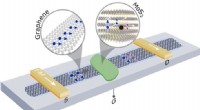
Manuelli utilizza il sistema DON e il robot Kuka per afferrare una tazza. Credito:Tom Buehler
Gli umani sono stati a lungo maestri di destrezza, un'abilità che può in gran parte essere attribuita all'aiuto dei nostri occhi. Robot, nel frattempo, stanno ancora recuperando. Certamente c'è stato qualche progresso:per decenni i robot in ambienti controllati come le catene di montaggio sono stati in grado di raccogliere lo stesso oggetto più e più volte.
Più recentemente, i progressi nella visione artificiale hanno permesso ai robot di fare distinzioni di base tra oggetti, ma anche allora, non capiscono veramente le forme degli oggetti, quindi c'è poco che possono fare dopo un rapido ritiro.
In un nuovo documento, ricercatori del Computer Science and Artificial Intelligence Laboratory (CSAIL) del MIT, affermano di aver realizzato uno sviluppo chiave in quest'area di lavoro:un sistema che consente ai robot di ispezionare oggetti casuali, e comprenderli visivamente abbastanza da svolgere compiti specifici senza averli mai visti prima.
Il sistema, soprannominato "Dense Object Nets" (DON), guarda gli oggetti come raccolte di punti che fungono da "roadmap visive" di sorta. Questo approccio consente ai robot di comprendere e manipolare meglio gli oggetti, e, più importante, consente loro anche di raccogliere un oggetto specifico tra un mucchio di oggetti simili, un'abilità preziosa per i tipi di macchine che aziende come Amazon e Walmart usano nei loro magazzini.
Per esempio, qualcuno potrebbe usare DON per convincere un robot ad afferrare un punto specifico su un oggetto, diciamo, la lingua di una scarpa. Da quello, può guardare una scarpa che non ha mai visto prima, e afferrare con successo la sua lingua.
"Molti approcci alla manipolazione non sono in grado di identificare parti specifiche di un oggetto attraverso i molti orientamenti che l'oggetto può incontrare, " dice il dottorando Lucas Manuelli, che ha scritto un nuovo articolo sul sistema con l'autore principale e il collega Ph.D. studente Pete Florence, insieme al professore del MIT Russ Tedrake. "Per esempio, gli algoritmi esistenti non sarebbero in grado di afferrare una tazza per il manico, soprattutto se la tazza potrebbe essere in più orientamenti, come in piedi, o dalla sua parte."
Il team vede potenziali applicazioni non solo nelle impostazioni di produzione, ma anche nelle case. Immagina di dare al sistema l'immagine di una casa ordinata, e lasciarlo pulire mentre sei al lavoro, o usando un'immagine dei piatti in modo che il sistema metta via i tuoi piatti mentre sei in vacanza.
È inoltre degno di nota che nessuno dei dati è stato effettivamente etichettato da esseri umani; piuttosto, il sistema è "autocontrollato, " quindi non richiede annotazioni umane.
Rendendolo facile da afferrare
Due approcci comuni alla presa del robot implicano l'apprendimento specifico del compito, o creando un algoritmo di presa generale. Entrambe queste tecniche presentano ostacoli:i metodi specifici per attività sono difficili da generalizzare ad altri compiti, e la comprensione generale non diventa abbastanza specifica per affrontare le sfumature di compiti particolari, come mettere oggetti in punti specifici.
Il sistema DON, però, essenzialmente crea una serie di coordinate su un dato oggetto, che servono come una sorta di "tabella di marcia visiva" degli oggetti, per dare al robot una migliore comprensione di ciò che deve afferrare, e dove.
Il team ha addestrato il sistema a guardare gli oggetti come una serie di punti che costituiscono un sistema di coordinate più ampio. Può quindi mappare diversi punti insieme per visualizzare la forma 3D di un oggetto, simile a come le foto panoramiche vengono unite da più foto. Dopo l'allenamento, se una persona specifica un punto su un oggetto, il robot può scattare una foto di quell'oggetto, e identificare e abbinare i punti per poter poi raccogliere l'oggetto in quel punto specificato.
Questo è diverso da sistemi come DexNet di UC-Berkeley, che può afferrare molti oggetti diversi, ma non può soddisfare una richiesta specifica. Immagina un bambino di 18 mesi, che non capisce con quale giocattolo vuoi che giochi ma può ancora afferrare molti oggetti, contro un bambino di quattro anni che può rispondere "vai a prendere il tuo camion per l'estremità rossa".
In una serie di test eseguiti su un peluche a forma di bruco, un braccio robotico Kuka alimentato da DON potrebbe afferrare l'orecchio destro del giocattolo da una gamma di diverse configurazioni. Ciò ha dimostrato che, tra l'altro, il sistema ha la capacità di distinguere sinistra da destra su oggetti simmetrici.
Quando si esegue il test su un cestino di diversi cappelli da baseball, DON potrebbe scegliere un cappello bersaglio specifico nonostante tutti i cappelli abbiano design molto simili e non abbiano mai visto le immagini dei cappelli nei dati di allenamento prima.
"Nelle fabbriche i robot hanno spesso bisogno di alimentatori di pezzi complessi per funzionare in modo affidabile, " dice Manuelli. "Ma un sistema come questo in grado di comprendere l'orientamento degli oggetti potrebbe semplicemente scattare una foto ed essere in grado di afferrare e regolare l'oggetto di conseguenza".
Nel futuro, il team spera di migliorare il sistema in un luogo in cui può svolgere compiti specifici con una comprensione più profonda degli oggetti corrispondenti, come imparare ad afferrare un oggetto e spostarlo con l'obiettivo finale di dire, pulire una scrivania.
Il team presenterà il proprio documento sul sistema il mese prossimo alla Conference on Robot Learning a Zurigo, Svizzera.