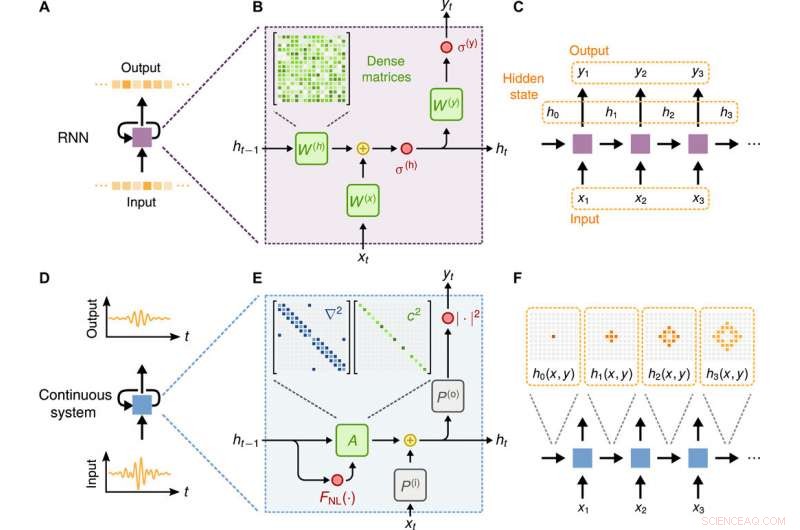
Confronto concettuale tra un RNN standard e un sistema fisico basato su onde. (A) Schema di una cella RNN che opera su una sequenza di input discreta e produce una sequenza di output discreta. (B) Componenti interni della cella RNN, costituito da matrici dense addestrabili W(h), W(x), e W(y). Le funzioni di attivazione per lo stato nascosto e l'uscita sono rappresentate da (h) e σ(y), rispettivamente. (C) Schema del grafico diretto della cella RNN. (D) Schema di una rappresentazione ricorrente di un sistema fisico continuo che opera su una sequenza di input continua e produce una sequenza di output continua. (E) Componenti interne della relazione di ricorrenza per l'equazione d'onda quando discretizzata usando differenze finite. (F) Diagramma del grafico orientato dei passi temporali discreti del sistema fisico continuo e illustrazione di come un disturbo d'onda si propaga all'interno del dominio. Credito: Progressi scientifici , doi:10.1126/sciadv.aay6946
L'hardware di apprendimento automatico analogico offre un'alternativa promettente alle controparti digitali come piattaforma più efficiente dal punto di vista energetico e più veloce. La fisica delle onde basata su acustica e ottica è un candidato naturale per costruire processori analogici per segnali variabili nel tempo. In un nuovo rapporto su Progressi scientifici Tyler W. Hughes e un gruppo di ricerca nei dipartimenti di fisica applicata e ingegneria elettrica della Stanford University, California, mappatura identificata tra la dinamica della fisica delle onde e il calcolo nelle reti neurali ricorrenti.
La mappa indicava la possibilità di addestrare sistemi di onde fisiche per apprendere caratteristiche complesse nei dati temporali utilizzando tecniche di addestramento standard utilizzate per le reti neurali. Come prova di principio, hanno dimostrato un design inverso, mezzo disomogeneo per eseguire la classificazione vocale inglese basata su segnali audio grezzi mentre le loro forme d'onda si diffondono e si propagano attraverso di esso. Gli scienziati hanno ottenuto prestazioni paragonabili a un'implementazione digitale standard di una rete neurale ricorrente. I risultati apriranno la strada a una nuova classe di piattaforme di apprendimento automatico analogiche per un'elaborazione rapida ed efficiente delle informazioni all'interno del suo dominio nativo.
La rete neurale ricorrente (RNN) è un importante modello di apprendimento automatico ampiamente utilizzato per eseguire attività tra cui l'elaborazione del linguaggio naturale e la previsione di serie temporali. Il team ha addestrato sistemi fisici basati su onde per funzionare come RNN ed elaborare passivamente segnali e informazioni nel loro dominio nativo senza conversione da analogico a digitale. Il lavoro ha comportato un notevole guadagno in velocità e un ridotto consumo energetico. Nel quadro attuale, invece di implementare circuiti per indirizzare deliberatamente i segnali all'ingresso, la relazione di ricorrenza si è verificata naturalmente nella dinamica temporale della fisica stessa. Il dispositivo ha fornito la capacità di memoria per l'elaborazione delle informazioni in base alle onde mentre si propagavano nello spazio.
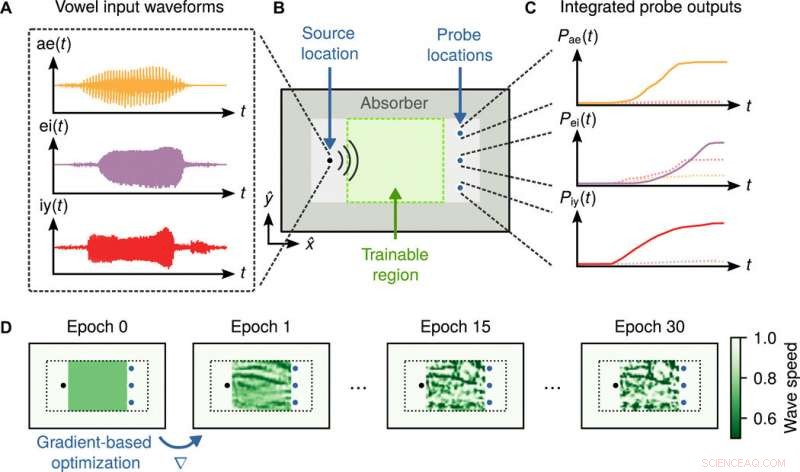
Schema della configurazione del riconoscimento vocale e della procedura di addestramento. (A) forme d'onda audio grezze di campioni di vocali parlate da tre classi. (B) Layout del sistema di riconoscimento vocale. I campioni di vocali vengono iniettati in modo indipendente alla fonte, situato a sinistra del dominio, e si propagano attraverso la regione centrale, indicato in verde, dove una distribuzione del materiale è ottimizzata durante la formazione. La regione grigio scuro rappresenta uno strato limite assorbente. (C) Per la classificazione, la potenza integrata nel tempo ad ogni sonda viene misurata e normalizzata per essere interpretata come una distribuzione di probabilità sulle classi vocaliche. (D) Utilizzando la differenziazione automatica, viene calcolato il gradiente della funzione di perdita rispetto alla densità del materiale nella regione verde. La densità del materiale viene aggiornata in modo iterativo, utilizzando tecniche di ottimizzazione stocastica basate sul gradiente fino alla convergenza Credito: Progressi scientifici , doi:10.1126/sciadv.aay6946
Equivalenza tra la dinamica delle onde e un RNN
Per dimostrare l'equivalenza tra la dinamica delle onde e un RNN, Hughes et al. ha introdotto la funzione di un RNN e la sua connessione alla dinamica delle onde. Per esempio, un RNN può convertire una sequenza di input in una sequenza di output applicando la stessa operazione di base a ciascun membro della sequenza di input in un processo graduale. Lo stato nascosto dell'RNN codificherà quindi la memoria dei passaggi precedenti da aggiornare ad ogni passaggio. Gli stati nascosti potrebbero conservare la memoria delle informazioni passate e apprendere la struttura temporale e le dipendenze a lungo raggio nei dati.
Ad un dato passo, come esempio, l'RNN può funzionare sul vettore di ingresso corrente nella sequenza (x T ) e il vettore di stato nascosto del passaggio precedente (h T − 1 ), per produrre un vettore di output (y T ) e uno stato nascosto aggiornato (h T ). Sebbene esistano molte varianti di RNN, Hughes et al. implementato una strategia comunemente incorporata nel presente lavoro. Il team di ricerca ha osservato una risposta non lineare, che si incontra tipicamente in un'ampia varietà di fisica delle onde, comprese le onde di acque poco profonde, materiali ottici non lineari (studio della luce laser intensa con la materia) e acusticamente all'interno di materiali morbidi e fluidi bollenti. Quando modellato numericamente in tempo discreto, l'equazione d'onda ha definito un'operazione che mappata in quella di un RNN.
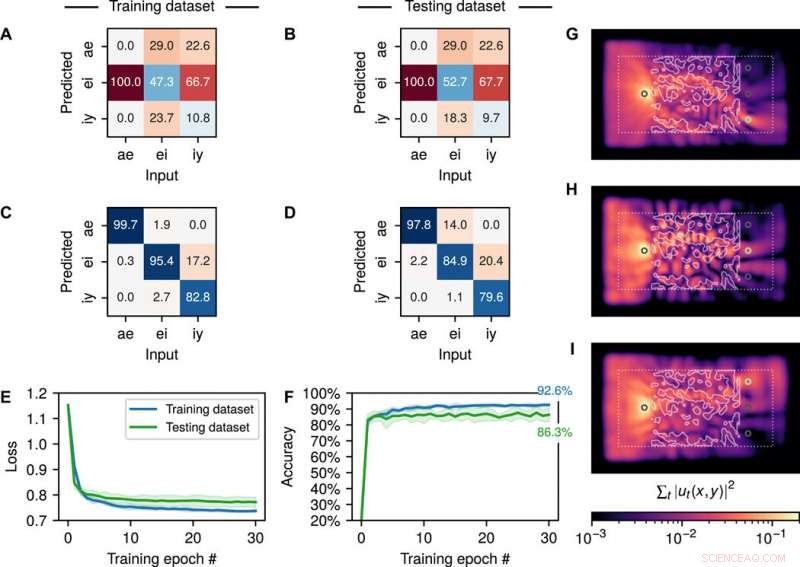
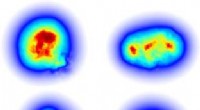
Risultati della formazione sul riconoscimento vocale. Matrice di confusione sui set di dati di addestramento e test per la struttura iniziale (A e B) e la struttura finale (C e D), indicando la percentuale di vocali previste correttamente (diagonale) e in modo errato (fuori diagonale). Risultati di addestramento convalidati incrociati che mostrano la media (linea continua) e SD (regione ombreggiata) della perdita di entropia incrociata (E) e l'accuratezza della previsione (F) su 30 epoche di addestramento e cinque volte del set di dati, che consiste in un totale di 279 campioni vocali totali di parlanti maschili e femminili. (da G a I) La distribuzione dell'intensità integrata nel tempo per un input selezionato casualmente (G) ae vocale, (H) ei vocale, e (I) iy vocale. Credito:progressi scientifici, doi:10.1126/sciadv.aay6946
Allenare un sistema fisico per classificare le vocali
Il team ha poi dimostrato come si potrebbe addestrare la dinamica dell'equazione delle onde per classificare le vocali costruendo una distribuzione di materiale disomogenea. Per questo, hanno utilizzato un set di dati di 930 registrazioni audio grezze di 10 classi vocali di 45 diversi oratori maschi e 48 diversi oratori femmine. Per il compito di apprendimento, Hugh et al. selezionato un sottoinsieme di 279 registrazioni corrispondenti a tre classi di vocali rappresentate dai suoni vocalici "ae, " "ei" e "iy, " rispetto al loro uso nelle parole "aveva, " "hayed" e "heed". Il layout fisico del sistema di riconoscimento vocale conteneva un dominio bidimensionale nel piano xy e infinitamente esteso nella direzione z. Iniettavano la forma d'onda audio di ciascuna vocale tramite una sorgente in un singolo cella di griglia sul lato sinistro del dominio per l'emissione di forme d'onda da propagare attraverso una regione centrale con una distribuzione addestrabile della velocità dell'onda Hanno definito tre sonde sul lato destro della regione e assegnato ciascuna a una delle tre classi vocaliche Hugh e altri hanno quindi misurato la potenza integrata nel tempo su ciascuna sonda per determinare l'uscita del sistema.
La simulazione si è evoluta per l'intera durata della registrazione vocale e il team ha incluso una regione di confine assorbente rappresentata da una regione grigio scuro per prevenire l'accumulo di energia all'interno del dominio computazionale. Le velocità delle onde potrebbero essere modificate per corrispondere in pratica a materiali diversi. In un ambiente acustico, ad esempio, se la distribuzione del materiale consisteva in aria, la velocità del suono era di 331 m/s, mentre la gomma siliconica porosa costituiva una velocità del suono di 150 m/s. La scelta della struttura di partenza ha permesso loro di spostare l'ottimizzatore verso uno dei due materiali, produrre una struttura binarizzata contenente solo uno dei due materiali. Hughes et al. addestrato il sistema eseguendo la retropropagazione attraverso il modello dell'equazione d'onda, in un approccio matematicamente equivalente al metodo aggiunto ampiamente utilizzato per il disegno inverso. Utilizzando queste informazioni di progettazione, hanno aggiornato la densità del materiale tramite l'algoritmo di ottimizzazione Adam, ripetendo fino alla convergenza su una struttura finale.
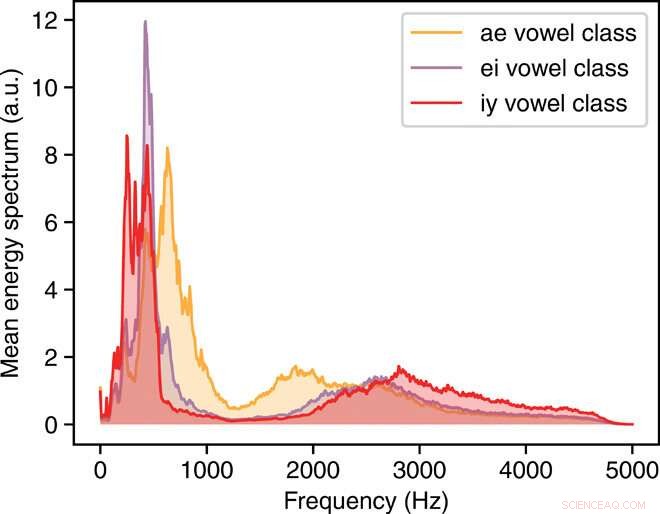
Contenuto in frequenza delle classi vocaliche. La quantità tracciata è lo spettro energetico medio per ae, io, e iy classi vocali. a.u., unità arbitrarie. Credito:progressi scientifici, doi:10.1126/sciadv.aay6946
Visualizzare la performance
Gli scienziati hanno utilizzato una matrice di confusione per visualizzare le prestazioni attraverso i set di dati di formazione e test per le strutture di partenza, media di cinque sessioni di formazione con convalida incrociata. La matrice di confusione ha definito la percentuale di vocali correttamente previste lungo le sue voci diagonali e la percentuale di vocali previste in modo errato per ogni classe nelle sue voci fuori diagonale. Le matrici di confusione addestrate a dominante diagonale indicavano che la struttura poteva effettivamente eseguire il riconoscimento delle vocali. Hughes et al. annotato il valore della perdita di entropia incrociata e l'accuratezza della previsione in funzione dell'epoca di addestramento sui set di dati di test e addestramento.
La prima epoca ha portato alla più grande riduzione della funzione di perdita e al più grande guadagno nell'accuratezza della previsione, con un'accuratezza media del 92,6 percento sul set di dati di addestramento e un'accuratezza media dell'86,3 percento sul set di dati di test. Il team ha osservato il sistema per ottenere prestazioni di previsione quasi perfette sulla vocale "ae" insieme alla capacità di differenziare la vocale "iy" dalla vocale "ei", ma con minore precisione all'interno dei campioni invisibili dei set di dati di test. In questo modo, il team ha fornito una conferma visiva sulla procedura di ottimizzazione per indirizzare la maggior parte dell'energia del segnale alla sonda corretta. Come punto di riferimento delle prestazioni, hanno addestrato un RNN convenzionale sullo stesso compito per ottenere una precisione di classificazione paragonabile all'equazione delle onde. Però, hanno richiesto un gran numero di parametri liberi per l'attività.
In questo modo, Tyler W. Hughes e colleghi hanno presentato un RNN basato su onde con una serie di qualità favorevoli per formare un candidato promettente per elaborare informazioni codificate temporalmente. L'uso della fisica per eseguire il calcolo può ispirare una nuova piattaforma per dispositivi di apprendimento automatico analogici al fine di eseguire il calcolo in modo molto più naturale ed efficiente rispetto alle sue controparti digitali. Il team di ricerca ha determinato la dimensione dello stato nascosto dell'RNN analogico e la sua capacità di memoria utilizzando la dimensione del mezzo di propagazione. Hanno mostrato che la dinamica dell'equazione delle onde è concettualmente equivalente a quella di un RNN. La connessione concettuale aprirà la strada a una nuova classe di piattaforme hardware analogiche, in cui le dinamiche temporali in evoluzione svolgeranno un ruolo importante sia nella fisica che nel set di dati.
© 2020 Scienza X Rete