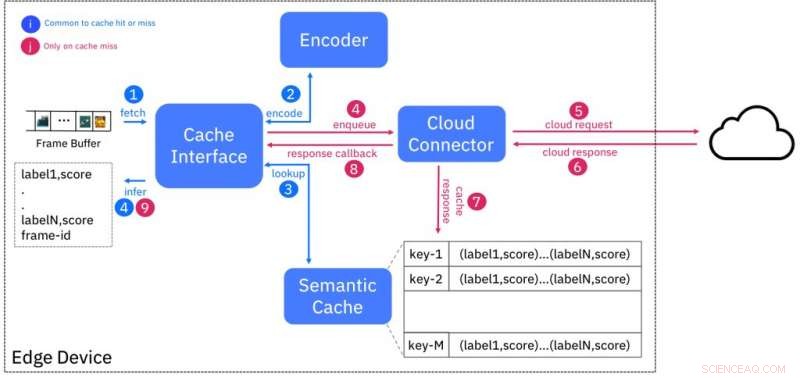
Diagramma a blocchi del servizio di cache semantica. Credito:IBM
La disponibilità di alta risoluzione, sensori economici hanno aumentato esponenzialmente la quantità di dati prodotti, che potrebbe sopraffare l'Internet esistente. Ciò ha portato alla necessità di capacità di calcolo per elaborare i dati vicino a dove vengono generati, ai margini della rete, invece di inviarlo a datacenter cloud. Elaborazione dei bordi, come questo è noto, non solo riduce il carico sulla larghezza di banda, ma riduce anche la latenza per ottenere informazioni dai dati grezzi. Però, la disponibilità di risorse all'edge è limitata a causa della mancanza di economie di scala che rendono l'infrastruttura cloud conveniente da gestire e offrire.
Il potenziale dell'edge computing non è più ovvio che con l'analisi video. Le videocamere ad alta definizione (1080p) stanno diventando comuni in settori come la sorveglianza e, a seconda del frame rate e della compressione dei dati, può produrre 4-12 megabit di dati al secondo. Le fotocamere con risoluzione 4K più recenti producono dati grezzi nell'ordine dei gigabit al secondo. La necessità di approfondimenti in tempo reale su tali flussi video sta guidando l'uso di tecniche di intelligenza artificiale come le reti neurali profonde per attività come la classificazione, rilevamento ed estrazione di oggetti, e rilevamento delle anomalie.
Nel nostro documento della conferenza Hot Edge 2018 "Shadow Puppets:Inferenza IA accurata a livello di cloud alla velocità e all'economia di Edge, " il nostro team presso IBM Research – Ireland ha valutato sperimentalmente le prestazioni di uno di questi carichi di lavoro di intelligenza artificiale, classificazione degli oggetti, utilizzando servizi in hosting su cloud disponibili in commercio. Il miglior risultato che abbiamo potuto ottenere è stato un output di classificazione di 2 fotogrammi al secondo, che è molto al di sotto della velocità di produzione video standard di 24 fotogrammi al secondo. L'esecuzione di un esperimento simile su un dispositivo edge rappresentativo (NVIDIA Jetson TK1) ha soddisfatto i requisiti di latenza ma ha utilizzato la maggior parte delle risorse disponibili sul dispositivo in questo processo.
Rompiamo questa dualità proponendo la cache semantica, un approccio che combina la bassa latenza delle implementazioni edge con le risorse quasi infinite disponibili nel cloud. Usiamo la ben nota tecnica del caching per mascherare la latenza eseguendo l'inferenza AI per un particolare input (ad es. o un codice hash, in base alle caratteristiche estratte dall'input.
Questo schema è progettato in modo tale che gli input semanticamente simili (ad esempio appartenenti alla stessa classe) abbiano impronte digitali "vicine" l'una all'altra, secondo una certa misura di distanza. La Figura 1 mostra il design della cache. L'encoder crea l'impronta digitale di un frame video in ingresso e cerca nella cache le impronte digitali entro una distanza specifica. Se c'è una corrispondenza, quindi i risultati dell'inferenza vengono forniti dalla cache, evitando così la necessità di interrogare il servizio AI in esecuzione nel cloud.
Troviamo le impronte analoghe alle ombre delle marionette, proiezioni bidimensionali di figure su uno schermo creato da una luce sullo sfondo. Chiunque abbia usato le sue dita per creare ombre cinesi dimostrerà che l'assenza di dettagli in queste figure non limita la loro capacità di essere il fondamento per una buona narrazione. Le impronte digitali sono proiezioni dell'input effettivo che possono essere utilizzate per ricche applicazioni AI anche in assenza di dettagli originali.
Abbiamo sviluppato un'implementazione completa del proof of concept della cache semantica, seguendo un approccio progettuale "as a service", ed esporre il servizio agli utenti di dispositivi/gateway perimetrali tramite un'interfaccia REST. Le nostre valutazioni su una gamma di dispositivi edge diversi (Raspberry Pi 3/NVIDIA Jetson TK1/TX1/TX2) hanno dimostrato che la latenza dell'inferenza è stata ridotta di 3 volte e l'utilizzo della larghezza di banda di almeno il 50% rispetto a un cloud- unica soluzione.
La prima valutazione di un primo prototipo di implementazione del nostro approccio mette in mostra il suo potenziale. Stiamo continuando a maturare l'approccio iniziale, dando la priorità alla sperimentazione di tecniche di codifica alternative per una maggiore precisione, estendendo anche la valutazione a ulteriori set di dati e attività di intelligenza artificiale.
Prevediamo che questa tecnologia abbia applicazioni nella vendita al dettaglio, manutenzione predittiva per impianti industriali, e videosorveglianza, tra gli altri. Per esempio, la cache semantica potrebbe essere utilizzata per memorizzare le impronte digitali delle immagini dei prodotti alle casse. Questo può essere utilizzato per prevenire perdite di negozio dovute a furto o scansione errata. Il nostro approccio è un esempio di passaggio senza interruzioni tra servizi cloud e servizi perimetrali per fornire soluzioni di intelligenza artificiale all'avanguardia sull'edge.
Questa storia è stata ripubblicata per gentile concessione di IBM Research. Leggi la storia originale qui.