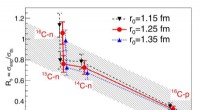
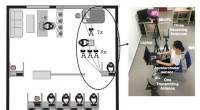
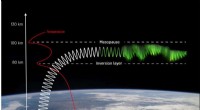
- Pre-elaborazione:
1. Le immagini vengono ridimensionate a una risoluzione fissa.
2. La normalizzazione del colore viene applicata per rimuovere le variazioni di illuminazione.
- Estrazione di funzionalità:
1. Le reti neurali convoluzionali profonde (CNN) vengono utilizzate per estrarre caratteristiche potenti e discriminanti dalle immagini.
2. L'architettura della CNN è addestrata su un ampio set di dati di immagini con etichette di testo associate.
- Generazione di sottotitoli:
1. Una rete neurale ricorrente (RNN) viene utilizzata per generare didascalie per le immagini in base alle caratteristiche estratte.
2. L'RNN è addestrato a massimizzare la probabilità della didascalia corretta date le caratteristiche dell'immagine.
- Modello linguistico:
1. Viene utilizzato un modello linguistico aggiuntivo per migliorare la correttezza grammaticale e la fluidità dei sottotitoli generati.
2. Il modello linguistico viene addestrato su un ampio corpus di dati di testo.
Algoritmo:
1. Inserimento:
- Immagine
- Modello CNN pre-addestrato
- Modello RNN pre-addestrato
- Modello linguistico
2. Passaggi:
1. Ridimensionare e normalizzare il colore dell'immagine in ingresso.
2. Estrai le caratteristiche profonde dall'immagine utilizzando il modello CNN.
3. Genera una didascalia iniziale per l'immagine utilizzando il modello RNN.
4. Perfezionare la didascalia applicando il modello linguistico.
5. Uscita:
- Una didascalia in linguaggio naturale per l'immagine di input.
Set di dati:
- COCO (Common Objects in Context):un set di dati di immagini su larga scala con annotazioni di oggetti e didascalie di testo.
- Flickr8k:un set di dati di 8.000 immagini con didascalie scritte da persone.
- Flickr30k:un set di dati più ampio con 30.000 immagini e didascalie scritte da persone.
Valutazione:
- Metriche:
- BLEU (Bilingual Evaluation Understudy):misura la somiglianza tra i sottotitoli generati e i sottotitoli di riferimento scritti da persone.
- METEOR (metrica per la valutazione della traduzione con ordinamento esplicito):un'altra misura di somiglianza tra le didascalie generate e quelle di riferimento.
- CIDEr (Consensus-based Image Description Evaluation):una metrica che tiene conto del consenso tra più giudici umani.