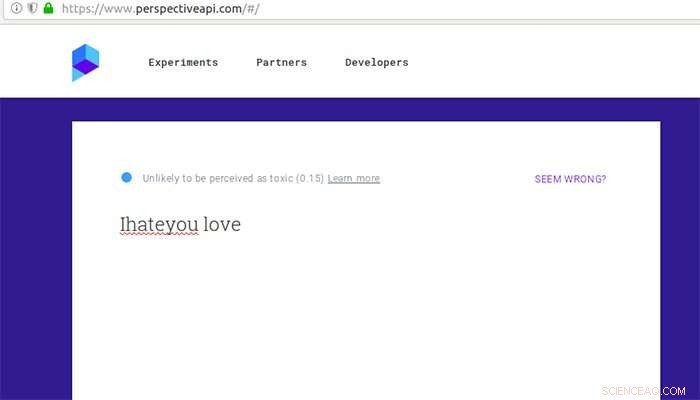
Come Google Perspective valuta un commento altrimenti ritenuto tossico dopo alcuni errori di battitura inseriti e un po' di amore. Credito:Università Aalto
Il testo e i commenti che incitano all'odio sono un problema sempre crescente negli ambienti online, tuttavia, affrontare il problema dilagante si basa sulla capacità di identificare i contenuti tossici. Un nuovo studio del gruppo di ricerca Secure Systems della Aalto University ha scoperto punti deboli in molti rilevatori di apprendimento automatico attualmente utilizzati per riconoscere e tenere a bada l'incitamento all'odio.
Molti popolari social media e piattaforme online utilizzano rilevatori di incitamento all'odio che un team di ricercatori guidati dal professor N. Asokan ha ora dimostrato di essere fragili e facili da ingannare. Una cattiva grammatica e un'ortografia scomoda, intenzionale o meno, potrebbero rendere i commenti tossici sui social media più difficili da individuare per i rilevatori di intelligenza artificiale.
Il team ha messo alla prova sette rilevatori di incitamento all'odio all'avanguardia. Tutti hanno fallito.
Le moderne tecniche di elaborazione del linguaggio naturale (NLP) possono classificare il testo in base a singoli caratteri, parole o frasi. Di fronte a dati testuali che differiscono da quelli utilizzati nella loro formazione, cominciano ad armeggiare.
"Abbiamo inserito errori di battitura, modificato i confini delle parole o aggiunto parole neutre al discorso di odio originale. Rimuovere gli spazi tra le parole era l'attacco più potente, e una combinazione di questi metodi è risultata efficace anche contro il sistema di classificazione dei commenti di Google Prospettiva, "dice Tommi Gröndahl, dottorando alla Aalto University.
Google Perspective classifica la "tossicità" dei commenti utilizzando metodi di analisi del testo. Nel 2017, i ricercatori dell'Università di Washington hanno dimostrato che Google Perspective può essere ingannato introducendo semplici errori di battitura. Gröndahl e i suoi colleghi hanno ora scoperto che Da allora Perspective è diventato resistente a semplici errori di battitura, ma può ancora essere ingannato da altre modifiche come la rimozione di spazi o l'aggiunta di parole innocue come "amore".
Una frase come "Ti odio" è passata al setaccio ed è diventata non odiosa quando è stata modificata in "Ti odio amore".
I ricercatori osservano che in contesti diversi la stessa espressione può essere considerata odiosa o semplicemente offensiva. L'incitamento all'odio è soggettivo e specifico del contesto, che rende le tecniche di analisi del testo insufficienti come soluzioni autonome.
I ricercatori raccomandano di prestare maggiore attenzione alla qualità dei set di dati utilizzati per addestrare i modelli di apprendimento automatico, piuttosto che a perfezionare la progettazione del modello. I risultati indicano che il rilevamento basato sui caratteri potrebbe essere un modo praticabile per migliorare le applicazioni attuali.
Lo studio è stato condotto in collaborazione con ricercatori dell'Università di Padova in Italia. I risultati saranno presentati al workshop ACM AISec in ottobre.
Lo studio fa parte di un progetto in corso chiamato "Deception Detection via Text Analysis in the Secure Systems" presso la Aalto University.