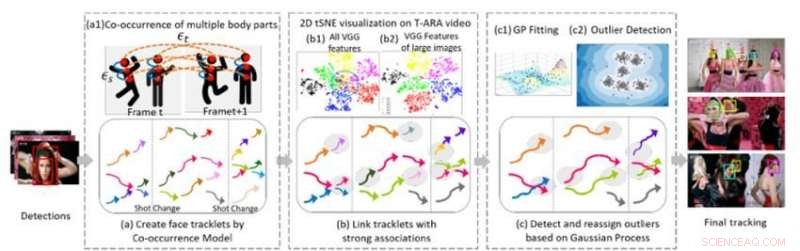
Figura 1. Tre componenti algoritmici fondamentali del nostro metodo per il tracciamento multi-faccia in una sequenza video. Credito:IBM
Alla recente conferenza 2018 su Computer Vision e Pattern Recognition, Ho presentato un nuovo algoritmo per il tracciamento multi-faccia, una componente essenziale nella comprensione del video. Per comprendere le sequenze visive che coinvolgono le persone, I sistemi di intelligenza artificiale devono essere in grado di tracciare più individui attraverso le scene, nonostante la modifica dell'angolazione della telecamera, illuminazione, e apparenze. Il nuovo algoritmo consente ai sistemi di intelligenza artificiale di svolgere questo compito.
Il lavoro precedente in quest'area si è in gran parte concentrato sul monitoraggio di una o più persone all'interno di un'inquadratura. Il passaggio successivo consiste nel tenere traccia di più persone in un intero video composto da molte inquadrature diverse. Questo compito è impegnativo perché le persone possono uscire e rientrare nel video ripetutamente. Il loro aspetto può cambiare drasticamente grazie al guardaroba, acconciatura, e trucco. Le loro pose cambiano, e le loro facce possono essere parzialmente occluse dall'angolo di visione, illuminazione, o altri oggetti nella scena. Anche l'angolazione della telecamera e lo zoom cambiano, e caratteristiche come scarsa qualità dell'immagine, cattiva illuminazione, e il motion blur può aumentare la difficoltà del compito. Le tecnologie di riconoscimento facciale esistenti possono funzionare in casi più limitati, dove le immagini sono di buona qualità e mostrano il volto intero di una persona, ma fallisce nel video non vincolato, dove i volti delle persone possono essere di profilo, occluso, ritagliato, o sfocato.
Un metodo per il monitoraggio multi-faccia
Collaborando con il professor Ying Hung, del Dipartimento di Statistica e Biostatistica della Rutgers University, abbiamo sviluppato un metodo per individuare diversi individui in una sequenza video e per riconoscerli se escono e poi rientrano nel video, anche se sembrano molto diversi. Per fare questo, prima creiamo tracklet per le persone presenti nel video. I tracklet si basano sulla co-occorrenza di più parti del corpo (viso, testa e spalle, Torace, e tutto il corpo) in modo che le persone possano essere seguite anche quando non sono completamente in vista della telecamera (ad es. i loro volti sono girati dall'altra parte o occlusi da altri oggetti). Formuliamo il problema dell'inseguimento multi-persona come una struttura grafica G =(ν, ε) con due tipi di spigoli:εs e εt. I bordi spaziali s denotano le connessioni di diverse parti del corpo di un candidato all'interno di un frame e vengono utilizzati per generare lo stato ipotizzato di un candidato. I bordi temporali εt denotano le connessioni delle stesse parti del corpo su frame adiacenti e sono usati per stimare lo stato di ogni singola persona in frame diversi. Generiamo face tracklet utilizzando riquadri di delimitazione del viso dai tracklet di ogni singola persona ed estraiamo le caratteristiche facciali per il raggruppamento.
La seconda parte del metodo collega i tracklet che appartengono alla stessa persona. La Figura 1 (b) mostra la visualizzazione tSNE 2-D della funzione VGG-face estratta su un video musicale. Mostra che rispetto a tutte le caratteristiche (b1), caratteristica delle immagini grandi (b) sono più discriminanti. Costruiamo connessioni univoche tra tracklet analizzando la risoluzione dell'immagine del viso degli oggetti e le distanze relative delle caratteristiche profonde estratte. Questo passaggio genera un risultato di clustering iniziale. Studi empirici mostrano che i modelli basati sulla CNN sono sensibili alla sfocatura e al rumore dell'immagine perché le reti sono generalmente addestrate su immagini di alta qualità. Generiamo risultati di clustering finali robusti utilizzando un modello di processo gaussiano (GP) per compensare le limitazioni profonde delle funzionalità e acquisire la ricchezza dei dati. Diverso dagli approcci basati sulla CNN, I modelli GP forniscono un approccio parametrico flessibile per catturare la non linearità e la correlazione spazio-temporale del sistema sottostante. Perciò, è uno strumento interessante da abbinare all'approccio basato sulla CNN per ridurre ulteriormente la dimensione senza perdere informazioni complesse e importare spazio-temporali. Applichiamo il modello GP per rilevare valori anomali, rimuovere le connessioni tra outlier e altri tracklet, e quindi riassegnare gli outlier ai cluster raffinati formati dopo che gli outlier sono stati disconnessi, producendo così cluster di alta qualità.
Tracciamento multi-faccia nei video musicali
Per valutare le prestazioni del nostro approccio, lo abbiamo confrontato con metodi all'avanguardia nell'analisi di set di dati impegnativi di video non vincolati. In una serie di esperimenti, abbiamo usato video musicali, che presentano una qualità dell'immagine elevata ma significativa, rapidi cambiamenti di scena, impostazione della fotocamera, movimento della fotocamera, trucco, e accessori (come gli occhiali). Il nostro algoritmo ha superato altri metodi per quanto riguarda sia l'accuratezza del clustering che il tracciamento. La purezza del clustering è stata sostanzialmente migliore con il nostro algoritmo rispetto agli altri metodi (0,86 per il nostro algoritmo rispetto a 0,56 per il concorrente più vicino che utilizza uno dei video musicali). Inoltre, il nostro metodo determina automaticamente il numero di persone, o grappoli, da tracciare senza la necessità di analisi video manuale.
Anche le prestazioni di monitoraggio del nostro algoritmo erano superiori ai metodi più avanzati per la maggior parte delle metriche, inclusi Richiamo e Precisione. Il nostro metodo ha notevolmente aumentato la maggior parte delle tracce (MT) e ridotto le istanze di cambio di identità (IDS) e i frammenti di traccia (Frag). Il video seguente mostra i risultati di monitoraggio di esempio in diversi video musicali. Il nostro algoritmo tiene traccia di più individui in modo affidabile in diverse riprese nell'intero video non vincolato, anche se alcuni individui hanno un aspetto facciale molto simile, più cantanti principali appaiono in uno sfondo disordinato pieno di pubblico, o alcune facce sono pesantemente occluse. Questa struttura per il tracciamento multi-faccia nei video non vincolati è un passo importante per migliorare la comprensione del video. L'algoritmo e le sue prestazioni sono descritti in modo più dettagliato nel nostro documento CVPR, "Un metodo senza priorità per il monitoraggio multi-faccia in video non vincolati".
Questa storia è stata ripubblicata per gentile concessione di IBM Research. Leggi la storia originale qui.