
Esempio di immagine del viso reale dal set di dati fornito dal documento "Crescita progressiva di GAN per una migliore qualità, Stabilità, e variazione”. Credito:Karras et al.
I ricercatori dell'Università di Shenzhen hanno recentemente ideato un metodo per rilevare immagini generate da reti neurali profonde. Il loro studio, pre-pubblicato su arXiv, identificato una serie di funzionalità per acquisire statistiche sulle immagini a colori in grado di rilevare le immagini generate utilizzando gli attuali strumenti di intelligenza artificiale.
"La nostra ricerca è stata ispirata dal rapido sviluppo di modelli generativi di immagini e dalla diffusione di immagini false generate, "Bin Li, uno dei ricercatori che ha condotto lo studio, detto Tech Xplore . "Con l'avvento di modelli avanzati di generazione di immagini, come le reti generative avversarie (GAN) e gli autoencoder variazionali, le immagini generate da reti profonde diventano sempre più fotorealistiche, e non è più facile identificarli con gli occhi umani, che comporta gravi rischi per la sicurezza".
Recentemente, diversi ricercatori e piattaforme multimediali globali hanno espresso la loro preoccupazione per i rischi posti dalle reti neurali artificiali addestrate a generare immagini. Ad esempio, algoritmi di deep learning come le reti generative avversarie (GAN) e gli autoencoder variazionali potrebbero essere utilizzati per generare immagini e video realistici per notizie false o potrebbero facilitare le frodi online e la contraffazione di informazioni personali sui social media.
Gli algoritmi GAN sono addestrati per generare immagini sempre più realistiche attraverso un processo di tentativi ed errori in cui un algoritmo genera immagini e un altro, il discriminatore, fornisce feedback per rendere queste immagini più realistiche. Ipoteticamente, questo discriminatore potrebbe anche essere addestrato a rilevare immagini false da quelle reali. Però, questi algoritmi utilizzano principalmente immagini RGB come input e non considerano le disparità nelle componenti del colore, quindi la loro performance sarebbe molto probabilmente insoddisfacente.

Esempio di immagine del viso generata dal set di dati fornito dal documento "Crescita progressiva di GAN per una migliore qualità, Stabilità, e variazione”. Credito:Karras et al.
Nel loro studio, Li e i suoi colleghi hanno analizzato le differenze tra le immagini generate dal GAN e le immagini reali, proponendo un insieme di caratteristiche che potrebbero aiutare efficacemente a classificarli. Il metodo risultante funziona analizzando le differenze nelle componenti di colore tra le immagini vere e generate.
"La nostra idea di base è che le pipeline di generazione delle immagini reali e delle immagini generate siano piuttosto diverse, quindi le due classi di immagini dovrebbero avere alcune proprietà diverse, "Haodong Li, uno dei ricercatori ha spiegato. "Infatti, provengono da diverse condutture. Per esempio, le immagini reali sono generate da dispositivi di imaging come fotocamere e scanner per catturare una scena reale, mentre le immagini generate vengono create in modo totalmente diverso con convoluzione, connessione, e attivazione da reti neurali. Le differenze possono determinare proprietà statistiche diverse. In questo studio, abbiamo considerato principalmente le proprietà statistiche dei componenti del colore."
I ricercatori hanno scoperto che sebbene le immagini generate e le immagini reali siano simili nello spazio colore RGB, hanno proprietà statistiche marcatamente differenti nelle componenti di crominanza di HSV e YCbCr. Hanno anche osservato differenze durante l'assemblaggio della R, G, e componenti di colore B insieme.
Il set di funzionalità che hanno proposto, che consiste in matrici di co-occorrenza estratte dai residui di filtraggio passa-alto dell'immagine di diverse componenti di colore, sfrutta queste differenze, catturare le disparità di colore tra le immagini reali e quelle generate. Questo set di funzionalità è di piccole dimensioni e può funzionare bene anche se addestrato su un piccolo set di dati di immagini.
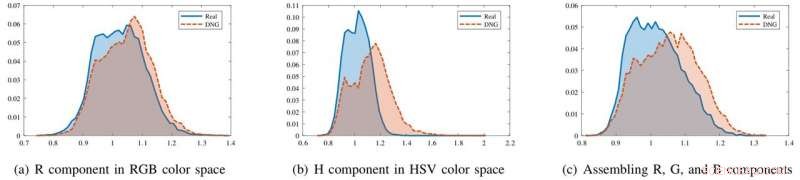
Gli istogrammi delle statistiche delle immagini per immagini reali (blu) e immagini generate in rete profonda (DNG) (rosso) in diverse componenti di colore. Nella componente R, i due istogrammi sono in gran parte sovrapposti. Però, nel componente H o assemblando R, G, componenti B insieme, gli istogrammi sono più separabili. Credito:Li et al.
Li e i suoi colleghi hanno testato le prestazioni del loro metodo su tre set di dati di immagini:CelebFaces Attributes, CelebA di alta qualità, ed etichettati volti in natura. I loro risultati sono stati molto promettenti, con il set di funzionalità che funziona bene su tutti e tre i set di dati.
"La scoperta più significativa del nostro studio è che le immagini generate da reti profonde possono essere facilmente rilevate estraendo caratteristiche da determinati componenti di colore, sebbene le immagini generate possano essere visivamente indistinguibili con gli occhi umani, " Haodong Li ha detto. "Quando sono disponibili campioni di immagini generate o modelli generativi, le funzionalità proposte dotate di un classificatore binario possono differenziare efficacemente tra immagini generate e immagini reali. Quando i modelli generativi sono sconosciuti, le caratteristiche proposte insieme a un classificatore a una classe possono anche raggiungere prestazioni soddisfacenti."
Lo studio potrebbe avere una serie di implicazioni pratiche. Primo, il metodo potrebbe aiutare a identificare le immagini false online.
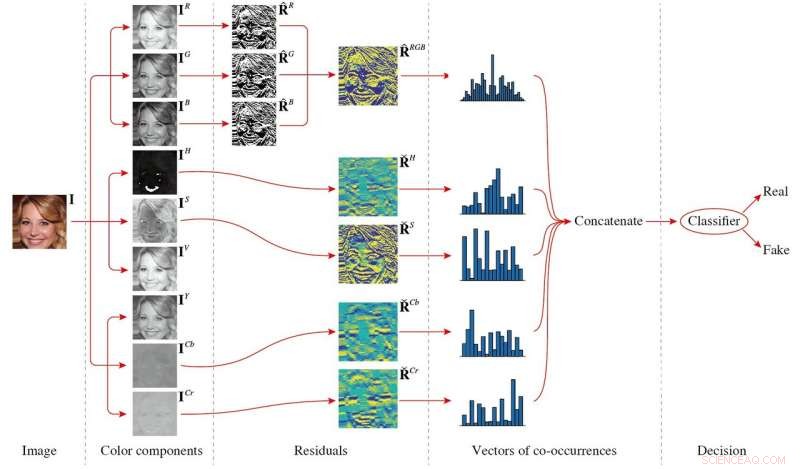
Il quadro generale del metodo proposto. L'immagine in ingresso viene prima scomposta in diverse componenti di colore, e poi viene calcolato il residuo di ogni componente di colore. Per calcolare le co-occorrenze, la R, G, e componenti B sono assemblati, mentre l'H, S, Cb, e i componenti Cr vengono elaborati in modo indipendente. Finalmente, tutti i vettori di co-occorrenza sono concatenati e alimentati a un classificatore per ottenere il risultato della decisione. Credito:Li et al.
Their findings also imply that several inherent color properties of real images have not yet been effectively replicated by existing generative models. Nel futuro, this knowledge could be used to build new models that generate even more realistic images.
Finalmente, their study proves that different generation pipelines used to produce real images and generated images are reflected in the properties of the images produced. Color components comprise merely one of the ways in which these two types of images differ, so further studies could focus on other properties.
"In futuro, we plan to improve the image generation performance by applying the findings of this research to image generative models, " Jiwu Huang, one of the researchers said. "Per esempio, including the disparity metrics of color components for real and generated images into the objective function of a GAN model could produce more realistic images. We will also try to leverage other inherent information from the real image generation pipeline, such as sensor pattern noises or properties of color filter array, to develop more effective and robust methods for identifying generated images."
© 2018 Tech Xplore














