Un team di ricercatori ha utilizzato l’intelligenza artificiale per identificare un materiale termoelettrico con valori favorevoli. Il gruppo è stato in grado di superare le insidie convenzionali dell’intelligenza artificiale e le sfide legate ai big data, offrendo un ottimo esempio di come l’intelligenza artificiale può rivoluzionare la scienza dei materiali. I dettagli sono stati pubblicati sulla rivista Science China Materials l'8 marzo 2024.
"I metodi tradizionali per trovare materiali adatti implicano tentativi ed errori, che richiedono molto tempo e spesso sono costosi", proclama Hao Li, professore associato presso l'Istituto avanzato per la ricerca sui materiali (WPI-AIMR) dell'Università di Tohoku e autore corrispondente dell'articolo. "L'intelligenza artificiale trasforma tutto questo analizzando i database per identificare potenziali materiali che possono poi essere verificati sperimentalmente."
Tuttavia, le sfide rimangono. I set di dati sui materiali su larga scala a volte contengono errori e anche l’adattamento eccessivo delle proprietà dipendenti dalla temperatura previste è un errore comune. L'overfitting si verifica quando un modello impara a catturare il rumore o le fluttuazioni casuali nei dati di addestramento anziché nel modello o nella relazione sottostante.
Di conseguenza, il modello funziona bene sui dati di addestramento ma non riesce a generalizzare dati nuovi e invisibili. Quando si prevedono proprietà dipendenti dalla temperatura, il sovradattamento potrebbe portare a previsioni imprecise quando il modello incontra nuove condizioni al di fuori dell'intervallo dei dati di addestramento.
Li e i suoi colleghi hanno cercato di superare questo problema per sviluppare un materiale termoelettrico. Questi materiali convertono l'energia termica in energia elettrica o viceversa. Pertanto, ottenere una dipendenza dalla temperatura altamente accurata è fondamentale.
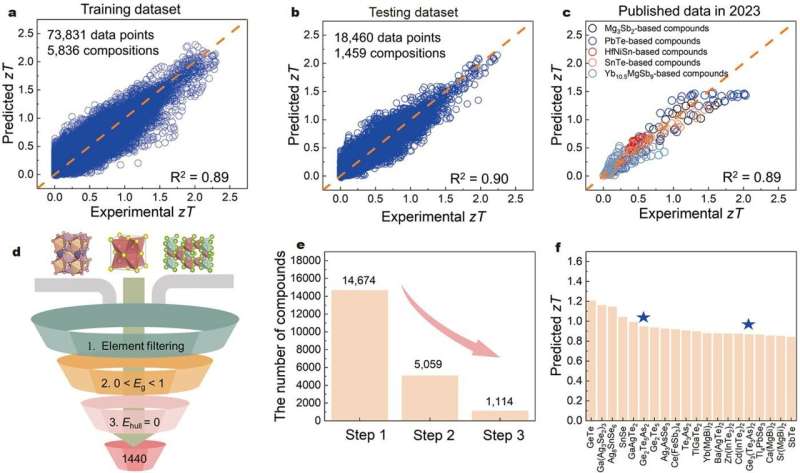
"In primo luogo, abbiamo eseguito una serie di azioni razionali per identificare e scartare dati discutibili, ottenendo 92.291 punti dati comprendenti 7.295 composizioni e diverse temperature dal database Starrydata2, un database online che raccoglie dati digitali da articoli pubblicati," afferma Li.
Quindi i ricercatori hanno costruito modelli di costruzione di macchine utilizzando il metodo Gradient Boosting Decision Tree. Il modello ha raggiunto notevoli valori R2 di 0,89, ~0,90 e ~0,89 sul set di dati di addestramento, sul set di dati di test e sui nuovi dati sperimentali fuori campione rilasciati nel 2023, dimostrando l'accuratezza del modello nel prevedere i nuovi materiali disponibili.
"Potremmo utilizzare questo modello per effettuare una valutazione su larga scala dei materiali stabili dal database del Materials Project, prevedendo le potenziali prestazioni termoelettriche di nuovi materiali e fornendo indicazioni per gli esperimenti", afferma Xue Jia, professore assistente presso WPI-AIMR, e coautore dell'articolo.
In definitiva, lo studio illustra l’importanza di seguire linee guida rigorose quando si tratta di preelaborazione e suddivisione dei dati nell’apprendimento automatico in modo da affrontare le questioni urgenti nella scienza dei materiali. I ricercatori sono ottimisti sul fatto che la loro strategia possa essere applicata anche ad altri materiali, come elettrocatalizzatori e batterie.
Ulteriori informazioni: Xue Jia et al, Affrontare le sfide dei big data nell'intelligenza artificiale per i materiali termoelettrici, Science China Materials (2024). DOI:10.1007/s40843-023-2777-2
Fornito dall'Università di Tohoku