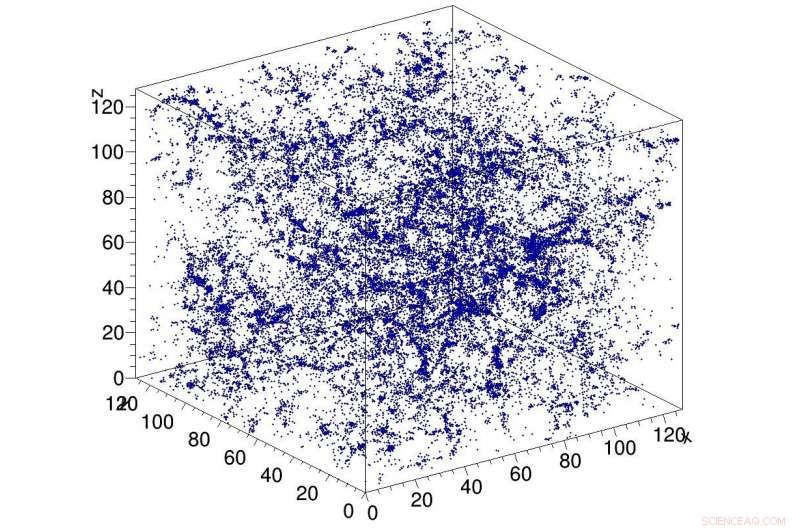
Esempio di simulazione della materia oscura nell'universo, utilizzato come input alla rete CosmoFlow. CosmoFlow è la prima applicazione scientifica su larga scala a utilizzare il framework TensorFlow su una piattaforma di elaborazione ad alte prestazioni basata su CPU con training sincrono. Credito:Lawrence Berkeley National Laboratory
Una collaborazione nel Big Data Center tra scienziati computazionali del Lawrence Berkeley National Laboratory (Berkeley Lab) National Energy Research Scientific Computing Center (NERSC) e ingegneri di Intel e Cray ha prodotto un altro primato nella ricerca di applicare il deep learning alla scienza ad alta intensità di dati:CosmoFlow , la prima applicazione scientifica su larga scala a utilizzare il framework TensorFlow su una piattaforma di elaborazione ad alte prestazioni basata su CPU con formazione sincrona. È anche il primo ad elaborare volumi di dati spaziali tridimensionali (3D) a questa scala, dando agli scienziati una piattaforma completamente nuova per ottenere una comprensione più profonda dell'universo.
I problemi dei "big data" cosmologici vanno oltre il semplice volume di dati archiviati su disco. Le osservazioni dell'universo sono necessariamente finite, e la sfida che i ricercatori devono affrontare è come estrarre la maggior parte delle informazioni dalle osservazioni e dalle simulazioni disponibili. Ad aggravare il problema è che i cosmologi tipicamente caratterizzano la distribuzione della materia nell'universo usando misure statistiche della struttura della materia sotto forma di funzioni a due o tre punti o altre statistiche ridotte. Metodi come l'apprendimento profondo in grado di catturare tutte le caratteristiche nella distribuzione della materia fornirebbero una maggiore comprensione della natura dell'energia oscura. I primi a rendersi conto che il deep learning poteva essere applicato a questo problema furono Siamak Ravanbakhsh e i suoi colleghi, come indicato negli atti della 33a Conferenza internazionale sull'apprendimento automatico. Però, i colli di bottiglia computazionali durante l'ampliamento della rete e del set di dati hanno limitato la portata del problema che potrebbe essere affrontato.
Motivato ad affrontare queste sfide, CosmoFlow è stato progettato per essere altamente scalabile; per elaborare grandi, set di dati cosmologici 3-D; e per migliorare le prestazioni di formazione di deep learning sui moderni supercomputer HPC come il supercomputer Cray XC40 Cori basato su processore Intel al NERSC. CosmoFlow si basa sul famoso framework di machine learning TensorFlow e usa Python come front-end. L'applicazione sfrutta il plug-in di apprendimento automatico Cray PE per ottenere un ridimensionamento senza precedenti del framework TensorFlow Deep Learning a più di 8, 000 nodi. Beneficia anche della tecnologia di accelerazione I/O DataWarp di Cray, che fornisce il throughput di I/O necessario per raggiungere questo livello di scalabilità.
In un documento tecnico che sarà presentato a SC18 a novembre, il team di CosmoFlow descrive l'applicazione e gli esperimenti iniziali utilizzando simulazioni di N-corpi di materia oscura prodotte utilizzando i pacchetti MUSIC e pycola sul supercomputer Cori al NERSC. In una serie di esperimenti di ridimensionamento a nodo singolo e multi-nodo, il team è stato in grado di dimostrare una formazione parallela ai dati completamente sincrona su 8, 192 di Cori con un'efficienza parallela del 77% e prestazioni sostenute di 3,5 Pflop/s.
"Il nostro obiettivo era dimostrare che TensorFlow può essere eseguito su larga scala su più nodi in modo efficiente, " disse Deborah Bard, un architetto dei big data al NERSC e coautore del documento tecnico. "Per quanto ne sappiamo, questa è la più grande distribuzione mai realizzata di TensorFlow su CPU, e pensiamo che sia il più grande tentativo di eseguire TensorFlow sul maggior numero di nodi CPU."
All'inizio, il team di CosmoFlow ha stabilito tre obiettivi primari per questo progetto:scienza, ottimizzazione e ridimensionamento a nodo singolo. L'obiettivo scientifico era dimostrare che l'apprendimento profondo può essere utilizzato su volumi 3D per apprendere la fisica dell'universo. Il team voleva anche garantire che TensorFlow funzionasse in modo efficiente ed efficace su un singolo nodo di processore Intel Xeon Phi con volumi 3D, che sono comuni nella scienza ma non tanto nell'industria, dove la maggior parte delle applicazioni di deep learning si occupa di set di dati di immagini 2D. E infine, garantire alta efficienza e prestazioni quando viene scalato su migliaia di nodi sul sistema di supercomputer Cori.
Come Joe Curley, Direttore senior dell'organizzazione per la modernizzazione del codice nel Data Center Group di Intel, notato, "La collaborazione con il Big Data Center ha prodotto risultati sorprendenti nell'informatica grazie alla combinazione della tecnologia Intel e degli sforzi di ottimizzazione del software dedicato. Durante il progetto CosmoFlow, abbiamo identificato il quadro, ottimizzazione del kernel e della comunicazione che ha portato a un aumento delle prestazioni di oltre 750 volte per un singolo nodo. Altrettanto impressionante, il team ha risolto i problemi che limitavano la scalabilità delle tecniche di deep learning a 128-256 nodi, per consentire ora all'applicazione CosmoFlow di scalare in modo efficiente fino a 8, 192 nodi del supercomputer Cori al NERSC."
"Siamo entusiasti dei risultati e delle scoperte nelle applicazioni di intelligenza artificiale di questo progetto in collaborazione con NERSC e Intel, " ha detto Per Nyberg, vicepresidente per lo sviluppo del mercato, intelligenza artificiale e cloud presso Cray. "È entusiasmante vedere il team CosmoFlow sfruttare l'esclusiva tecnologia Cray e sfruttare la potenza di un supercomputer Cray per scalare efficacemente i modelli di deep learning. È un ottimo esempio di ciò che molti dei nostri clienti stanno cercando di ottenere dalla convergenza della modellazione tradizionale e simulazione con nuovi algoritmi di deep learning e analytics, tutto su un unico, piattaforma scalabile."
Prabhat, Group Leader of Data &Analytics Services presso NERSC, aggiunto, "Dal mio punto di vista, CosmoFlow è un progetto esemplare per la collaborazione Big Data Center. Abbiamo davvero sfruttato le competenze di varie istituzioni per risolvere un problema scientifico difficile e migliorare il nostro stack di produzione, che può avvantaggiare la più ampia comunità di utenti NERSC."
Oltre a Bard e Prabhat, i coautori del documento SC18 includono Amrita Mathuriya, Lawrence Prati, Lei Shao, Tuomas Karna, John Pennycook, Jason Sewall, Nalini Kumar e Victor Lee di Intel; Peter Mendygral, Diana Moise, Kristyn Maschhoff e Michael Ringenburg di Cray; Siyu He e Shirley Ho del Flatiron Institute; e James Arnemann dell'Università di Berkeley.