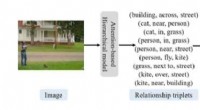
Il modello è in grado di apprendere caratteristiche che codificano bene il contenuto semantico delle immagini. Data una query di immagine (immagine a sinistra), il modello è in grado di recuperare immagini semanticamente simili (raffigurano lo stesso tipo di oggetto), sebbene possano essere visivamente dissimili (colori diversi, sfondi o composizioni). Attestazione:arXiv:1807.02110 [cs.CV]
Ricercatori dell'Universitat Autonoma de Barcelona, Carnegie Mellon University e International Institute of Information Technology, Hyderabad, India, hanno sviluppato una tecnica che potrebbe consentire agli algoritmi di deep learning di apprendere le caratteristiche visive delle immagini in modo auto-supervisionato, senza la necessità di annotazioni da parte di ricercatori umani.
Per ottenere risultati notevoli nelle attività di visione artificiale, gli algoritmi di deep learning devono essere addestrati su set di dati annotati su larga scala che includono informazioni estese su ogni immagine. Però, raccogliere e annotare manualmente queste immagini richiede enormi quantità di tempo, risorse, e fatica umana.
"Miriamo a dare ai computer la capacità di leggere e comprendere le informazioni testuali in qualsiasi tipo di immagine nel mondo reale, "dice Dimosthenis Karatzas, uno dei ricercatori che ha condotto lo studio, in un'intervista con Tech Xplore .
Gli esseri umani usano le informazioni testuali per interpretare tutte le situazioni presentate loro, così come per descrivere ciò che sta accadendo intorno a loro o in una particolare immagine. I ricercatori stanno ora cercando di dare capacità simili alle macchine, poiché ciò ridurrebbe notevolmente la quantità di risorse spese per l'annotazione di set di dati di grandi dimensioni.
Nel loro studio, Karatzas e i suoi colleghi hanno progettato modelli computazionali che uniscono le informazioni testuali sulle immagini con le informazioni visive in esse contenute, utilizzando i dati di Wikipedia o altre piattaforme online. Hanno quindi utilizzato questi modelli per addestrare algoritmi di deep learning su come selezionare buone caratteristiche visive che descrivono semanticamente le immagini.
Come in altri modelli basati su reti neurali convoluzionali (CNN), le caratteristiche vengono apprese end-to-end, con diversi livelli che imparano automaticamente a concentrarsi su cose diverse, che vanno dai dettagli a livello di pixel nei primi livelli a caratteristiche più astratte negli ultimi.
Il modello sviluppato da Karatzas e dai suoi colleghi, però, non richiede annotazioni specifiche per ogni immagine. Anziché, il contesto testuale in cui si trova l'immagine (es. un articolo di Wikipedia) funge da segnale di supervisione.
In altre parole, la nuova tecnica creata da questo team di ricercatori fornisce un'alternativa agli algoritmi completamente non supervisionati, che utilizza elementi non visivi in correlazione con le immagini, fungere da fonte di formazione autogestita.
"Questo si rivela un modo molto efficiente per imparare a rappresentare le immagini in un computer, senza richiedere annotazioni esplicite – etichette sul contenuto delle immagini – che richiedono molto tempo e sforzo manuale per essere generate, " spiega Karatzas. "Queste nuove rappresentazioni di immagini, appreso in modo autocontrollato, sono sufficientemente discriminatori da poter essere utilizzati in una serie di tipiche attività di visione artificiale, come la classificazione delle immagini e il rilevamento di oggetti".
La metodologia sviluppata dai ricercatori consente l'uso del testo come segnale di supervisione per apprendere caratteristiche utili dell'immagine. Questo potrebbe aprire nuove possibilità per l'apprendimento profondo, consentendo agli algoritmi di apprendere caratteristiche dell'immagine di buona qualità senza la necessità di annotazioni, semplicemente analizzando le fonti testuali e visive che sono prontamente disponibili online.
Addestrando i loro algoritmi utilizzando immagini da Internet, i ricercatori hanno evidenziato il valore dei contenuti prontamente disponibili online.
"Il nostro studio ha dimostrato che il Web può essere sfruttato come un insieme di dati rumorosi per apprendere rappresentazioni utili sul contenuto delle immagini, " dice Karatzas. "Non siamo i primi, né gli unici che accennavano in questa direzione, ma il nostro lavoro ha dimostrato un modo specifico per farlo, facendo uso degli articoli di Wikipedia come dati da cui imparare."
Negli studi futuri, Karatzas e i suoi colleghi cercheranno di identificare i modi migliori per utilizzare le informazioni testuali incorporate nell'immagine per descrivere e rispondere automaticamente alle domande sul contenuto dell'immagine.
"Continueremo il nostro lavoro sull'incorporamento congiunto di informazioni testuali e visive, cercando nuovi modi per eseguire il recupero semantico toccando le informazioni rumorose disponibili nel Web e nei social media, "aggiunge Karatzas.
© 2018 Tech Xplore