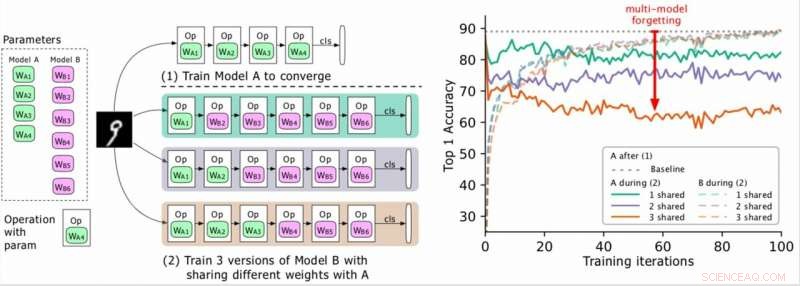
(Sinistra) Due modelli da addestrare (A, B), dove i parametri di A sono in verde e quelli di B in viola, e B condivide alcuni parametri con A (indicati in verde durante la fase 2). I ricercatori prima addestrano A alla convergenza e poi addestrano B. (A destra) Precisione del modello A man mano che l'addestramento di B progredisce. I diversi colori corrispondono a diversi numeri di livelli condivisi. La precisione di A diminuisce drasticamente, soprattutto quando sono condivisi più livelli, e i ricercatori si riferiscono alla goccia (la freccia rossa) come dimenticanza multi-modello. Credito:Benyahia, Yu et al.
Negli ultimi anni, i ricercatori hanno sviluppato reti neurali profonde in grado di svolgere una varietà di compiti, comprese le attività di riconoscimento visivo e di elaborazione del linguaggio naturale (PNL). Sebbene molti di questi modelli abbiano ottenuto risultati notevoli, in genere si comportano bene solo su un compito particolare a causa di ciò che viene definito "dimenticamento catastrofico".
Essenzialmente, Una dimenticanza catastrofica significa che quando un modello che è stato inizialmente addestrato sull'attività A viene successivamente addestrato sull'attività B, le sue prestazioni sul compito A diminuiranno in modo significativo. In un articolo pre-pubblicato su arXiv, i ricercatori di Swisscom e dell'EPFL hanno identificato un nuovo tipo di dimenticanza e hanno proposto un nuovo approccio che potrebbe aiutare a superarlo attraverso una perdita di plasticità del peso statisticamente giustificata.
"Quando abbiamo iniziato a lavorare al nostro progetto, la progettazione automatica di architetture neurali era computazionalmente costosa e irrealizzabile per la maggior parte delle aziende, " Yassine Benyahia e Kaicheng Yu, i principali ricercatori dello studio, detto TechXplore via e-mail. "L'obiettivo originale del nostro studio era identificare nuovi metodi per ridurre questa spesa. Quando il progetto è iniziato, un articolo di Google affermava di aver ridotto drasticamente il tempo e le risorse necessarie per costruire architetture neurali utilizzando un nuovo metodo chiamato condivisione del peso. Ciò ha reso possibile l'autoML per i ricercatori senza enormi cluster di GPU, incoraggiandoci ad approfondire questo argomento."
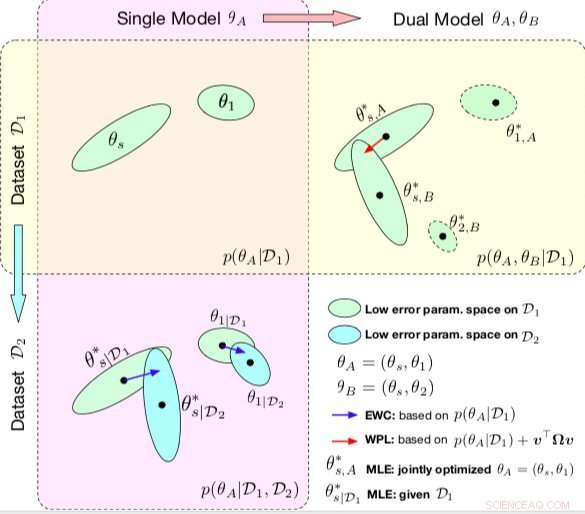
Confronto tra CAE e WPL. Le ellissi in ogni sottotrama rappresentano le regioni dei parametri corrispondenti a un errore basso. (In alto a sinistra) Entrambi i metodi iniziano con un singolo modello, con parametri θA ={θs, 1}, addestrato su un singolo set di dati D1. (In basso a sinistra) EWC regolarizza tutti i parametri in base a p(θA|D1) per addestrare lo stesso modello iniziale su un nuovo set di dati D2. (In alto a destra) Al contrario, WPL utilizza il dataset iniziale D1 e regolarizza solo i parametri condivisi θs basati sia su p(θA|D1) che su v>Ωv, mentre i parametri θ2 possono muoversi liberamente. Credito:Benyahia, Yu et al.
Durante la loro ricerca sui modelli basati su reti neurali, Benyahia, Yu e i loro colleghi hanno notato un problema con la condivisione del peso. Quando hanno addestrato due modelli (ad esempio A e B) in sequenza, le prestazioni del modello A sono diminuite, mentre le prestazioni del modello B sono aumentate, o vice versa. Hanno dimostrato che questo fenomeno, che chiamavano "dimenticanza multimodello, " può ostacolare le prestazioni di diversi approcci auto-mL, inclusa l'efficiente ricerca sull'architettura neurale (ENAS) di Google.
"Ci siamo resi conto che la condivisione del peso stava causando un impatto negativo dei modelli l'uno sull'altro, che stava facendo sì che il processo di ricerca dell'architettura fosse più vicino al casuale, " Benyahia e Yu hanno spiegato. "Avevamo anche le nostre riserve sulla ricerca dell'architettura, dove vengono messi in luce solo i risultati finali e dove non esiste un quadro valido per valutare in modo equo la qualità della ricerca architettonica. Il nostro approccio potrebbe aiutare a risolvere questo problema di dimenticanza, poiché è correlato a un metodo centrale su cui si basano quasi tutti i documenti autoML recenti, e riteniamo che tale impatto sia enorme per la comunità".
Nel loro studio, i ricercatori hanno modellato matematicamente l'oblio multi-modello e hanno derivato una nuova perdita, chiamata perdita di plasticità del peso. Questa perdita potrebbe ridurre sostanzialmente l'oblio multi-modello regolarizzando l'apprendimento dei parametri condivisi di un modello in base alla loro importanza per i modelli precedenti.
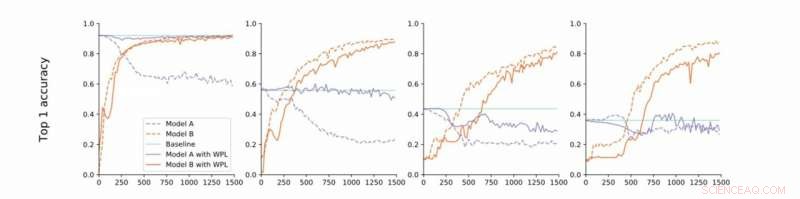
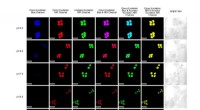
Dalla convergenza stretta a quella libera. I ricercatori conducono esperimenti su MNIST con i modelli A e B con parametri condivisi e riportano l'accuratezza del Modello A prima dell'addestramento del Modello B (baseline, verde) e l'accuratezza dei modelli A e B durante l'addestramento del modello B con (arancione) o senza (blu) WPL. In (a) mostrano i risultati per la convergenza stretta:A è inizialmente addestrato alla convergenza. Quindi rilassano questa ipotesi e allenano A a circa il 55% (b), 43% (c), e il 38% (d) della sua accuratezza ottimale. Il WPL è altamente efficace quando A è addestrato ad almeno il 40% di ottimalità; sotto, le informazioni di Fisher diventano troppo imprecise per fornire pesi di importanza affidabili. Così WPL aiuta a ridurre l'oblio multi-modello, anche quando i pesi non sono ottimali. WPL ha ridotto l'oblio fino al 99,99% per (a) e (b), e fino al 2% per (c). Credito:Benyahia, Yu et al.
"Fondamentalmente, a causa dell'eccessiva parametrizzazione delle reti neurali, la nostra perdita riduce prima i parametri che sono "meno importanti" per la perdita finale, e mantiene inalterate le più importanti, " Benyahia e Yu hanno detto. "Le prestazioni del modello A sono quindi inalterate, mentre le prestazioni del modello B continuano ad aumentare. Su piccoli set di dati, il nostro modello può ridurre l'oblio fino al 99 percento, e sui metodi autoML, fino all'80 per cento nel mezzo dell'allenamento."
In una serie di prove, i ricercatori hanno dimostrato l'efficacia del loro approccio per ridurre l'oblio multi-modello, sia nei casi in cui due modelli vengono addestrati in sequenza sia per la ricerca dell'architettura neurale. I loro risultati suggeriscono che l'aggiunta di plasticità del peso nella ricerca dell'architettura neurale può migliorare significativamente le prestazioni di più modelli sia in attività di PNL che di visione artificiale.
Lo studio condotto da Benyahia, Yu e i loro colleghi fanno luce sulla questione dell'oblio catastrofico, in particolare quello che si verifica quando più modelli vengono addestrati in sequenza. Dopo aver modellato matematicamente questo problema, i ricercatori hanno introdotto una soluzione che potrebbe superarla, o almeno ridurne drasticamente l'impatto.
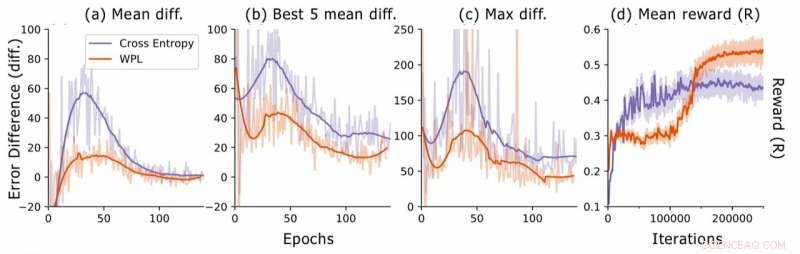
Differenza di errore durante la ricerca dell'architettura neurale. Per ogni architettura, i ricercatori calcolano le differenze di errore RNN err2−err1, dove err1 è l'errore subito dopo aver addestrato questa architettura ed err2 quello dopo che tutte le architetture sono state addestrate nell'epoca corrente. Tracciano (a) la differenza media su tutti i modelli campionati, (b) la differenza media sui 5 modelli con err più basso1, e (c) la differenza massima su tutti i modelli. In (d), tracciano la ricompensa media delle architetture campionate in funzione delle iterazioni di addestramento. Sebbene il WPL inizialmente porti a ricompense inferiori, a causa di un grande peso α nell'equazione (8), riducendo la dimenticanza in seguito consente al controller di campionare architetture migliori, come indicato dal premio più alto nella seconda metà. Credito:Benyahia, Yu et al.
"Nell'oblio multi-modello, il nostro principio guida era pensare per formule e non solo per semplice intuizione o euristica, Benyahia e Yu hanno detto. "Crediamo fermamente che questo 'pensare in formule' possa portare i ricercatori a grandi scoperte. Ecco perché per ulteriori ricerche, miriamo ad applicare questo approccio ad altri campi del machine learning. Inoltre, abbiamo in programma di adattare la nostra perdita ai recenti metodi di autoML all'avanguardia per dimostrare la sua efficacia nel risolvere il problema di condivisione del peso osservato da noi."
© 2019 Scienza X Rete