Questa animazione mostra una serie di eventi di collisione a STAR, ciascuno con migliaia di tracce di particelle e i segnali registrati mentre alcune di queste particelle colpiscono vari componenti del rivelatore. Dovrebbe darti un'idea di quanto sia complessa la sfida ricostruire una registrazione completa di ogni singola particella e delle condizioni in cui è stata creata, in modo che gli scienziati possano confrontare centinaia di milioni di eventi per cercare tendenze e fare scoperte. Credito:Brookhaven National Laboratory
Per la prima volta, gli scienziati hanno utilizzato il calcolo ad alte prestazioni (HPC) per ricostruire i dati raccolti da un esperimento di fisica nucleare, un progresso che potrebbe ridurre drasticamente il tempo necessario per rendere disponibili dati dettagliati per le scoperte scientifiche.
Il progetto dimostrativo ha utilizzato il supercomputer Cori presso il National Energy Research Scientific Computing Center (NERSC), un centro di calcolo ad alte prestazioni presso il Lawrence Berkeley National Laboratory in California, ricostruire più set di dati raccolti dal rivelatore STAR durante le collisioni di particelle al Relativistic Heavy Ion Collider (RHIC), una struttura di ricerca di fisica nucleare presso il Brookhaven National Laboratory di New York. Eseguendo più lavori di elaborazione contemporaneamente sui core di supercalcolo assegnati, il team ha trasformato 4,73 petabyte di dati grezzi in 2,45 petabyte di dati "pronti per la fisica" in una frazione del tempo che avrebbe impiegato utilizzando risorse di elaborazione interne ad alto rendimento, anche con un viaggio dati transcontinentale bidirezionale.
"Il motivo per cui questo è davvero fantastico, " disse il fisico di Brookhaven Jérôme Lauret, chi gestisce le esigenze informatiche di STAR, "è che queste risorse di elaborazione ad alte prestazioni sono elastiche. Puoi chiamare per prenotare una grande quantità di potenza di calcolo quando ne hai bisogno, ad esempio, poco prima di una grande conferenza, quando i fisici hanno fretta di presentare nuovi risultati." Secondo Lauret, la preparazione dei dati grezzi per l'analisi richiede in genere molti mesi, rendendo quasi impossibile fornire tale reattività a breve termine. "Ma con HPC, forse potresti condensare quei mesi di produzione in una settimana. Ciò darebbe davvero potere agli scienziati!"
Il risultato mette in mostra le capacità sinergiche di RHIC e NERSC-U.S. Strutture per gli utenti dell'Ufficio delle scienze del Dipartimento dell'Energia (DOE) situate presso i laboratori nazionali gestiti dal DOE su coste opposte, collegate da una delle reti di condivisione dati ad alte prestazioni più estese al mondo, Rete di scienze energetiche del DOE (ESnet), un'altra struttura per gli utenti dell'Office of Science del DOE.
"Questo è un modello di utilizzo chiave del calcolo ad alte prestazioni per i dati sperimentali, dimostrando che i ricercatori possono portare a termine l'elaborazione dei dati grezzi o le campagne di simulazione in pochi giorni o settimane in un momento critico invece di distribuirsi per mesi sulle proprie risorse dedicate, "ha detto Jeff Porter, un membro del team dei servizi di dati e analisi presso NERSC.
Miliardi di punti dati
Per fare scoperte di fisica al RHIC, gli scienziati devono smistare centinaia di milioni di collisioni tra ioni accelerati a energia molto elevata. STELLA, un sofisticato, strumento elettronico delle dimensioni di una casa, registra i detriti subatomici in streaming da questi frammenti di particelle. Negli eventi più energici, molte migliaia di particelle colpiscono i componenti del rivelatore, producendo spettacoli simili a fuochi d'artificio di tracce di particelle colorate. Ma per capire cosa significano questi segnali complessi, e cosa possono dirci sull'intrigante forma di materia creata nelle collisioni di RHIC, gli scienziati hanno bisogno di descrizioni dettagliate di tutte le particelle e delle condizioni in cui sono state prodotte. Devono anche confrontare enormi campioni statistici di molti diversi tipi di eventi di collisione.
La catalogazione di tali informazioni richiede algoritmi sofisticati e software di riconoscimento dei modelli per combinare i segnali provenienti dai vari dispositivi elettronici di lettura, e un modo semplice per abbinare i dati ai record delle condizioni di collisione. Tutte le informazioni devono quindi essere impacchettate in un modo che i fisici possano utilizzare per le loro analisi.

Cori, il nuovissimo supercomputer del National Energy Research Scientific Computing Center (NERSC), è un Cray XC40 con prestazioni di picco di circa 30 petaflop. Credito:Brookhaven National Laboratory
Da quando RHIC ha iniziato a funzionare nel 2000, questo trattamento di dati grezzi, o ricostruzione, è stato effettuato su risorse informatiche dedicate presso il RHIC e ATLAS Computing Facility (RACF) a Brookhaven. I cluster High-throughput Computing (HTC) elaborano i dati, evento per evento, e scrivere i dettagli codificati di ogni collisione in uno spazio di archiviazione di massa centralizzato accessibile ai fisici STAR di tutto il mondo.
Ma la sfida di stare al passo con i dati è cresciuta con i tassi di collisione in costante miglioramento di RHIC e con l'aggiunta di nuovi componenti del rivelatore. Negli ultimi anni, I set di dati grezzi annuali di STAR hanno raggiunto miliardi di eventi con dimensioni dei dati nell'intervallo di più Petabyte. Quindi il team di STAR Computing ha studiato l'uso di risorse esterne per soddisfare la richiesta di accesso tempestivo a dati pronti per la fisica.
Molti core rendono il lavoro leggero
A differenza dei computer ad alto rendimento presso il RACF, che analizzano gli eventi uno per uno, Le risorse HPC come quelle del NERSC suddividono grandi problemi in attività più piccole che possono essere eseguite in parallelo. Quindi la prima sfida è stata quella di "parallelizzare" l'elaborazione dei dati degli eventi STAR.
"Abbiamo scritto programmi di flusso di lavoro che hanno raggiunto il primo livello di parallelizzazione:parallelizzazione degli eventi, " Ha detto Lauret. Ciò significa che inviano meno lavori composti da molti eventi che possono essere elaborati contemporaneamente sui molti core di elaborazione HPC.
"Immaginate di costruire una città con 100 case. Se ciò fosse fatto in modo ad alto rendimento, ogni casa avrebbe un costruttore che svolge tutti i compiti in sequenza:costruire le fondamenta, le mura, e così via, " Ha detto Lauret. "Ma con HPC cambiamo il paradigma. Invece di un lavoratore per casa abbiamo 100 lavoratori per casa, e ogni lavoratore ha un compito:costruire le pareti o il tetto. Funzionano in parallelo, allo stesso tempo, e alla fine montiamo tutto insieme. Con questo approccio, costruiremo quella casa 100 volte più velocemente."
Certo, ci vuole un po' di creatività per pensare a come tali problemi possono essere suddivisi in attività che possono essere eseguite simultaneamente anziché in sequenza, Laureto aggiunto.
L'HPC consente inoltre di risparmiare tempo abbinando i segnali grezzi del rilevatore ai dati sulle condizioni ambientali durante ogni evento. Per fare questo, i computer devono accedere a un "database delle condizioni":un record della tensione, temperatura, pressione, e altre condizioni del rivelatore che devono essere prese in considerazione nella comprensione del comportamento delle particelle prodotte in ciascuna collisione. Evento per evento, ricostruzione ad alto rendimento, i computer richiamano il database per recuperare i dati per ogni singolo evento. Ma poiché i core HPC condividono un po' di memoria, gli eventi che si verificano vicino nel tempo possono utilizzare gli stessi dati di condizione memorizzati nella cache. Meno chiamate al database significano un'elaborazione dei dati più veloce.
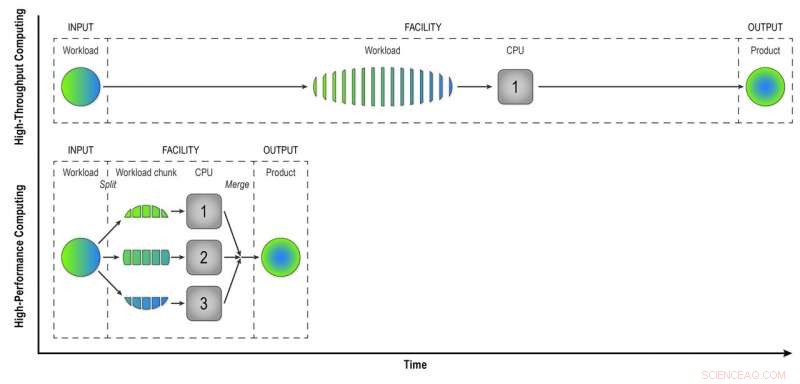
Nel calcolo ad alto rendimento, un carico di lavoro composto da dati provenienti da molte collisioni STAR viene elaborato evento per evento in modo sequenziale per fornire ai fisici "dati ricostruiti", il prodotto di cui hanno bisogno per analizzare completamente i dati. Il calcolo ad alte prestazioni suddivide il carico di lavoro in blocchi più piccoli che possono essere eseguiti tramite CPU separate per accelerare la ricostruzione dei dati. In questa semplice illustrazione, suddividere un carico di lavoro di 15 eventi in tre blocchi di cinque eventi elaborati in parallelo produce lo stesso prodotto in un terzo del tempo del metodo ad alta velocità. L'utilizzo di 32 CPU su un supercomputer come Cori può ridurre notevolmente il tempo necessario per trasformare i dati grezzi da un vero set di dati STAR, con molti milioni di eventi, in informazioni utili che i fisici possono analizzare per fare scoperte. Credito:Brookhaven National Laboratory
Lavoro di squadra in rete
Un'altra sfida nella migrazione dell'attività di ricostruzione dei dati grezzi in un ambiente HPC è stata quella di portare i dati da New York ai supercomputer in California e viceversa. Sia i set di dati di input che di output sono enormi. Il team ha iniziato in piccolo con un esperimento di prova del principio, solo poche centinaia di lavori, per vedere come si sarebbero comportati i loro nuovi programmi di flusso di lavoro.
"Abbiamo ricevuto molta assistenza dai professionisti del networking di Brookhaven, " disse Lauret, "in particolare Mark Lukascsyk, uno dei nostri ingegneri di rete, che era così entusiasta della scienza e ci ha aiutato a fare scoperte." I colleghi di RACF ed ESnet hanno anche aiutato a identificare i problemi hardware e hanno sviluppato soluzioni mentre il team ha lavorato a stretto contatto con Jeff Porter, Mustafa Mustafa, e altri al NERSC per ottimizzare il trasferimento dei dati e il flusso di lavoro end-to-end.
Inizia in piccolo, scalare
Dopo aver messo a punto i loro metodi sulla base dei test iniziali, il team ha iniziato a scalare fino a usare 6, 400 core di calcolo al NERSC, poi su e su e su.
"6, 400 core sono già la metà delle risorse disponibili per la ricostruzione dei dati al RACF, " Ha detto Lauret. "Alla fine siamo andati a 25, 600 core nel nostro test più recente." Con tutto pronto in anticipo per un'assegnazione di tempo su prenotazione anticipata sul supercomputer Cori, "abbiamo fatto questo test per alcuni giorni e abbiamo ottenuto un'intera produzione di dati in pochissimo tempo, " Ha detto Lauret. Secondo Porter al NERSC, "Questo modello è potenzialmente abbastanza trasformativo, e NERSC ha lavorato per supportare tale utilizzo delle risorse da, Per esempio, collegando il suo sistema di dischi ad alte prestazioni a livello centrale direttamente alla sua infrastruttura di trasferimento dati e consentendo una notevole flessibilità nella pianificazione degli slot di lavoro".
L'efficienza end-to-end dell'intero processo:il tempo di esecuzione del programma (non inattivo, in attesa di risorse di calcolo) moltiplicato per l'efficienza dell'utilizzo degli slot di supercalcolo assegnati e dell'ottenimento di un output utile fino a Brookhaven, era del 98%.
"Abbiamo dimostrato di poter utilizzare le risorse HPC in modo efficiente per eliminare gli arretrati di dati non elaborati e risolvere le richieste temporanee di risorse per accelerare le scoperte scientifiche, " ha detto Lauret.
Ora sta esplorando modi per generalizzare il flusso di lavoro all'Open Science Grid, un consorzio globale che aggrega le risorse informatiche, in modo che l'intera comunità di fisici delle alte energie e nucleari possa utilizzarlo.