I computer sono bravi a classificare le immagini in base agli oggetti trovati con loro, ma sono sorprendentemente incapaci di capire quando due oggetti in una singola immagine sono uguali o diversi l'uno dall'altro. Una nuova ricerca aiuta a mostrare perché questo compito è così difficile per i moderni algoritmi di visione artificiale. Credito:Serre lab / Brown University
Gli algoritmi di visione artificiale hanno fatto molta strada negli ultimi dieci anni. Hanno dimostrato di essere altrettanto bravi o migliori delle persone in compiti come categorizzare le razze di cani o gatti, e hanno la straordinaria capacità di identificare volti specifici da un mare di milioni.
Ma la ricerca degli scienziati della Brown University mostra che i computer falliscono miseramente in una classe di compiti con cui anche i bambini piccoli non hanno problemi:determinare se due oggetti in un'immagine sono uguali o diversi. In un documento presentato la scorsa settimana al meeting annuale della Cognitive Science Society, il team Brown fa luce sul motivo per cui i computer sono così scarsi in questo tipo di attività e suggerisce strade verso sistemi di visione artificiale più intelligenti.
"C'è molta eccitazione su ciò che la visione artificiale è stata in grado di ottenere, e ne condivido molto, " ha detto Thomas Serre, professore associato di scienze cognitive, scienze linguistiche e psicologiche alla Brown e autore senior dell'articolo. "Ma pensiamo che lavorando per comprendere i limiti degli attuali sistemi di visione artificiale come abbiamo fatto qui, possiamo davvero muoverci verso il nuovo, sistemi molto più avanzati piuttosto che semplicemente modificare i sistemi che già abbiamo."
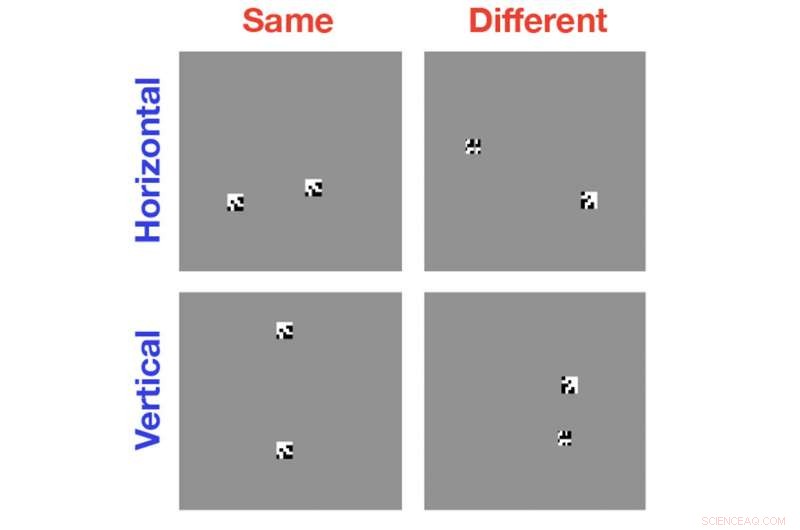
Per lo studio, Serre e i suoi colleghi hanno utilizzato algoritmi di visione artificiale all'avanguardia per analizzare semplici immagini in bianco e nero contenenti due o più forme generate casualmente. In alcuni casi gli oggetti erano identici; a volte erano gli stessi ma con un oggetto ruotato rispetto all'altro; a volte gli oggetti erano completamente diversi. Al computer è stato chiesto di identificare la relazione uguale o diversa.
Lo studio ha dimostrato che, anche dopo centinaia di migliaia di esempi di formazione, gli algoritmi non erano migliori della possibilità di riconoscere la relazione appropriata. La domanda, poi, Ecco perché questi sistemi sono così scarsi in questo compito.
Serre e i suoi colleghi avevano il sospetto che avesse qualcosa a che fare con l'incapacità di questi algoritmi di visione artificiale di individuare gli oggetti. Quando i computer guardano un'immagine, non possono effettivamente dire dove si ferma un oggetto nell'immagine e lo sfondo, o un altro oggetto, inizia. Vedono solo una raccolta di pixel che hanno modelli simili a raccolte di pixel che hanno imparato ad associare a determinate etichette. Funziona bene per problemi di identificazione o categorizzazione, ma cade a pezzi quando si tenta di confrontare due oggetti.
Per dimostrare che questo era davvero il motivo per cui gli algoritmi si stavano guastando, Serre e il suo team hanno eseguito esperimenti che hanno sollevato il computer dal dover individuare gli oggetti da solo. Invece di mostrare al computer due oggetti nella stessa immagine, i ricercatori hanno mostrato al computer gli oggetti uno alla volta in immagini separate. Gli esperimenti hanno mostrato che gli algoritmi non hanno avuto problemi nell'apprendere una relazione uguale o diversa fintanto che non hanno dovuto visualizzare i due oggetti nella stessa immagine.
La fonte del problema nell'individuare gli oggetti, Serre dice, è l'architettura dei sistemi di apprendimento automatico che alimentano gli algoritmi. Gli algoritmi utilizzano reti neurali convoluzionali, strati di unità di elaborazione connesse che imitano vagamente le reti di neuroni nel cervello. Una differenza fondamentale rispetto al cervello è che le reti artificiali sono esclusivamente "feed-forward", il che significa che le informazioni hanno un flusso unidirezionale attraverso gli strati della rete. Non è così che funziona il sistema visivo negli esseri umani, secondo Serre.
"Se osservi l'anatomia del nostro sistema visivo, scopri che ci sono molte connessioni ricorrenti, dove le informazioni vanno da un'area visiva superiore a un'area visiva inferiore e viceversa, " ha detto Serre.
Anche se non è chiaro esattamente cosa fanno quei feedback, Serre dice, è probabile che abbiano qualcosa a che fare con la nostra capacità di prestare attenzione a certe parti del nostro campo visivo e di fare rappresentazioni mentali di oggetti nella nostra mente.
"Presumibilmente le persone si occupano di un oggetto, costruire una rappresentazione delle caratteristiche che è legata a quell'oggetto nella loro memoria di lavoro, " Serre ha detto. "Poi spostano la loro attenzione su un altro oggetto. Quando entrambi gli oggetti sono rappresentati nella memoria di lavoro, il tuo sistema visivo è in grado di fare confronti come uguale o diverso."
Serre e i suoi colleghi ipotizzano che il motivo per cui i computer non possono fare nulla del genere è perché le reti neurali feed-forward non consentono il tipo di elaborazione ricorrente necessaria per questa individuazione e rappresentazione mentale degli oggetti. Potrebbe essere, Serre dice, che rendere più intelligente la visione artificiale richiederà reti neurali che si avvicinino più da vicino alla natura ricorrente dell'elaborazione visiva umana.