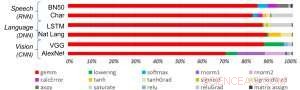
Figura 1. Gli algoritmi di deep learning comprendono uno spettro di operazioni. Sebbene la moltiplicazione matriciale sia dominante, l'ottimizzazione dell'efficienza delle prestazioni mantenendo la precisione richiede che l'architettura di base supporti in modo efficiente tutte le funzioni ausiliarie. Credito:IBM
I recenti progressi nel deep learning e la crescita esponenziale nell'uso del machine learning in tutti i domini applicativi hanno reso l'accelerazione dell'IA di fondamentale importanza. IBM Research ha creato una pipeline di acceleratori hardware AI per soddisfare questa esigenza. Al Simposio dei circuiti VLSI 2018, abbiamo presentato un blocco costitutivo del core dell'acceleratore multi-TeraOPS che può essere scalato su un'ampia gamma di sistemi hardware di intelligenza artificiale. Questo core di intelligenza artificiale digitale presenta un'architettura parallela che garantisce un utilizzo molto elevato e motori di elaborazione efficienti che sfruttano accuratamente la precisione ridotta.
Il calcolo approssimativo è un principio centrale del nostro approccio allo sfruttamento della "fisica dell'intelligenza artificiale", in cui i guadagni di calcolo altamente efficienti dal punto di vista energetico sono raggiunti da architetture appositamente costruite, inizialmente utilizzando calcoli digitali e successivamente includendo l'elaborazione analogica e in memoria.
Storicamente, il calcolo si è basato su un'aritmetica in virgola mobile a 64 e 32 bit ad alta precisione. Questo approccio fornisce calcoli accurati fino all'ennesimo punto decimale, un livello di accuratezza critico per attività di calcolo scientifico come la simulazione del cuore umano o il calcolo delle traiettorie dello space shuttle. Ma abbiamo bisogno di questo livello di accuratezza per le comuni attività di deep learning? Il nostro cervello richiede un'immagine ad alta risoluzione per riconoscere un membro della famiglia, o un gatto? Quando entriamo in un thread di testo per la ricerca, si richiede precisione nella relativa classifica dei 50, 002a risposta più utile contro la 50, 003? La risposta è che molte attività, inclusi questi esempi, possono essere eseguite con il calcolo approssimativo.
Poiché raramente è richiesta la massima precisione per i comuni carichi di lavoro di deep learning, la precisione ridotta è una direzione naturale. I blocchi di costruzione computazionali con motori di precisione a 16 bit sono 4 volte più piccoli dei blocchi comparabili con precisione a 32 bit; questo guadagno nell'efficienza dell'area diventa un aumento delle prestazioni e dell'efficienza energetica sia per l'addestramento AI che per i carichi di lavoro di inferenza. Semplicemente dichiarato, nel calcolo approssimativo, possiamo scambiare la precisione numerica con l'efficienza computazionale, a condizione che sviluppiamo anche miglioramenti algoritmici per mantenere l'accuratezza del modello. Questo approccio integra anche altre tecniche di calcolo approssimativo, inclusi lavori recenti che descrivono nuovi approcci di compressione dell'addestramento per ridurre il sovraccarico delle comunicazioni, portando a un'accelerazione di 40-200 volte rispetto ai metodi esistenti.
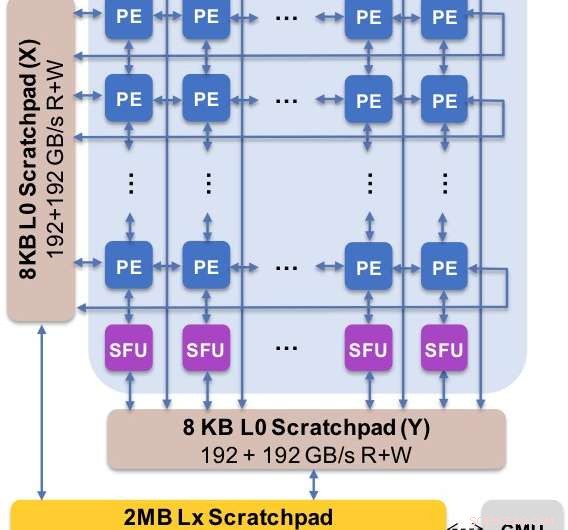
Figura 2. L'architettura di base acquisisce il flusso di dati personalizzato con la gerarchia degli appunti. L'elemento di elaborazione (PE) sfrutta una precisione ridotta per le operazioni di moltiplicazione di matrici e alcune funzioni di attivazione, mentre le unità di funzione speciale (SFU) mantengono una precisione in virgola mobile a 32 bit per le restanti operazioni vettoriali. Credito:IBM
Abbiamo presentato i risultati sperimentali del nostro core AI digitale al Simposio 2018 sui circuiti VLSI. Il design del nostro nuovo nucleo è stato governato da quattro obiettivi:
La nostra nuova architettura è stata ottimizzata non solo per la moltiplicazione di matrici e per i kernel convoluzionali, che tendono a dominare i calcoli di deep learning, ma anche uno spettro di funzioni di attivazione che fanno parte del carico di lavoro computazionale del deep learning. Per di più, la nostra architettura offre supporto per operazioni convoluzionali native, consentendo l'esecuzione di attività di formazione e inferenza di deep learning su immagini e dati vocali con eccezionale efficienza sul core.
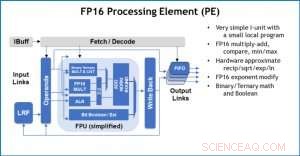
Figura 3. Elemento di elaborazione (PE) con capacità in virgola mobile a 16 bit (FP16) per operazioni di moltiplicazione di matrici, matematica binaria e ternaria, funzioni di attivazione e operazioni booleane. Credito:IBM
Per illustrare come l'architettura di base è stata ottimizzata per una varietà di funzioni di deep learning, La Figura 1 mostra la suddivisione dei tipi di operazioni all'interno di algoritmi di deep learning in uno spettro di domini applicativi. I componenti di moltiplicazione della matrice dominante sono calcolati nell'architettura principale utilizzando un'organizzazione del flusso di dati personalizzata degli elementi di elaborazione mostrati nelle figure 2 e 3 in cui i calcoli di precisione ridotta possono essere sfruttati in modo efficiente, considerando che le restanti funzioni vettoriali (tutte le barre non rosse nella Figura 1) vengono eseguite negli Elementi di elaborazione o nelle Unità di funzioni speciali mostrate nelle Figure 3 o 4, a seconda delle esigenze di precisione della specifica funzione.
Al Simposio, abbiamo mostrato risultati hardware che confermano che questo approccio a architettura singola è in grado sia di addestramento che di inferenza e supporta modelli in più domini (ad es. discorso, visione, elaborazione del linguaggio naturale). Mentre altri gruppi puntano alle "prestazioni di picco" dei loro chip AI specializzati, ma hanno livelli di prestazioni sostenuti a una piccola frazione del picco, ci siamo concentrati sulla massimizzazione delle prestazioni e dell'utilizzo sostenuti, poiché le prestazioni sostenute si traducono direttamente in esperienza dell'utente e tempi di risposta.
Il nostro testchip è mostrato in Figura 5. Utilizzando questo testchip, costruito in tecnologia 14LPP, abbiamo dimostrato con successo sia l'addestramento che l'inferenza, attraverso un'ampia libreria di deep learning, esercitando tutte le operazioni comunemente utilizzate nei compiti di deep learning, comprese le moltiplicazioni matriciali, circonvoluzioni e varie funzioni di attivazione non lineari.
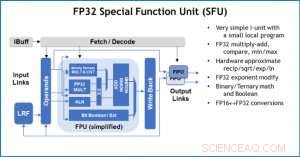
Figura 4. Special Function Unit (SFU) con virgola mobile a 32 bit (FP32) per determinati calcoli vettoriali. Credito:IBM
Abbiamo evidenziato la flessibilità e la capacità multiuso del core AI digitale e il supporto nativo per più flussi di dati nel documento VLSI, ma questo approccio è completamente modulare. Questo core AI può essere integrato nei SoC, CPU, o microcontrollori e utilizzati per la formazione, inferenza, o entrambi. I chip che utilizzano il core possono essere distribuiti nel data center o nell'edge.
Spinto da una comprensione fondamentale degli algoritmi di deep learning presso IBM Research, ci aspettiamo che i requisiti di precisione per la formazione e l'inferenza continuino a crescere, il che porterà a miglioramenti dell'efficienza quantistica nelle architetture hardware necessarie per l'intelligenza artificiale. Resta sintonizzato per ulteriori ricerche dal nostro team.
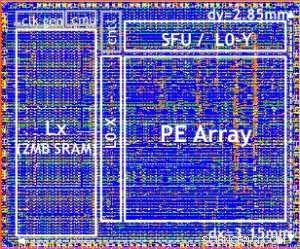
Figure 5. Digital AI Core testchip, based on 14LPP technology, including 5.75M gates, 1.00 flip-flops, 16KB L0 and 16KB of PE local registers. This chip was used to demonstrate both training and inferencing, across a wide range of AI workloads. Credito:IBM














