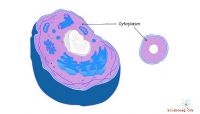
Il dogma centrale della biologia molecolare spiega che il flusso di informazioni per i geni va dal DNA codice genetico Nel 1970 divenne comunemente accettato che l'RNA fece copie di geni specifici dalla doppia elica del DNA originale e quindi costituì la base per produzione di proteine dal codice copiato. Il processo di copia dei geni tramite trascrizione del codice genetico e produzione di proteine attraverso la traduzione del codice in catene di amminoacidi si chiama espressione genica La scoperta di splicing alternativo Le informazioni codificate nelle proteine non possono influenzare il codice DNA originale. L'elica del DNA che codifica le informazioni genetiche dell'organismo si trova nel nucleo delle cellule eucariotiche. Le cellule procariotiche sono cellule che non hanno un nucleo, quindi la trascrizione del DNA, la traduzione e la sintesi proteica avvengono tutte nel citoplasma della cellula attraverso un processo di trascrizione /traduzione simile (ma più semplice) Nelle cellule eucariotiche, le molecole di DNA non possono lasciare il nucleo, quindi le cellule devono copiare il codice genetico per sintetizzare le proteine nella cellula al di fuori del nucleo. Il processo di copia della trascrizione è iniziato da un enzima chiamato RNA polimerasi Copia. L'RNA polimerasi viaggia lungo i filamenti di DNA e crea una copia di un gene su uno dei filamenti. Giuntura. I filamenti di DNA contengono sequenze di codifica proteica chiamate esoni La sequenza di DNA copiata nella seconda fase contiene gli esoni e gli introni ed è un precursore dell'RNA messaggero. Per rimuovere gli introni, il filo pre-mRNA Le proteine sono lunghe stringhe di aminoacidi uniti da legami peptidici. Sono responsabili di influenzare l'aspetto di una cellula e ciò che fa. Formano strutture cellulari e svolgono un ruolo chiave nel metabolismo. Agiscono come enzimi e ormoni e sono incorporati nelle membrane cellulari per facilitare la transizione di grandi molecole. La sequenza della stringa di aminoacidi per una proteina è codificata nell'elica del DNA. Il codice è composto dalle seguenti quattro basi azotate Queste sono basi azotate e ogni anello della catena del DNA è costituito da una coppia di basi. La guanina forma una coppia con citosina e l'adenina forma una coppia con timina. Ai collegamenti vengono assegnati nomi di una lettera a seconda della base che viene prima in ogni collegamento. Le coppie di basi sono chiamate G, C, A e T per i collegamenti guanina-citosina, citosina-guanina, adenina-timina e timina-adenina. Tre coppie di basi rappresentano un codice per un particolare aminoacido e sono chiamato un codone Esistono circa 20 aminoacidi utilizzati nella sintesi proteica, e ci sono anche codoni per i segnali di avvio e arresto. Di conseguenza, ci sono abbastanza codoni per definire una sequenza di amminoacidi per ogni proteina con alcune ridondanze. L'mRNA è una copia del codice per una proteina. Le proteine sono prodotte dai ribosomi Quando l'mRNA lascia il nucleo, cerca un ribosoma I ribosomi sono le fabbriche della cellula che producono il Sono costituiti da una piccola parte che legge l'mRNA e una parte più grande che assembla gli amminoacidi nella sequenza corretta. Il ribosoma è costituito da RNA ribosomiale e proteine associate. I ribosomi si trovano galleggianti nel citosol della cellula o attaccati al reticolo endoplasmatico della cellula Se i ribosomi attaccati all'ER producono una proteina, la proteina viene inviata all'esterno della membrana cellulare per essere usata altrove. Le cellule che secernono ormoni ed enzimi di solito hanno molti ribosomi attaccati al pronto soccorso e producono proteine per uso esterno. L'mRNA si lega a un ribosoma e può iniziare la traduzione del codice nella proteina corrispondente. Il citosol fluttuante nella cellula è costituito da aminoacidi e piccole molecole di RNA chiamate transfer RNA Quando il ribosoma legge il codice mRNA, seleziona una molecola di tRNA per trasferire l'amminoacido corrispondente nel ribosoma. Il tRNA porta una molecola dell'amminoacido specificato al ribosoma, che attacca la molecola nella sequenza corretta alla catena di amminoacidi. La sequenza degli eventi è la seguente: Alcune proteine sono prodotte in lotti mentre altre sono sintetizzate continuamente per soddisfare le esigenze continue della cellula. Quando il ribosoma produce la proteina, il flusso di informazioni del dogma centrale dal DNA alla proteina è completo. Di recente sono state alternative al flusso di informazioni diretto previsto nel dogma centrale ", 3, [[Nello splicing alternativo, il pre-mRNA viene tagliato per rimuovere gli introni, ma la sequenza di esoni nella stringa di DNA copiata viene modificata. Ciò significa che una sequenza di codice del DNA può dare origine a due diverse proteine. Mentre gli introni vengono scartati come sequenze genetiche non codificanti, possono influenzare la codifica dell'esone e possono essere una fonte di geni aggiuntivi in determinate circostanze. Mentre il dogma centrale della biologia molecolare rimane valido per quanto riguarda il flusso di informazioni , i dettagli di come le informazioni fluiscono dal DNA alle proteine sono meno lineari di quanto si pensasse inizialmente.
a una copia intermedia dell'RNA e quindi alle proteine sintetizzate dal codice. Le idee chiave alla base del dogma furono proposte per la prima volta dal biologo molecolare britannico Francis Crick nel 1958.
. A seconda della cellula e di alcuni fattori ambientali, alcuni geni vengono espressi mentre altri rimangono inattivi. L'espressione genica è governata da segnali chimici tra le cellule e gli organi degli organismi viventi.
e lo studio di parti non codificanti del DNA chiamate introni
indicano che il processo descritto dal dogma centrale della biologia è più complicato di quanto inizialmente ipotizzato. Il semplice DNA da RNA a sequenza proteica ha rami e variazioni che aiutano gli organismi ad adattarsi a un ambiente in evoluzione. Il principio di base secondo cui le informazioni genetiche si muovono solo in una direzione, dal DNA all'RNA alle proteine, rimane incontestato.
Trascrizione del DNA ha luogo the Nucleus
e ha le seguenti fasi:
e le sequenze che non sono utilizzate nella produzione di proteine sono chiamate introni
. Poiché lo scopo del processo di trascrizione è produrre RNA per la sintesi di proteine, la parte introne del codice genetico viene scartata usando un meccanismo di giunzione.
viene tagliato su un'interfaccia introne /esone. La parte introne del filamento forma una struttura circolare e lascia il filamento, consentendo ai due esoni da entrambi i lati dell'introne di unirsi. Quando la rimozione degli introni è completa, il nuovo filamento di mRNA è mRNA maturo
, ed è pronto a lasciare il nucleo.
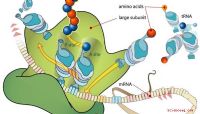
L'mRNA ha una copia del codice per una proteina
:
. Un codone tipico potrebbe essere chiamato GGA o ATC. Poiché ciascuna delle tre posizioni dei codoni per una coppia di basi può avere quattro diverse configurazioni, il numero totale di codoni è 4 3 o 64.
per sintetizzare la proteina per la quale ha le istruzioni codificate.
(ER), una serie di sacche chiuse da membrana trovate vicino al nucleo. Quando i ribosomi galleggianti producono proteine, le proteine vengono rilasciate nel citosol cellulare.
La traduzione assembla una proteina specifica secondo il codice mRNA
o tRNA. Esiste una molecola di tRNA per ogni tipo di amminoacido usato per la sintesi proteica.
.
Splicing alternativo ed effetti degli introni