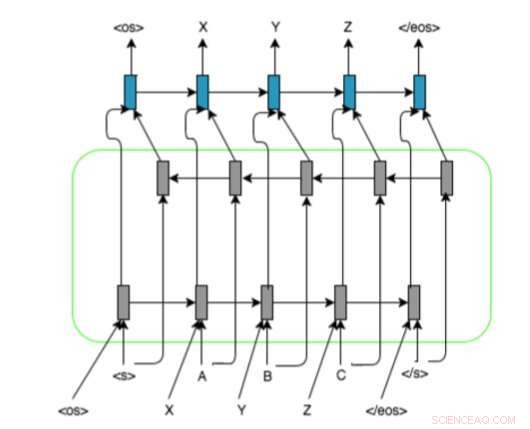
L'architettura del modello basata su RNN dei ricercatori con codificatore-decodificatore LSTM bidirezionale e rappresentazione dell'allineamento sulle sequenze di input. Usano e, , e marcatori per riempire le sequenze di grafemi/fonemi a una lunghezza fissa. Credito:Ngoc Tan Le et al.
Un team di ricercatori dell'Universite du Quebec a Montreal e della Vietnam National University Ho Chi Minh (VNU-HCM) ha recentemente sviluppato un approccio per la traslitterazione automatica basato su reti neurali ricorrenti (RNN). La traslitterazione comporta la traduzione fonetica di parole in una data lingua di partenza (ad esempio il francese) in parole equivalenti in una lingua di destinazione (ad esempio il vietnamita).
Tramite traslitterazione, una singola parola viene trasformata in una parola foneticamente equivalente in un altro sistema di scrittura. Questa trasformazione si basa tipicamente su un ampio insieme di regole definite dai linguisti, che determinano come sono allineati i fonemi, considerando l'origine di una parola e il sistema fonologico della lingua di arrivo.
Negli ultimi anni, i ricercatori hanno sviluppato diversi approcci di deep learning per la traduzione automatica, che si sono rivelate una valida alternativa agli approcci statistici esistenti. Questi risultati promettenti hanno motivato il team di ricercatori dell'Universite du Quebec a Montreal e del VNU-HCM a sviluppare un approccio di deep learning per la traslitterazione automatica.
Il loro approccio utilizza reti neurali ricorrenti (RNN), poiché questi si sono rivelati particolarmente utili per affrontare problemi simili. I ricercatori hanno osservato che la maggior parte dei metodi più avanzati da grafema a fonema si basavano principalmente sull'uso di mappature grafema-fonema, mentre gli RNN non richiedono alcuna informazione di allineamento.
"I modelli da grafico a fonema sono componenti chiave nel riconoscimento vocale automatico e nei sistemi di sintesi vocale, " hanno spiegato i ricercatori nel loro articolo, che è stato pubblicato su ACM Digital Library. "Con coppie linguistiche a bassa risorsa che non dispongono di lessici di pronuncia disponibili e ben sviluppati, i modelli da grafema a fonema sono particolarmente utili. Questi modelli si basano sugli allineamenti iniziali tra la sorgente del grafema e le sequenze bersaglio del fonema".
Nel loro studio, i ricercatori hanno introdotto un nuovo metodo per ottenere la traslitterazione automatica a basse risorse, che utilizza modelli basati su RNN e informazioni di allineamento per le sequenze di input. Data una parola in una data lingua che non è presente nel dizionario di pronuncia bilingue, il loro sistema può prevedere automaticamente la sua rappresentazione fonemica nella lingua di destinazione.
"Ispirato dai metodi di traduzione ricorrenti basati su reti neurali da sequenza a sequenza, la ricerca attuale presenta un approccio che applica una rappresentazione di allineamento per sequenze di input e incorporamenti di sorgenti e target pre-addestrati per superare il problema della traslitterazione per una coppia di lingue a bassa risorsa, " hanno spiegato i ricercatori nel loro articolo.
Questo nuovo approccio combina diverse tecniche di deep learning e reti neurali, compresi encoder-decodificatori, meccanismi di attenzione, rappresentazione dell'allineamento per sequenze di input e incorporamenti di sorgenti e target pre-addestrati. I ricercatori hanno valutato il loro metodo in un compito di traslitterazione che coinvolge coppie linguistiche franco-vietnamite a basse risorse, ottenendo risultati molto promettenti.
"La valutazione e gli esperimenti che coinvolgono francese e vietnamita hanno mostrato che con solo un piccolo dizionario di pronuncia bilingue disponibile per addestrare i modelli di traslitterazione, sono stati ottenuti risultati promettenti, " hanno scritto i ricercatori.
Secondo i ricercatori, il loro studio è stato tra i primi ad analizzare la lingua vietnamita in un compito di traslitterazione utilizzando gli RNN. Il loro metodo ha raggiunto risultati notevoli, superando altri approcci all'avanguardia basati su statistiche e sequenze multiarticolari.
Il nuovo sistema ideato dai ricercatori può apprendere in modo efficace e automatico le regolarità linguistiche da piccoli dizionari di pronuncia bilingue. Sebbene il loro studio lo applicasse specificamente ai compiti di traslitterazione franco-vietnamita, potrebbe anche essere esteso a qualsiasi altra coppia linguistica con poche risorse per la quale è disponibile un dizionario di pronuncia bilingue.
"Nel lavoro futuro, intendiamo testare il nostro approccio proposto con un dizionario di pronuncia bilingue più ampio e studiare altri approcci, come semi-sorvegliato o non-sorvegliato, " I ricercatori hanno scritto nel loro articolo. "Intendiamo anche studiare il trasferimento dell'apprendimento utilizzando altre attività o linguaggi di PNL in contesti con poche risorse".
© 2019 Scienza X Rete