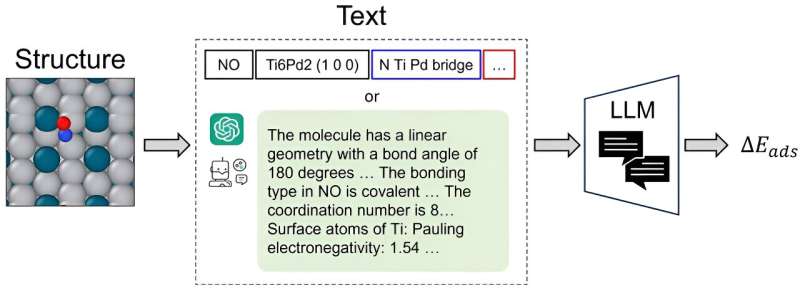
Dipendiamo dai catalizzatori per trasformare il nostro latte in yogurt, per produrre post-it dalla pasta di carta e per sbloccare fonti di energia rinnovabile come i biocarburanti. Trovare materiali catalizzatori ottimali per reazioni specifiche richiede esperimenti laboriosi e calcoli di chimica quantistica intensivi dal punto di vista computazionale.
Spesso, gli scienziati si rivolgono ai grafici delle reti neurali (GNN) per catturare e prevedere la complessità strutturale dei sistemi atomici, un sistema efficiente solo dopo aver completato la meticolosa conversione delle strutture atomiche 3D in precise coordinate spaziali sul grafico.
CatBERTa, un modello Transformer di previsione energetica, è stato sviluppato dai ricercatori del College of Engineering della Carnegie Mellon University come approccio per affrontare la previsione delle proprietà molecolari utilizzando l'apprendimento automatico.
"Questo è il primo approccio che utilizza un modello linguistico di grandi dimensioni (LLM) per questo compito, quindi stiamo aprendo una nuova strada per la modellazione", ha affermato Janghoon Ock, Ph.D. candidato nel laboratorio di Amir Barati Farimani.
Un elemento chiave di differenziazione è la capacità del modello di utilizzare direttamente il testo (linguaggio naturale) senza alcuna preelaborazione per prevedere le proprietà del sistema adsorbato-catalizzatore. Questo metodo è particolarmente vantaggioso in quanto rimane facilmente interpretabile dagli esseri umani, consentendo ai ricercatori di integrare perfettamente caratteristiche osservabili nei propri dati.
Inoltre, l’applicazione del modello del trasformatore nella loro ricerca offre spunti sostanziali. I punteggi di autoattenzione, in particolare, sono cruciali per migliorare la loro comprensione dell'interpretabilità all'interno di questo quadro.
"Non posso dire che sarà un'alternativa alle GNN all'avanguardia, ma forse possiamo usarlo come approccio complementare", ha detto Ock. "Come si dice:'Più siamo, meglio è.'"
Il modello fornisce una precisione predittiva paragonabile a quella ottenuta dalle versioni precedenti di GNN. In particolare, CatBERTa ha avuto più successo se addestrato su set di dati di dimensioni limitate. Inoltre, CatBERTa ha superato le capacità di cancellazione degli errori delle GNN esistenti.
Il team si è concentrato sull'energia di adsorbimento, ma ha affermato che l'approccio può essere esteso ad altre proprietà, come il divario HOMO-LUMO e le stabilità relative ai sistemi adsorbato-catalizzatore, dato un set di dati adeguato.
Integrando le capacità di modelli linguistici estesi con le esigenze della scoperta del catalizzatore, il team mira a semplificare il processo di screening efficace del catalizzatore. Ock sta lavorando per migliorare la precisione del modello.
I risultati sono pubblicati sulla rivista ACS Catalysis .
Ulteriori informazioni: Janghoon Ock et al, Catalyst Energy Prediction con CatBERTa:svelamento di strategie di esplorazione delle caratteristiche attraverso modelli linguistici di grandi dimensioni, catalisi ACS (2023). DOI:10.1021/acscatal.3c04956
Informazioni sul giornale: Catalisi ACS
Fornito da Ingegneria meccanica della Carnegie Mellon University