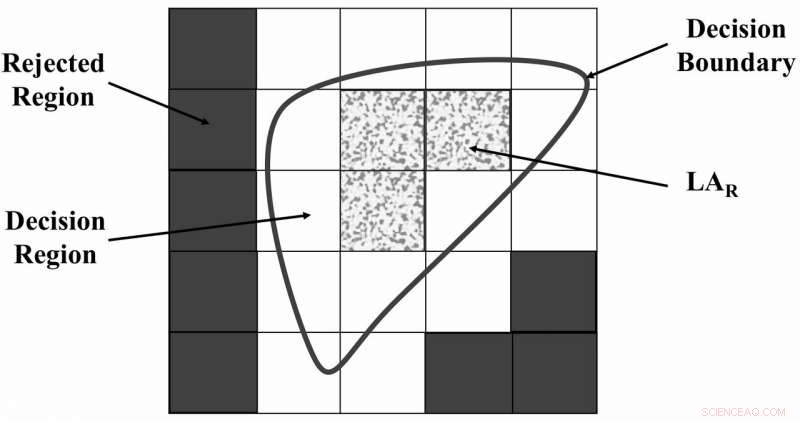
L'universo delle regioni del discorso segregate da FRS. Credito:Zabihimayvan e Doran.
Negli ultimi decenni, gli attacchi di phishing sono diventati sempre più comuni. Questi attacchi consentono agli aggressori di ottenere dati sensibili dell'utente, come password, nomi utente, dettagli della carta di credito, eccetera., inducendo le persone a divulgare informazioni personali. Il tipo più comune di attacco di phishing sono le truffe via e-mail in cui gli utenti sono portati a credere di dover fornire i propri dati a un'entità consolidata o affidabile, mentre sono, infatti, condividere questi dati con qualcun altro.
I professionisti IT hanno sviluppato un vasto numero di strumenti e strategie per rilevare e prevenire attacchi di phishing, molti dei quali sono basati sull'apprendimento automatico. Le prestazioni di tali algoritmi di apprendimento automatico spesso dipendono dalle funzionalità che estraggono dai siti web.
I ricercatori della Wright State University hanno recentemente sviluppato un nuovo metodo per identificare i migliori set di funzionalità per gli algoritmi di rilevamento degli attacchi di phishing. Il loro approccio, delineato in un documento pre-pubblicato su arXiv, potrebbe aiutare a migliorare le prestazioni dei singoli algoritmi di apprendimento automatico per scoprire gli attacchi di phishing.
"Le prestazioni degli algoritmi di rilevamento del phishing che utilizzano l'apprendimento automatico dipendono fortemente dalle caratteristiche di un sito Web considerate dall'algoritmo, inclusa la lunghezza dell'URL della pagina web o se nell'URL sono presenti caratteri speciali come @ e trattino, "Mahdieh Zabihimayvan e Derek Doran, i due ricercatori che hanno condotto lo studio, detto TechXplore via e-mail. "In questo lavoro, volevamo semplificare la creazione di algoritmi di apprendimento automatico per il rilevamento del phishing recuperando automaticamente un set di funzionalità "migliore" per qualsiasi algoritmo di rilevamento del phishing, indipendentemente dal sito web in esame."
Sebbene ora ci siano diversi algoritmi per identificare gli attacchi di phishing, finora, pochissimi studi si sono concentrati sulla determinazione delle caratteristiche più efficaci per rilevare questo particolare tipo di attacco. Nel loro studio, Zabihimayvan e Doran hanno affrontato questa lacuna nella letteratura, cercando di scoprire le caratteristiche più efficaci per questo particolare compito.
"Abbiamo applicato la teoria Fuzzy Rough Set (FRS) come strumento per selezionare le funzionalità più efficaci da tre set di dati di siti Web di phishing benchmark, " Zabihimayvan e Doran hanno affermato. "Le funzionalità selezionate vengono quindi utilizzate per tre algoritmi di apprendimento automatico spesso utilizzati per il rilevamento del phishing".
Per testare l'efficacia e la generalizzabilità del loro approccio di selezione delle caratteristiche FRS, i ricercatori lo hanno utilizzato per addestrare tre classificatori di rilevamento del phishing comunemente impiegati su un set di dati di 14, 000 campioni di siti Web e quindi ne hanno valutato le prestazioni. Le loro valutazioni hanno prodotto risultati molto promettenti, raggiungendo una misura F massima del 95 percento quando il loro metodo di selezione delle caratteristiche è stato applicato a un classificatore di foreste casuali (RM).
"FRS rileva le dipendenze delle funzionalità in base ai dati, " Zabihimayvan e Doran hanno spiegato. "In altre parole, FRS decide come separare un insieme di dati in base ai valori delle caratteristiche e alle etichette utilizzando un limite di decisione e una relazione di somiglianza dichiarata sotto forma di funzioni di appartenenza fuzzy. Le caratteristiche selezionate da FRS sono quelle che possono distinguere maggiormente tra campioni di dati che appartengono a classi diverse."
L'approccio FRS utilizzato da Zabihimayvan e Doran ha selezionato nove caratteristiche universali in tutti i set di dati utilizzati nel loro studio. Utilizzando questo set di funzioni universali, hanno raggiunto una misura F di circa il 93 percento, che è simile a quello ottenuto dai classificatori che utilizzano il loro approccio FRS. Il set di funzionalità universali non contiene funzionalità di servizi di terze parti, quindi questa scoperta suggerisce che si potrebbero potenzialmente rilevare gli attacchi di phishing più velocemente senza richieste da fonti esterne.
"Le funzionalità selezionate automaticamente da FRS forniscono le migliori prestazioni di rilevamento su una serie di classificatori, " Hanno detto Zabihimayvan e Doran. "Troviamo anche una serie di "caratteristiche universali" - quegli aspetti di una pagina web che FRS ha trovato per prevedere meglio se una pagina sta tentando di pescare informazioni, indipendentemente dal tipo di sito Web che la pagina cerca di imitare."
Lo studio condotto da Zabihimayvan e Doran è uno dei primi a fornire informazioni preziose sulle funzionalità più efficaci per rilevare gli attacchi di phishing. Nel futuro, il loro lavoro potrebbe aprire la strada allo sviluppo di tecniche di rilevamento del phishing più efficienti e affidabili, che scoprirebbe questi attacchi più velocemente dei metodi attuali.
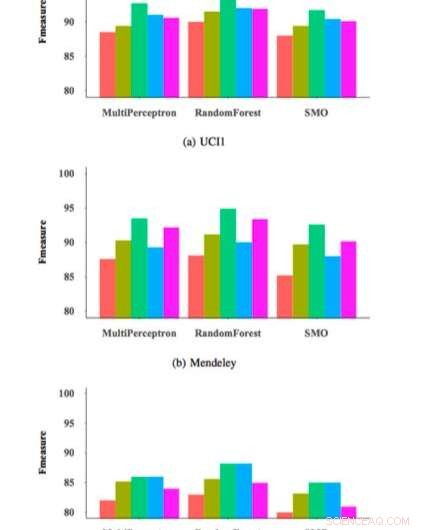
Misura F per diversi classificatori e set di caratteristiche. Credito:Zabihimayvan e Doran.
"Ora speriamo di estendere ulteriormente il nostro studio indagando sulla selezione delle funzionalità per algoritmi di apprendimento automatico più sofisticati, comprese le architetture di deep learning che rilevano automaticamente le "metafunzioni" per migliorare ulteriormente le prestazioni di rilevamento, " hanno affermato Zabihimayvan e Doran. "Abbiamo anche in programma di estendere il nostro framework di selezione delle funzionalità per rilevare le e-mail di phishing".
© 2019 Scienza X Rete














