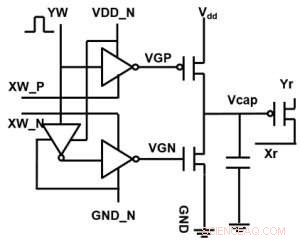
Figura 1. Schema di cella unitaria di un array cross-point basato su condensatore. Credito:IBM
IBM sta andando oltre le tecnologie digitali con un array cross-point basato su condensatori per reti neurali analogiche, esibendo potenziali miglioramenti di ordini di grandezza nei calcoli di deep learning. Le architetture informatiche analogiche sfruttano la capacità di memorizzazione e gli attributi fisici di determinati dispositivi di memoria non solo per memorizzare informazioni, ma anche per eseguire calcoli. Questo ha il potenziale per ridurre notevolmente il tempo e l'energia richiesti dai computer perché i dati non devono essere trasferiti tra la memoria e il processore. Lo svantaggio potrebbe essere una riduzione dell'accuratezza computazionale, ma per i sistemi che non richiedono un'elevata precisione, è il giusto compromesso.
Nelle reti neurali analogiche (NN), Gli array cross-point basati sulla memoria non volatile (NVM) hanno ottenuto risultati promettenti per le attività di inferenza. Però, addestrare NN ad alta precisione è difficile per i dispositivi NVM, poiché l'allenamento di successo dipende dal mantenere piccoli i cambiamenti incrementali nel peso NN (che richiede circa 1, 000 stati di aggiornamento) e simmetrico (in modo che gli aggiornamenti positivi e negativi si bilanciano in media). Tali problemi possono essere risolti utilizzando i condensatori. Poiché la carica può essere aggiunta o sottratta continuamente se il numero di elettroni è elevato, è possibile ottenere un aggiornamento del peso analogico e simmetrico. Abbiamo presentato un array cross-point basato su condensatori per reti neurali analogiche al VLSI Technology Symposium 2018. La nuova architettura ha raggiunto una simmetria e una linearità record per l'aggiornamento del peso.
La Figura 1 mostra lo schema della cella unitaria di un array cross-point basato su condensatore. Il componente chiave è il condensatore che è collegato a un transistor ad effetto di campo di lettura (FET). La carica sul condensatore rappresenta il peso sinaptico e il condensatore viene caricato e scaricato con due FET della sorgente di corrente. La Figura 2 mostra la variazione misurata nella conduttanza del FET di lettura di una singola cella, e la corrispondente tensione del condensatore rispettivamente, applicando dieci cicli di 400 aggiornamenti positivi seguiti da 400 aggiornamenti negativi. La Figura 3 confronta i fattori sperimentali di aggiornamento della non linearità per la nostra sinapsi analogica basata su condensatore con altre tecnologie NVM. La cella unitaria basata su condensatore fornisce la migliore simmetria e linearità dimostrata fino ad oggi. La Figura 4 mostra l'aggiornamento parallelo del peso su un array 2×2.
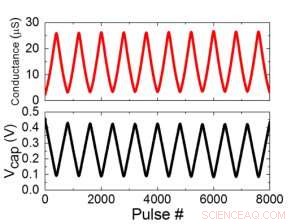
Figura 2. (a) Risultati sperimentali per l'aggiornamento di una singola cella con 8000 impulsi. (b) Variazione di tensione del condensatore corrispondente. Larghezza di impulso 50 ns, periodo:500 ns. Credito:IBM
Anche se i condensatori sono volatili, la perdita potrebbe essere compensata durante l'aggiornamento del peso. Poiché l'allenamento va avanti ripetutamente, cicli all'indietro e di aggiornamento del peso, i pesi dopo il decadimento nel ciclo precedente vengono utilizzati nell'allenamento per il ciclo successivo e vengono aggiornati. Perciò, non sono necessari cicli di aggiornamento intenzionale. Abbiamo testato l'effetto del tempo di ritenzione sull'allenamento, utilizzando una rete completamente connessa. Ha un livello di input, due strati nascosti, e un livello di output (Figura 5) ed è stato addestrato sul set di dati MNIST mediante discesa del gradiente stocastico e retropropagazione. Supponendo che la lunghezza del ciclo di allenamento per livello (avanti+indietro+aggiornamento) sia di 200 ns e il peso sinaptico decada con la costante di tempo RC τ, abbiamo scoperto che la penalità nell'accuratezza dell'allenamento dovuta alla perdita di carica del condensatore diventa trascurabile quando τ> 106 × la durata del ciclo di allenamento (Figura 6). Abbiamo anche testato il requisito del tempo di ritenzione per una rete convoluzionale. La nostra rete di test ha due livelli convoluzionali con due livelli di pooling e due livelli completamente connessi (Figura 7). A causa della condivisione del peso (riutilizzo) negli strati convolutivi, i requisiti di ritenzione per una rete neurale convoluzionale (CNN) sono circa 600 maggiori (Figura 8).
Stimiamo la scalabilità di questo array basato su condensatori in funzione della dispersione sia per le reti neurali completamente connesse che per quelle convoluzionali (Figura 9). I punti dati del cerchio mostrano che il condensatore scala linearmente con la perdita del transistor di passaggio. I punti dati quadrati mostrano che quando la perdita è grande, l'area della cella è dominata dai condensatori; quando la corrente di dispersione è piccola, l'area sarà dominata da FET nella cella. Per la tecnologia DRAM con perdite di 1 fA/cella è necessario un condensatore <1fF/cella per la rete neurale completamente connessa e ~ 100 fF/cella per la CNN. La scalabilità verso input più grandi e più livelli necessita di ulteriori studi. Anche se potrebbe essere necessario un condensatore più grande quando l'ingresso diventa più grande, i nostri risultati preliminari (da pubblicare) mostrano che l'ottimizzazione di rete/algoritmo potrebbe ridurre il fabbisogno di condensatori.
IBM sta ora lavorando su una nuova memoria ideale con un comportamento analogico ottimizzato. Questi condensatori consentiranno l'implementazione del core analogico AI su un programma accelerato, poiché la tecnologia e il processo sono disponibili.
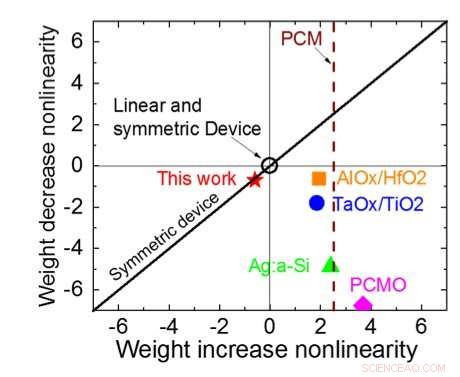
Figura 3. Non linearità della conduttanza di questo lavoro rispetto ad altre tecnologie NVM. Credito:IBM
Oltre al nostro approccio con i condensatori, IBM sta esplorando altri nuovi elementi per la memoria e il calcolo analogici come la memoria a cambiamento di fase (PCM) e la RAM resistiva (RRAM). Questi elementi variano in termini di aree cellulari, ritenzione, simmetria, e maturità. Gli acceleratori analogici sono un componente della pipeline di acceleratori hardware AI di IBM Research. La pipeline inizia con l'ottenere il massimo dagli acceleratori GPU esistenti, seguito da innovativi core digitali AI che sfruttano il calcolo approssimativo.
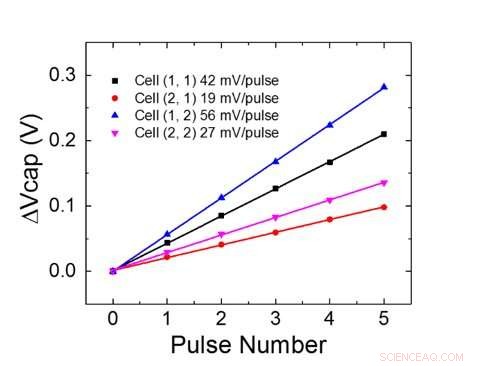
Figura 4. Aggiornamento del peso parallelo su un array 2×2. Credito:IBM
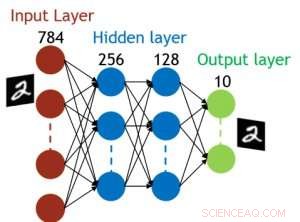
Figura 5. Struttura simulata per rete neurale completamente connessa. Credito:IBM
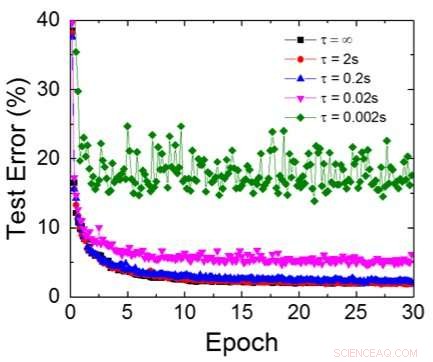
Figura 6. Errore di test simulato del set di dati MNIST, assumendo che i pesi decadano continuamente con una costante di tempo RC diversa , Durata del ciclo di allenamento di 200 ns. Credito:IBM
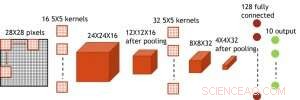
Figura 7. Struttura simulata per rete neurale convoluzionale. Credito:IBM
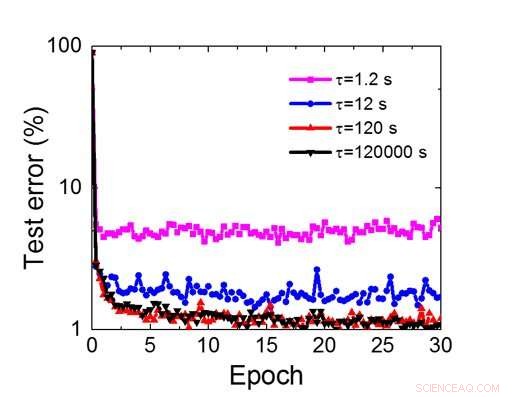
Figura 8. Requisito del tempo di ritenzione simulato per questo array basato su condensatori per addestrare la rete neurale convoluzionale. Credito:IBM
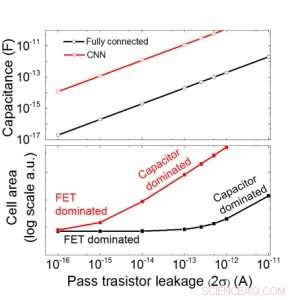
Figura 9. Scalabilità di questo array basato su condensatori in funzione della dispersione per reti neurali sia completamente connesse che convoluzionali. Credito:IBM