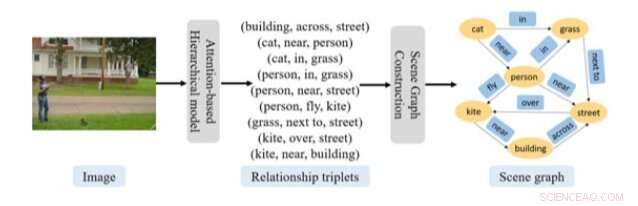
Procedura generale di previsione del grafico della scena proposta nel recente articolo. Credito:Gao et al.
I ricercatori dell'Università di Shanghai hanno recentemente sviluppato un nuovo approccio basato su reti neurali ricorrenti (RNN) per prevedere i grafici delle scene dalle immagini. Il loro approccio include un modello composto da due RNN basati sull'attenzione, nonché un componente di localizzazione delle entità.
Negli ultimi dieci anni o giù di lì, ricercatori nel campo dell'intelligenza artificiale (AI) hanno sviluppato una varietà di strumenti automatici per gestire, analizzare e recuperare immagini digitali. Per rappresentare il contenuto delle immagini, gli approcci tradizionali in genere utilizzano parole chiave o funzionalità multi-vista. Però, fare affidamento su caratteristiche o parole chiave spesso porta a una comprensione limitata delle immagini, non riuscendo a fornire una conoscenza completa su di loro.
Per ovviare a queste carenze, alcuni anni fa, un team di ricercatori della Stanford University, Istituto Max Planck per l'informatica, Yahoo Labs e Snapchat hanno proposto l'uso di un "grafico di scena, ' un tipo di struttura dati per descrivere concetti visivi in un'immagine. I grafici delle scene possono memorizzare la descrizione di una scena rappresentata nelle immagini come un grafico strutturato in cui i nodi rappresentano le informazioni sull'oggetto e i bordi forniscono previsioni tra due nodi.
Queste rappresentazioni strutturate possono aiutare gli utenti a gestire le immagini digitali. Però, prevedere un grafico di una scena è spesso difficile, in quanto richiede strumenti efficaci per riconoscere gli oggetti, così come i loro attributi e le interazioni tra di loro.
Sebbene ci siano diversi approcci esistenti per prevedere i grafici delle scene, la maggior parte di questi ha limitazioni sostanziali. Nel loro studio, i ricercatori dell'Università di Shangai hanno deciso di sviluppare un modello basato sulla rete neurale per prevedere i grafici della scena da una prospettiva orientata all'attenzione visiva.
"Un grafico di scena fornisce una potente struttura di conoscenza intermedia per vari compiti visivi, compreso il recupero di immagini semantiche, didascalia delle immagini, e risposte visive alle domande, " hanno scritto i ricercatori nel loro articolo, che è stato pubblicato su Wiley Online Library. "In questo documento, il compito di prevedere un grafico di scena per un'immagine è formulato come due problemi collegati, cioè riconoscere le triplette di relazione, strutturato come, e costruire il grafico della scena dalle triplette di relazione riconosciute."
L'approccio ideato da questo team di ricercatori ha due componenti chiave, uno mirava a riconoscere ciò che chiamano "triplette di relazione" e l'altro a costruire un grafico di scena. Per riconoscere le triplette di relazione, i ricercatori hanno utilizzato un modello composto da due RNN basati sull'attenzione in un'organizzazione gerarchica.
"La prima rete genera un vettore argomento per ogni tripletta di relazioni, mentre la seconda rete predice ogni parola in quella tripletta di relazione dato il vettore dell'argomento, " hanno spiegato i ricercatori nel loro articolo. "Questo approccio cattura con successo la struttura compositiva e la dipendenza contestuale di un'immagine e le triplette di relazione che descrivono la sua scena".
Una volta che questo modello basato su RNN ha estratto le informazioni rilevanti da un'immagine, la seconda componente del loro approccio utilizza questi dati per costruire grafici di scena. Per questo passaggio, i ricercatori hanno utilizzato un approccio di localizzazione delle entità, che può determinare la struttura del grafico utilizzando le informazioni di attenzione disponibili. Oltre a queste due componenti, i ricercatori hanno utilizzato un algoritmo per chiarire il processo attraverso il quale il loro approccio converte le informazioni sulla tripletta di relazione generata in un grafico di scena.
Il loro approccio è stato valutato utilizzando il popolare set di dati del genoma visivo (VG) e il set di dati delle relazioni visive (VRD). Ai fini del loro studio, i ricercatori hanno annotato le immagini in questi set di dati con una serie di terzine, etichettando ogni coppia soggetto e oggetto con informazioni sulla posizione.
"I risultati degli esperimenti su due set di dati popolari dimostrano che l'approccio ricorrente gerarchico dalla prospettiva orientata all'attenzione visiva all'interno del nostro modello ha un netto miglioramento dei risultati rispetto ai modelli di base, " hanno scritto i ricercatori. "Nel lavoro futuro, abbiamo in programma di arricchire il grafico della scena con una semantica di alto livello e attributi più diversificati."
© 2019 Science X Network