I filamenti proposti di materia oscura che circondano Giove potrebbero far parte del misterioso 95% dell'energia di massa dell'universo. Credito:NASA/JPL-Caltech
La maggior parte dell'universo è buio, con la materia oscura e l'energia oscura che costituiscono oltre il 95% della sua energia di massa. Eppure sappiamo poco della materia oscura e dell'energia. Per trovare risposte, gli scienziati eseguono enormi esperimenti di fisica ad alta energia. L'analisi dei risultati richiede un calcolo ad alte prestazioni, a volte bilanciato con le tendenze industriali.
Dopo quattro anni di calcolo per l'esperimento Large Hadron Collider CMS al CERN vicino a Ginevra, Svizzera – parte del lavoro che ha rivelato il bosone di Higgs – Oliver Gutsche, uno scienziato presso il Fermi National Accelerator Laboratory del Dipartimento dell'Energia (DOE), rivolto alla ricerca della materia oscura. "Il bosone di Higgs era stato predetto, e sapevamo approssimativamente dove guardare, " dice. "Con la materia oscura, non sappiamo cosa stiamo cercando".
Per conoscere la materia oscura, Gutsche ha bisogno di più dati. Una volta che tali informazioni sono disponibili, i fisici devono estrarlo. Stanno esplorando strumenti computazionali per il lavoro, incluso il software open source Apache Spark.
Alla ricerca della materia oscura, i fisici studiano i risultati della collisione di particelle. "Questo è banale da parallelizzare, " rompere il lavoro in pezzi per ottenere risposte più velocemente, spiega Gutsche. "Due PC possono elaborare ciascuno una collisione, " significa che i ricercatori possono utilizzare una griglia di computer per analizzare i dati.
Gran parte del lavoro nella fisica delle alte energie, anche se, dipende dal software sviluppato dagli scienziati. "Se i nostri studenti laureati e postdoc conoscono solo i nostri strumenti proprietari, allora avranno problemi se vanno all'industria, " se tale software non è disponibile, Note di Gutsche. "Così ho iniziato a esaminare Spark."
Spark è uno strumento di riduzione dei dati creato per file di testo non strutturati. Ciò crea una sfida:accedere ai dati della fisica delle alte energie, che sono in un formato orientato agli oggetti. I ricercatori di informatica del Fermilab Saba Sehrish e Jim Kowalkowski stanno affrontando il compito.
Spark ha offerto una promessa fin dall'inizio, con alcune caratteristiche particolarmente interessanti, Sehrish dice. "Uno era in memoria, elaborazione distribuita su larga scala" attraverso interfacce di alto livello, che lo rende facile da usare. "Non vuoi che gli scienziati si preoccupino di come distribuire i dati e scrivere codice parallelo, " dice. Spark si occupa di questo.
Un'altra caratteristica interessante:Spark è una piattaforma di ricerca supportata presso il National Energy Research Scientific Computing Center (NERSC), una struttura per gli utenti dell'Office of Science del DOE presso il Lawrence Berkeley National Laboratory del DOE. "Questo ci dà un team di supporto che può metterlo a punto, " dice Kowalkowski. Gli informatici come Sehrish e Kowalkowski possono aggiungere capacità, ma far funzionare il codice sottostante nel modo più efficiente possibile richiede specialisti Spark, alcuni dei quali lavorano al NERSC.
Kowalkowski riassume le caratteristiche desiderabili di Spark come "ridimensionamento automatico, parallelismo automatizzato e un modello di programmazione ragionevole."
In breve, lui e Sehrish vogliono costruire un sistema che permetta ai ricercatori di eseguire un'analisi che funzioni molto bene su macchine di grandi dimensioni senza complicazioni e attraverso una semplice interfaccia utente.
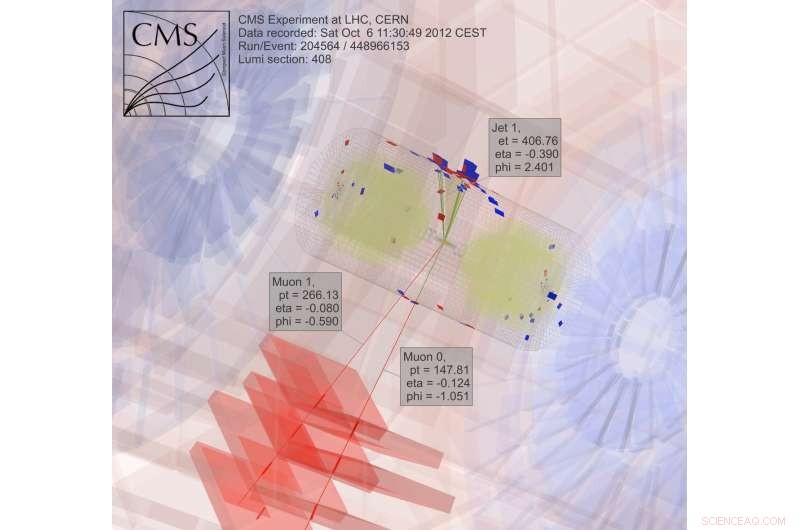
Per cercare la materia oscura, gli scienziati raccolgono e analizzano i risultati delle particelle in collisione, un processo estremamente intenso dal punto di vista computazionale. Credito:CMS CERN
Semplicemente facile da usare, anche se, non è sufficiente quando si tratta di dati della fisica delle alte energie. Spark sembra soddisfare in una certa misura sia gli obiettivi di facilità d'uso che di prestazioni. I ricercatori stanno ancora studiando alcuni aspetti delle sue prestazioni per applicazioni di fisica delle alte energie, ma gli informatici non possono avere tutto. "C'è un compromesso, " Sehrish afferma. "Quando cerchi più prestazioni, non hai facilità d'uso."
Gli scienziati del Fermilab hanno scelto Spark come scelta iniziale per esplorare la scienza dei big data, e la materia oscura è solo la prima applicazione in fase di test. "Abbiamo bisogno di diversi casi di utilizzo reale per comprendere la fattibilità dell'utilizzo di Spark per un'attività di analisi, " Dice Sehrish. Con scienziati come Gutsche al Fermilab, la materia oscura era un buon punto di partenza. Sehrish e Kowalkowski vogliono semplificare la vita degli scienziati che eseguono l'analisi. "Lavoriamo con gli scienziati per comprendere i loro dati e lavorare con le loro analisi, " Sehrish dice. "Allora possiamo aiutarli a organizzare meglio i set di dati, organizzare meglio le attività di analisi."
Come primo passo in tale processo, Sehrish e Kowalkowski devono ottenere dati da esperimenti di fisica ad alta energia in Spark. Note Kowalkowski, "Hai petabyte di dati in formati sperimentali specifici che devi trasformare in qualcosa di utile per un'altra piattaforma".
I dati di partenza per l'implementazione della materia oscura sono formattati per piattaforme di elaborazione ad alto rendimento, ma Spark non gestisce quella configurazione. Quindi il software deve leggere il formato dati originale e convertirlo in qualcosa che funzioni bene con Spark.
Nel fare ciò, Sehrish spiega, "Devi considerare ogni decisione ad ogni passo, perché come strutturi i dati, il modo in cui lo leggi in memoria e progetti e implementi operazioni per alte prestazioni è tutto collegato."
Ciascuno di questi passaggi di gestione dei dati influisce sulle prestazioni di Spark. Sebbene sia troppo presto per dire quante prestazioni possono essere ottenute da Spark durante l'analisi dei dati sulla materia oscura, Sehrish e Kowalkowski vedono che Spark può fornire un codice intuitivo che consente ai ricercatori di fisica ad alta energia di avviare un lavoro su centinaia di migliaia di core. "Spark è buono in questo senso, " Dice Sehrish. "Abbiamo anche riscontrato una buona scalabilità, senza sprecare risorse di elaborazione poiché aumentiamo le dimensioni del set di dati e il numero di nodi".
Nessuno sa se questo sarà un approccio praticabile fino a quando non si determineranno le prestazioni di picco di Spark per queste applicazioni. "La chiave principale, " dice Kowalkowski, "è che non siamo ancora convinti che questa sia la tecnologia per andare avanti".
Infatti, Spark stessa cambia. Il suo ampio uso open-source crea un ciclo di sviluppo costante e rapido. Quindi Sehrish e Kowalkowski devono mantenere il loro codice aggiornato con le nuove capacità di Spark.
"Il ciclo costante di crescita con Spark è il costo di lavorare con la tecnologia di fascia alta e qualcosa con molti interessi di sviluppo, "Dice Sehrish.
Potrebbero passare alcuni anni prima che Sehrish e Kowalkowski prendano una decisione su Spark. La conversione del software creato per l'elaborazione ad alta velocità in buoni strumenti di elaborazione ad alte prestazioni facili da usare richiede una messa a punto fine e un lavoro di squadra tra scienziati sperimentali e computazionali. O, potresti dire, ci vuole più di un colpo al buio.