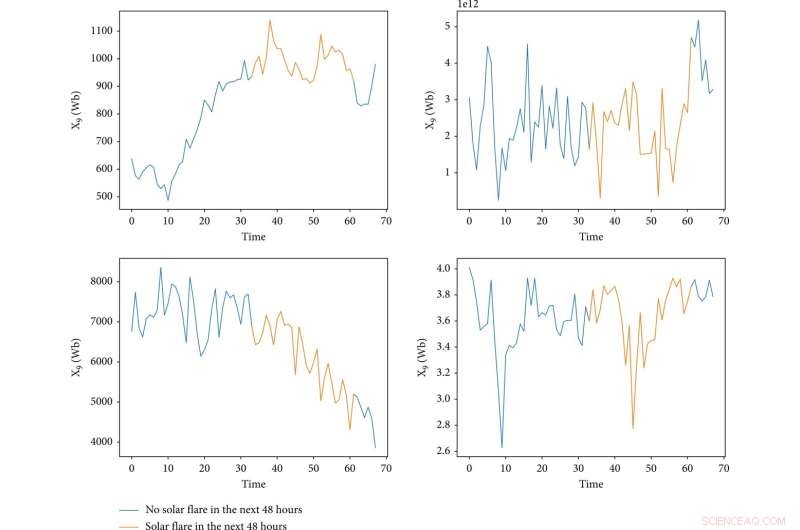
La visualizzazione di quattro caratteristiche durante l'esistenza di una regione attiva. L'asse x rappresenta il tempo e la sua unità è un campione, dove "0" rappresenta l'ora di inizio di una regione attiva e l'intervallo di tempo tra tempi adiacenti è 1,5 h. L'asse y rappresenta il valore di una funzione. Le linee blu indicano che non ci saranno brillamenti solari nelle prossime 48 ore e le linee gialle sono l'opposto. Credito:Spazio:scienza e tecnologia
I brillamenti solari sono eventi di tempesta solare guidati dal campo magnetico nell'area di attività solare. Quando questa radiazione di bagliore arriva nelle vicinanze della Terra, la fotoionizzazione aumenta la densità elettronica nello strato D della ionosfera, causando l'assorbimento delle comunicazioni radio ad alta frequenza, la scintillazione delle comunicazioni satellitari e una maggiore interferenza del rumore di fondo con il radar.
Le statistiche e l'esperienza mostrano che più grande è il bagliore, più è probabile che sia accompagnato da altre esplosioni solari come un evento protonico solare e più gravi sono gli effetti sulla Terra, influenzando così il volo spaziale, la comunicazione, la navigazione, la trasmissione di energia e altri sistemi tecnologici.
Fornire informazioni previsionali sulla probabilità e sull'intensità dei focolai di brillamento è un elemento importante all'inizio delle previsioni meteorologiche spaziali operative. Lo studio di modellizzazione della previsione dei brillamenti solari è una parte necessaria di una previsione accurata dei brillamenti e ha un importante valore applicativo. In un documento di ricerca recentemente pubblicato su Spazio:scienza e tecnologia , Hong Chen del College of Science, Huazhong Agricultural University, ha combinato l'algoritmo di clustering k-means e diversi modelli della CNN per creare un sistema di allerta in grado di prevedere se si verificherà un brillamento solare nelle prossime 48 ore.
In primo luogo, l'autore ha introdotto i dati utilizzati nel documento e li ha analizzati dal punto di vista statistico per fornire una base per la progettazione del sistema di allerta per brillamenti solari. Per ridurre l'effetto di proiezione, è stato selezionato il centro della regione attiva situata entro ±30° dal centro del disco solare. Successivamente, l'autore ha etichettato i dati in base ai dati sui brillamenti solari forniti dalla NOAA, inclusi gli orari di inizio e fine dei brillamenti, il numero della regione attiva, l'entità dei brillamenti, ecc.
C'era un grave squilibrio tra il numero di campioni positivi e negativi nel set di dati. Per alleviare lo squilibrio tra campioni positivi e negativi, è stato trovato un principio per selezionare gli eventi che hanno campioni positivi il più possibile. L'autore ha visualizzato la distribuzione della densità di probabilità di ciascuna caratteristica in tutti i campioni negativi e in tutti i campioni positivi. Si potrebbe facilmente scoprire che le distribuzioni di densità di probabilità dei campioni negativi erano tutte distribuzioni asimmetriche negativamente e le caratteristiche dei campioni positivi erano generalmente maggiori di quelle dei campioni negativi. Pertanto, è stato possibile filtrare gli eventi con campioni positivi in base ai valori delle caratteristiche di ciascun evento.
Successivamente, l'autore ha costruito l'intera pipeline con un metodo contenente i due passaggi seguenti:preelaborazione dei dati e training del modello. Per condurre la preelaborazione dei dati, K-means, un metodo di clustering non supervisionato, è stato utilizzato per raggruppare gli eventi per ridurre il più possibile gli eventi che includono solo campioni negativi.
Dopo il raggruppamento di k-medie, tutti gli eventi sono stati divisi in tre categorie, vale a dire categoria A, categoria B e categoria C. L'autore ha scoperto che il rapporto di campioni positivi nella categoria C è 0,340633, che è molto più grande di quello dell'intero set di dati. Pertanto, solo i dati nella categoria C sono stati scelti come dati di input nella fase successiva dell'algoritmo.
Nella seconda fase, le reti neurali utilizzate dall'autore erano Resnet18, Resnet34 e Xception, che sono comunemente utilizzate nel deep learning. Tre quarti dei campioni della categoria C sono stati scelti casualmente. In ogni evento c'erano dati di addestramento per i modelli di rete neurale e il resto dei campioni sono stati considerati dati di convalida nel processo di addestramento del modello.
Per evitare l'influenza della dimensione, l'autore ha anche standardizzato i dati originali. Il metodo di standardizzazione era diverso da quelli comunemente usati. Secondo la formula di calcolo della standardizzazione, se la rete neurale prevedeva che l'etichetta di un campione fosse 1, questo campione veniva considerato come un segnale di brillamento solare che si sarebbe verificato nelle successive 48 ore. Ma se si prevede che sia 0, la probabilità che si verifichi un brillamento solare nelle prossime 48 ore sarebbe così piccola che potrebbe essere ignorata.
Quindi, l'autore ha condotto esperimenti e ha discusso i risultati. L'autore ha prima fornito un'introduzione all'impostazione sperimentale e poi ha condotto numerosi esperimenti di ablazione e confronti con diversi modelli per verificare il miglioramento dell'algoritmo di clustering k-mean e della strategia di boosting. Inoltre, l'autore ha anche effettuato confronti tra il metodo utilizzato nell'esperimento e altri 13 algoritmi di classificazione binaria comunemente usati per presentare le sue prestazioni di previsione.
I risultati sperimentali hanno mostrato che le prestazioni di previsione del modello che integrava diverse reti neurali era migliore di quella di una singola rete neurale convoluzionale. Infine, i risultati delle previsioni di Resnet18, Resnet34 e Xception sono stati combinati aumentando la strategia. Per tutte le reti, il richiamo potrebbe rimanere invariato o addirittura ridotto notevolmente dopo il clustering. Tuttavia, la precisione doveva aumentare in modo significativo.
Dopo il raggruppamento, sebbene il tasso di campionamento positivo sarebbe notevolmente migliorato, dal 5% al 34%, anche quasi il 40% delle informazioni sui campioni positivi andrebbe perso. L'autore pensava che questo fosse il motivo principale per cui il ricordo rimaneva invariato o addirittura diminuiva. Significava anche che il numero di campioni positivi previsti nell'esperimento era inferiore a quello senza raggruppamento, ma la probabilità che un campione positivo previsto fosse un vero positivo era maggiore.
In contrasto con il fenomeno per cui le prestazioni di previsione di altri metodi di classificazione binaria erano in diminuzione o addirittura molto scarse dopo il raggruppamento, le prestazioni del metodo dell'autore sono migliorate di oltre il 9% dopo il raggruppamento. In conclusione, il sistema di allerta precoce di brillamento solare a due stadi consisteva in un algoritmo di clustering non supervisionato (k-mean) e diversi modelli CNN, in cui il primo doveva aumentare la frequenza di campionamento positiva e il secondo integrava i risultati di previsione dei modelli CNN per migliorare le prestazioni di previsione.
I risultati dell'esperimento hanno dimostrato l'efficacia del metodo. + Esplora ulteriormente