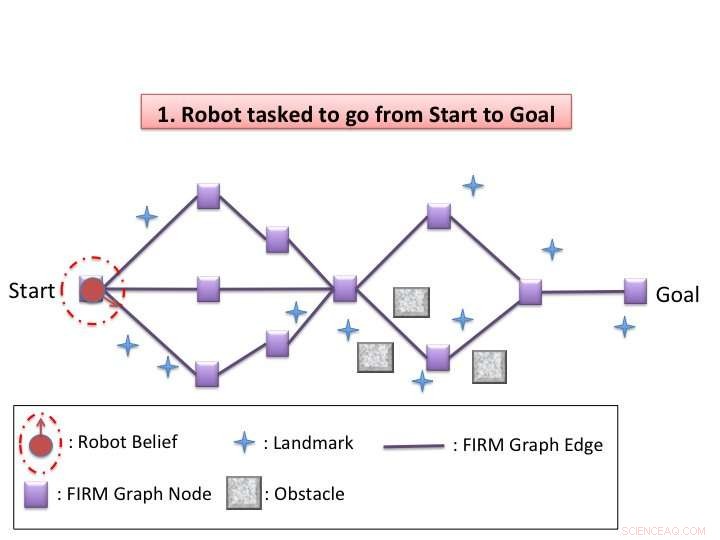
Illustrazione dell'algoritmo. Credito:Agha-mohammadi et al.
Ricercatori del Jet Propulsion Laboratory (JPL) della NASA, Università del Texas A&M, e la Carnegie Mellon University hanno recentemente realizzato un progetto di ricerca volto a consentire capacità di localizzazione e pianificazione simultanee (SLAP) nei robot autonomi. La loro carta, pubblicato in Transazioni IEEE sulla robotica , presenta uno schema di riprogettazione dinamico nello spazio delle credenze, che potrebbe essere particolarmente utile per i robot che operano in condizioni di incertezza, come in ambienti che cambiano.
"I robot che operano nel mondo reale devono affrontare l'incertezza, "Sung Kyun Kim, uno dei ricercatori che hanno condotto lo studio ha detto a TechXplore. "Per esempio, un rover su Marte è quello di navigare verso bersagli scientifici, ma deve anche evitare la collisione con gli ostacoli. Così, sia una localizzazione accurata che una pianificazione del percorso efficiente in termini di costi sono capacità essenziali."
SLAP è un'abilità chiave per i robot autonomi che operano in condizioni di incertezza, permettendo loro di navigare efficacemente negli spazi, evitare gli ostacoli, e pianifica il loro percorso verso le località target. Il processo decisionale sequenziale di un robot in condizioni di incertezza può essere formulato come un POMDP (processo decisionale di Markov parzialmente osservabile), che deve essere continuamente risolto online. Però, garantire che i robot risolvano in modo efficace e accurato i POMDP può essere considerevolmente impegnativo.
"Abbiamo avuto due idee principali per risolvere i problemi SLAP, " Kim ha spiegato. "Uno è quello di utilizzare i controller di feedback per rendere raggiungibile uno stato di credenza. Questo può effettivamente spezzare la "maledizione della storia, ' che ci aiuta a risolvere problemi più grandi. L'altro consiste nel ripianificare e migliorare dinamicamente la decisione in fase di esecuzione, migliorando la qualità e la robustezza della soluzione. La ripianificazione dinamica è particolarmente utile quando ci sono errori di modellazione del sistema, cambiamenti dinamici dell'ambiente, o guasti intermittenti del sensore/attuatore."

Esempio di rover su Marte. Credito:NASA/JPL-Caltech.
Kim e i suoi colleghi hanno ideato uno schema di riprogettazione dinamico nello spazio delle credenze che consente ai robot di navigare efficacemente nello spazio che li circonda in situazioni di incertezza, come in ambienti che cambiano o quando si presentano ostacoli imprevisti. Il loro algoritmo ha due fasi, offline e online.
"Nella fase offline, il nostro algoritmo costruisce un grafico sparso nello spazio delle credenze con un controller di feedback per ciascun nodo e quindi risolve la politica globale grossolana (decidendo quale azione intraprendere allo stato di credenza corrente) sul grafico, " ha detto Kim. "Nella fase online, la riprogettazione dinamica viene condotta ogni volta che lo stato di credenza viene aggiornato. L'algoritmo valuta localmente ogni azione di spostamento su un nodo vicino sul grafico e seleziona quella con il costo minimo. Dopo aver eseguito l'azione selezionata e aver aggiornato la convinzione corrente, ripete il processo di riprogrammazione."
Lo schema ideato da Kim e dai suoi colleghi sfrutta il comportamento dei controllori di feedback nello spazio delle credenze. In altre parole, i controllori di feedback agiscono come un imbuto nello spazio delle credenze, con uno stato di credenza vicino potenzialmente convergente con lo stato di credenza dell'obiettivo di controllo. Questo affronta efficacemente un problema chiave nella risoluzione dei POMPD:la complessità esponenziale nell'orizzonte di pianificazione.
Infatti, una volta che la credenza corrente dell'algoritmo converge con una credenza nota, non c'è bisogno di considerare azioni e osservazioni che portano alla credenza attuale. Questo alla fine porta a una migliore scalabilità, consentendo ai robot di risolvere problemi di navigazione più complessi.
Esempio di rover su Marte. Credito:NASA/JPL-Caltech/MSSS.
"Durante la riprogettazione dinamica, il metodo proposto avvia l'ottimizzazione locale con la politica globale (grossolana), " ha detto Kim. "Questo significa che può prendere una decisione non miope, a differenza di altri pianificatori online con un orizzonte sfuggente finito. In breve, questo metodo può adattarsi ai cambiamenti dinamici nell'ambiente e operare in modo robusto nonostante una perturbazione o errori non modellati, mentre si fanno piani efficienti in termini di costi in senso globale."
Eliminando i passaggi di stabilizzazione non necessari, il metodo ideato da Kim e dai suoi colleghi ha superato la roadmap informativa basata sul feedback (FIRM), una tecnica all'avanguardia per la risoluzione dei POMDP. In futuro, questo schema di ripianificazione dinamica nello spazio delle credenze potrebbe consentire migliori capacità SLAP nei robot che operano con vari gradi di incertezza.
"Ora abbiamo in programma di applicare il nostro metodo ai problemi del mondo reale, " ha detto Kim. "Una possibile applicazione è un prototipo di navigazione e coordinamento di elicottero-rover su Marte per l'esplorazione planetaria, un progetto guidato dal Dr. Ali-akbar Agha-mohammadi al JPL. Un elicottero che sorvola il terreno potrebbe fornire una mappa approssimativa in modo da poter ottenere una politica globale grossolana nella fase offline. Successivamente, un rover si ripianificherebbe dinamicamente nella fase online, per compiere missioni di navigazione sicure ed efficienti in termini di costi."
© 2018 Tech Xplore