbene queste scorciatoie possano funzionare in molti casi, possono essere pericolose in alcune delle applicazioni di intelligenza artificiale del mondo reale su cui stiamo attualmente lavorando con i nostri partner industriali e governativi, " fa notare Elder.
Una di queste applicazioni sono i sistemi di videosorveglianza del traffico:"Gli oggetti in una scena di traffico trafficata - i veicoli, le biciclette ei pedoni - si ostacolano a vicenda e arrivano all'occhio di un guidatore come un miscuglio di frammenti disconnessi", spiega Elder. "Il cervello ha bisogno di raggruppare correttamente quei frammenti per identificare le categorie e le posizioni corrette degli oggetti. Un sistema di intelligenza artificiale per il monitoraggio della sicurezza del traffico che è in grado di percepire i frammenti solo individualmente fallirà in questo compito, potenzialmente fraintendendo i rischi per gli utenti della strada vulnerabili. "
Secondo i ricercatori, le modifiche alla formazione e all'architettura volte a rendere le reti più simili al cervello non hanno portato all'elaborazione della configurazione e nessuna delle reti è stata in grado di prevedere con precisione i giudizi sugli oggetti umani prova per prova. "Ipotizziamo che, per soddisfare la sensibilità della configurazione umana, le reti debbano essere addestrate a risolvere una gamma più ampia di compiti degli oggetti oltre il riconoscimento delle categorie", osserva Elder. + Esplora ulteriormente