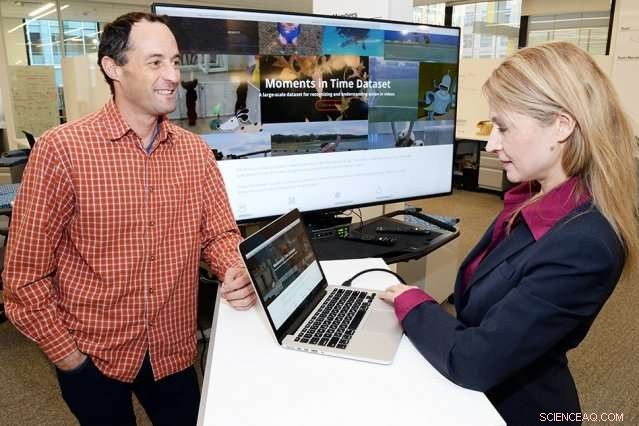
Aude Oliva (a destra), un ricercatore principale presso il Computer Science and Artificial Intelligence Laboratory e Dan Gutfreund (a sinistra), un investigatore principale presso il MIT-IBM Watson AI Laboratory e un membro dello staff presso IBM Research, sono i principali investigatori del set di dati Moments in Time, uno dei progetti relativi agli algoritmi di intelligenza artificiale finanziati dal MIT-IBM Watson AI Laboratory. Credito:John Mottern/Feature Photo Service per IBM
Una persona che guarda video che mostrano cose che si aprono:una porta, un libro, le tende, un fiore che sboccia, un cane che sbadiglia:capisce facilmente che lo stesso tipo di azione è rappresentato in ogni clip.
"I modelli informatici falliscono miseramente nell'identificare queste cose. Come fanno gli umani a farlo così facilmente?" chiede Dan Gutfreund, un investigatore principale presso il MIT-IBM Watson AI Laboratory e un membro dello staff presso IBM Research. "Elaboriamo le informazioni così come avvengono nello spazio e nel tempo. Come possiamo insegnare ai modelli di computer a farlo?"
Queste le grandi domande dietro uno dei nuovi progetti in corso al MIT-IBM Watson AI Laboratory, una collaborazione per la ricerca sulle frontiere dell'intelligenza artificiale. Lanciato lo scorso autunno, il laboratorio collega i ricercatori del MIT e dell'IBM per lavorare su algoritmi di intelligenza artificiale, l'applicazione dell'IA alle industrie, la fisica dell'IA, e modi per utilizzare l'intelligenza artificiale per promuovere la prosperità condivisa.
Il dataset Moments in Time è uno dei progetti relativi agli algoritmi di intelligenza artificiale finanziati dal laboratorio. Accoppia Gutfreund con Aude Oliva, un ricercatore principale presso il MIT Computer Science and Artificial Intelligence Laboratory, come i principali investigatori del progetto. Moments in Time si basa su una raccolta di 1 milione di video annotati di eventi dinamici che si svolgono entro tre secondi. Gutfreund e Oliva, che è anche il direttore esecutivo del MIT presso il MIT-IBM Watson AI Lab, stanno usando queste clip per affrontare uno dei prossimi grandi passi per l'IA:insegnare alle macchine a riconoscere le azioni.
Imparare dalle scene dinamiche
L'obiettivo è fornire algoritmi di apprendimento profondo con un'ampia copertura di un ecosistema di momenti visivi e uditivi che possano consentire ai modelli di apprendere informazioni che non sono necessariamente insegnate in modo supervisionato e di generalizzare a situazioni e compiti nuovi, dicono i ricercatori.
"Quando cresciamo, ci guardiamo intorno, vediamo persone e oggetti in movimento, sentiamo i suoni che fanno le persone e gli oggetti. Abbiamo molte esperienze visive e uditive. Un sistema di intelligenza artificiale deve apprendere allo stesso modo ed essere alimentato con video e informazioni dinamiche, "dice Oliva.
Per ogni categoria di azione nel set di dati, come cucinare, in esecuzione, o apertura, ce ne sono più di 2, 000 video. Le brevi clip consentono ai modelli di computer di apprendere meglio la diversità di significato intorno ad azioni ed eventi specifici.
"Questo set di dati può servire come una nuova sfida per sviluppare modelli di intelligenza artificiale che si adattano al livello di complessità e ragionamento astratto che un essere umano elabora quotidianamente, "Oliva aggiunge, descrivere i fattori coinvolti. Gli eventi possono includere persone, oggetti, animali, e natura. Possono essere simmetrici nel tempo, ad esempio aprire significa chiudere in ordine inverso. E possono essere transitori o sostenuti.
Oliva e Gutfreund, insieme ad altri ricercatori del MIT e dell'IBM, si incontravano settimanalmente per più di un anno per affrontare questioni tecniche, ad esempio come scegliere le categorie di azioni per le annotazioni, dove trovare i video, e come mettere insieme una vasta gamma in modo che il sistema di intelligenza artificiale impari senza pregiudizi. Il team ha anche sviluppato modelli di apprendimento automatico, che sono stati poi utilizzati per scalare la raccolta dei dati. "Ci siamo allineati molto bene perché abbiamo lo stesso entusiasmo e lo stesso obiettivo, "dice Oliva.
Aumentare l'intelligenza umana
Un obiettivo chiave del laboratorio è lo sviluppo di sistemi di intelligenza artificiale che vadano oltre le attività specializzate per affrontare problemi più complessi e beneficiare di un apprendimento solido e continuo. "Stiamo cercando nuovi algoritmi che non solo sfruttino i big data quando disponibili, ma anche imparare da dati limitati per aumentare l'intelligenza umana, "dice Sophie V. Vandebroek, direttore operativo di IBM Research, sulla collaborazione.
Oltre ad abbinare i punti di forza tecnici e scientifici unici di ciascuna organizzazione, IBM sta anche portando ai ricercatori del MIT un afflusso di risorse, segnalato dai suoi 240 milioni di dollari di investimenti in iniziative di intelligenza artificiale nei prossimi 10 anni, dedicato al MIT-IBM Watson AI Lab. E l'allineamento dell'interesse MIT-IBM per l'IA si sta rivelando vantaggioso, secondo Oliva.
"IBM è venuta al MIT con l'interesse di sviluppare nuove idee per un sistema di intelligenza artificiale basato sulla visione. Ho proposto un progetto in cui costruiamo set di dati per alimentare il modello sul mondo. Non era mai stato fatto prima a questo livello. Era un'impresa nuova. Ora abbiamo raggiunto la pietra miliare di 1 milione di video per la formazione sull'IA visiva, e le persone possono visitare il nostro sito Web, scarica il set di dati e i nostri modelli informatici di deep learning, cui è stato insegnato a riconoscere le azioni”.
I risultati qualitativi finora hanno mostrato che i modelli possono riconoscere bene i momenti in cui l'azione è ben inquadrata e ravvicinata, ma si accendono male quando la categoria è a grana fine o c'è confusione sullo sfondo, tra l'altro. Oliva afferma che i ricercatori del MIT e dell'IBM hanno presentato un articolo che descrive le prestazioni dei modelli di rete neurale addestrati sul set di dati, che a sua volta è stato approfondito da punti di vista condivisi. "I ricercatori IBM ci hanno dato idee per aggiungere categorie di azioni per avere più ricchezza in aree come l'assistenza sanitaria e lo sport. Hanno ampliato la nostra visione. Ci hanno dato idee su come l'IA può avere un impatto dal punto di vista del business e delle esigenze del mondo, " lei dice.
Questa prima versione del set di dati Moments in Time è uno dei più grandi set di dati video annotati da persone che catturano brevi eventi visivi e sonori, tutte contrassegnate con un'etichetta di azione o attività tra 339 classi diverse che includono un'ampia gamma di verbi comuni. I ricercatori intendono produrre più set di dati con una varietà di livelli di astrazione per servire da trampolino di lancio verso lo sviluppo di algoritmi di apprendimento in grado di costruire analogie tra le cose, immaginare e sintetizzare nuovi eventi, e interpretare scenari.
In altre parole, sono solo all'inizio, dice Gutfreund. "Ci aspettiamo che il set di dati Moments in Time consenta ai modelli di comprendere appieno le azioni e le dinamiche nei video".
Questa storia è stata ripubblicata per gentile concessione di MIT News (web.mit.edu/newsoffice/), un popolare sito che copre notizie sulla ricerca del MIT, innovazione e didattica.